声网专区
Python 拥有很活跃的社区和丰富的第三方库,Web 框架、爬虫框架、数据分析框架、机器学习框架等,开发者无需重复造轮子,可以用 Python 进行 Web 编程、网络编程,开发多媒体应用,进行数据分析,或实现图像识别等应用。其中图像识别是最热门的应用场景之一,也是与实时音视频契合度最高的应用场景之一。
 1
1
 313
313

音视频实时通讯的应用场景已经随处可见,从“吃鸡”的语音对讲、直播连麦、直播答题组队开黑,再到银行视频开户等。对于开发者来讲,除了关注如何能快速实现不同应用场景重点额音视频通讯,另一个更需要关注的可能就是“低延时”。但是,到底实时音视频传输延时应该如何“低”,才能满足你的应用场景呢?
1
223
语音通话功能、视频通话功能,在一些 IoT 设备上已经不罕见。随着硬件洗能、软件系统和网络连接环境的提升,未来还会有更多类型的设备会开始提供实时音视频功能。
1
265

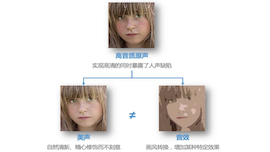
很多人都希望让自己的声音更好听,不论是已经成为主播的人,还是希望成为主播、主持人,或是喜欢参与语聊、互动直播的普通用户。很明显,在歌唱场景、语聊等场景中,用户已经不在满足于被听见、被听清、能互动,以及拥有高清的音质体验。
0
2629
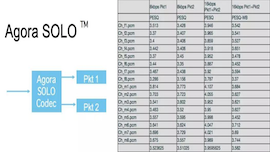
有时,大家对丢包问题会有一些误解。很多人认为随着 4G 的普及和 5G 的建设,是不是丢包问题变得不重要了?我认为并不是这样,因为在现有网络条件下,不论是 server 到 server,还是 sever 到 last mile 都存在着大量的丢包问题。
4
1277
3月23日周六,由 RTC 开发者社区主办的 “RTC Dev Meetup 北京站”如约举行,超过100位求知若渴的开发者参加了活动。来自 LeanCloud、声网 Agora、阿里、美团点评的资深工程师,与他们共同分享了 Flutter 开发中的实践经验。
0
2038

谈起 Opus,对于编解码器有所了解的同学也许会知道,Opus 是由两个编解码器——Silk 和 Celt 融合而成。为什么来自两个组织的编解码器会合二为一,Opus 的性能又如何,本文将简述一下 Opus 的前世今生和部分技术分析。
0
575

随着这几年AI的迅猛发展,我们在图像和视频处理领域里见证了非常多的应用,比如声网Agora引擎里的视频超分辨率技术。对于音频中AI的应用,我们可能经常听说语音合成、语音识别等技术。那在实时音频通话中,AI有什么用武之地呢?本文将简单总结一下AI在实时音频中的应用,本文将不会展开细节,但在文末有部分参考文献,如有需要请自行取阅。
0
259

Agora 的产品均围绕着 RTC(Real-time Communication) 展开,其中最出现的产品便是 Agora RTC SDK。它为厂商提供一个音视频采集、编解码和传输的“工具包”,助力厂商开发自己的 RTC 相关业务的应用。这套工具包包括种类繁多的 API。
0
973

CoderLane 是一款在线实时编程环境, 它的目的是为了解决在线多人实时编程环境困难的问题。通过各种技术手段希望提高在线编程的体验。
0
183
对于使用RTC的人,可以将本文作为一篇快速指南加以参考,了解如何使用TensorFlow来处理WebRTC流。对于使用TensorFlow的人士,则可以将本文作为一份快速简介,了解如何向自己的项目中添加WebRTC。使用WebRTC的人需要对Python比较熟悉。而使用TensorFlow的人则需要熟悉网络交互和一些JavaScript。
0
177

RTM 是一个通用的消息系统,主要是为了解决实时场景下信令的低延迟和高并发问题。在声网所有的后台设计中,分区很重要。区与区之间相对独立,每个区会有跨区传输网络。每个区之间由三个子系统组成,首先是消息核心(Message Core),还有事件中心(Event Center),最后是应用服务(Application Services)。
0
249

著名音乐电台DJ,SoundArio音乐基金会创始人加菲众就说: 几百位歌手的时差、现场收录的和网络技术条件各不相同,所以并没有在线实时协作进行直播的可能,甚至两个人一弹一唱都不可能,因为0.17秒的延时足以抵消全世界顶级音乐人的现场功力。
1
321

根据思科公司今年发布的报告称,预计 2021 年,视频将会成为互联网产品的主要需求,超过80%的互联网流量将会被视频占据。届时,与视频相关的服务与需求将提升约50%,而其中对超高清的需求将提升约30%。同时,互联网对直播和其它实时视频服务的需求将会是目前的15倍。
0
1475

本文拿常见的视频通话的应用,来看看如何基于 Flutter 来开发实现,以及其中会有什么样的困难。
0
710




