


很多人都希望让自己的声音更好听,不论是已经成为主播的人,还是希望成为主播、主持人,或是喜欢参与语聊、互动直播的普通用户。所以你在知乎才会看到很多这样的疑问:
很明显,在歌唱场景、语聊等场景中,用户已经不在满足于被听见、被听清、能互动,以及拥有高清的音质体验。他们有了更进一步的需求,希望不仅能有最佳的音质,还想要让自己的声音变得更动听、更有磁性!
就像我们看高清视频、高清照时,第一感受是震撼,所有细节都能看清了,但皮肤的纹理、瑕疵也会暴露出来。所以会增加红润、磨皮、美颜等,让自己更好看。同样道理,高音质场景下,会使用高采样率(44.1kHz - 48kHz)的软件驱动采集,然后使用音频损伤较小的前处理算法(降噪、回声消除、自动增益等)对信号进行处理,并使用保真性能较好的 Codec 进行编码,使得远端接收到的音频达到高保真效果。这样一来声音细节会更丰富,也更接近真实的听感。但是,声音中的瑕疵也变得更加明显,所以我们需要为声音“加了一层裸妆”,让声音更动听、完美,又不失本色。这就是RTC 场景下的实时美声功能。目前,行业内也能找到一些所谓的“美声”功能,但从技术层面看,它们真的是美声么?
美声≠音效
其实,有些方案将“美声”与“音效”混为了一谈。两者实现的效果和实现方式,不尽相同。
音效指的是通过调节EQ、混响,以及添加效果器等,给人声增加某种特定风格的效果,比如我们在合唱场景中看到的KTV、演唱会、录音棚、流行、R&B、留声机等效果。如果处理之后的声音,有空间感,或者不像你的声音了,那基本上就是经过了音效处理。美声则不仅仅是简单地调节 EQ 和混响,而是把声学、语言学、心理学结合起来调节人声的音调、音色、动态、韵律、空间效果等,实现对人声的整体美化。它是在不改变人声的基础上,对人声进行调节。就像是对人像增加磨皮、红润效果,你并不会去改脸型、大眼。如果改变脸型,在音频中,就相当于变声了。所以经过美声之后,还能听出是你的声音,只是变得更好听了,比如更有磁性和活力。
如果我们将美声与音效,看作是图片处理中的美颜与风格化,看起来会是这样的:
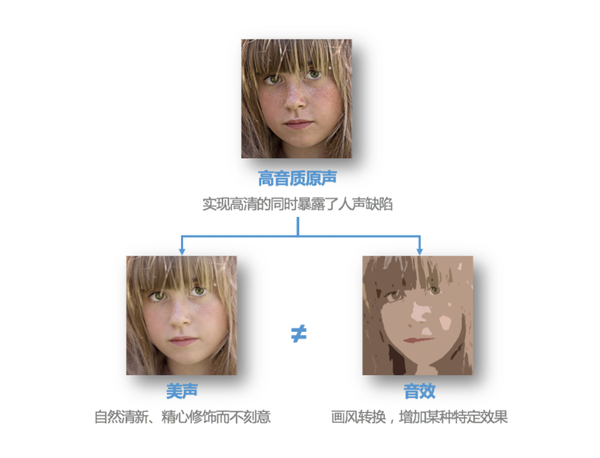
怎样让声音更动听?
想要达到这种效果,通常有三种做法:
- 凭借人的训练。知乎上有这样一条问题“怎么练就一副有磁性的声音”,最高赞回答是:按照一定的方法,训练胸腔共鸣,就可以让声音更动听或更有磁性。
- 主要依靠硬件实现。可以通过专业声卡,来实现很好的体验,但是专业声卡,便宜的需要几千元,贵的要上万元。如果选错了声卡,不仅得不到想要的“美声”效果,还会出现延时,影响实时互动的体验。
- 通过软件的方式实现。对音调、音色、动态、韵律、空间效果等进行调节,达到人声的美化。这种方法不仅用户接入门槛低、成本低,并且能保证实时互动的体验。
显而易见,与其像做一个专业录音棚一样,通过硬件的方式实现一个“声临其境”的线上实时互动场景,或是努力地寻找胸腔共鸣的方法,都不如通过软件的方式更加快捷、低成本。事实上,我们声网在支持了包括在线实时合唱、语音聊天室、互动直播、在线音乐教学等多种高音质实时互动场景的同时,也在研究如何用软件的方法,对用户的声音进行实时美声,并已经实现了完整的实时美声方案,也是目前业界第一家提供实时美声方案的平台。我们接下来讲讲如何定义实时美声,以及实现实时美声的原理。
对一般人而言什么是好声音?
要用软件的方法实现实时的美声,我们就需要先了解,到底什么才是“好声音”?从科学角度,是怎么定义的呢?
对于一般人来讲,“好声音”是一种“难以言喻的感觉”。有的声音很阳光,有的声音温柔甜美,你就是觉得它们声音好听。其实,我们会认为一个声音好听,主要受到声学、语言学、心理学三方面的影响。所以我们可以从语音声波产生的声学原理、空间声波传输的空间混响模型、与心理感知和情绪相关的心理学感知模型、韵律、人群差异的语言学等多个角度出发,对什么是好声音、好声音的数学描述特征指标进行多维分析,总结出不同种类好声音的一般规律。
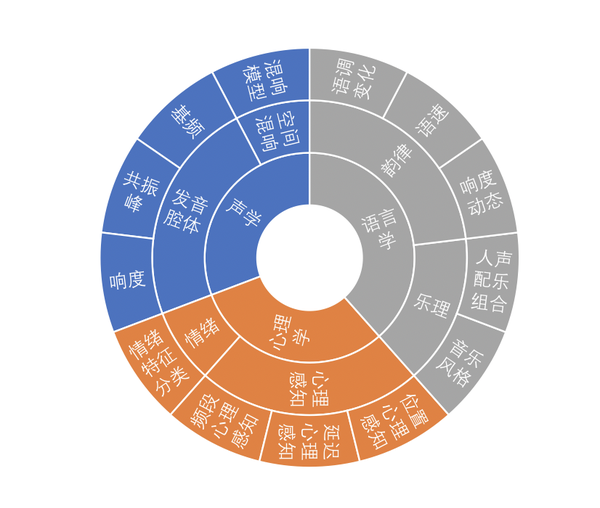
例如,有些人会喜欢富有磁性的男性的声音,以及温柔的女性声音,那这两种声音特征指标就可以这样描述:
- 男性磁性的声音一般在低频和高频能量较高、中频能量较低;
- 女性温柔的声音往往会显得节奏缓慢、pitch变化小、咬字模糊等特性。
以此类推,我们可以用特征指标,来描述更多类型的“好声音”,把这些“难以言喻的感觉”数据化。
如何把“好声音”数据化?
答案是:大数据与 AI 算法。事实上,我们也是基于大数据分析出“男性磁性声音”和“女性温柔的声音”有哪些特征的。
首先,我们已经知道了辨别“好声音”的理论基础:三个维度的多个因素让我们产生了“这个声音好听”的感觉。那么我们可以基于不同场景,如语聊、歌唱等,从性别、年龄、音色的维度确定一些“好声音”目标。
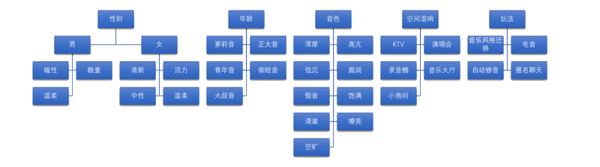
确定目标之后,就像做语音识别需要语料库,做图像识别需要图片库一样。我们接下来要通过线上、线下的方式收集并建立一个“好声音”数据样本库。最后对样本库中语料进行多维分类,并通过数据挖掘将人们的喜好转化为数据与音效设计的目标,用这些数据来驱动音效算法设计。
针对场景与性别设计算法
在设计美声相关算法的时候,我们还需要考虑应用场景。我们将场景主要分为两种:一种是语聊场景,比如聊天房、在线教学等。另一种歌唱场景,比如互动直播、线上 K 歌。
在歌唱场景中,绝大部分情况都会带有伴奏、背景音乐,背景音可以起到部分掩盖人声瑕疵的作用。而在语聊场景下,基本上是纯人声,没有音乐,所以人声的瑕疵不会受到音乐遮掩。我们需要对两种场景的算法设计,以及背景音的融合等方面,做差异化处理。除了场景,还要考虑另一个维度,那就是性别。男声和女声的主要区别是音调的高低不同。男性声带较长、较宽、较厚,所以振动时频率低,发出的音调也低,女性声带较短、较薄、较窄,所以振动时频率高,发出的音调也高。生理条件的先天差别,决定了男女声的发声比例的不同。从审美角度来讲,一般没有人希望男声温婉如玉,女声声如洪钟,所以生理和先入为主的审美决定了男女美声调校方向需要进行差异化处理。语聊场景下,人声瑕疵无遮掩,因此一般单纯的语聊美声处理不用考虑背景融合度、添加混响等问题,着重追求人声的可懂度和耐听度。在歌唱场景中,绝大部分情况都会带有伴奏、背景音乐,背景音可以起到部分掩盖人声瑕疵的作用,而语聊场景基本上是纯人声,瑕疵无遮掩,这样会对算法处理和背景融合等方面提出差异化的需求。
美声要效果,也要实时
接下来就要是实现美声的效果了。为了实现美声效果,往往需要对声音的多个维度进行修改,声网Agora是采用链路式多模组联合算法框架,对人声的音调、音色、韵律、节奏、空间、氛围甚至艺术类型等不同维度进行调整。

与我们在一些唱歌应用中使用的音效、美声等音频处理不同,它们都是离线完成的,不会在意用多长时间处理、耗费多少计算资源。而实时美声都是发生在 RTC 场景下的,对算法在算力、延迟、系统资源消耗方面有较高的要求。所以在设计算法的同时,还需要针对实际数据表现,将算法产生的延时、资源消耗降到最低。
以上就是我们声网Agora 基于自身实践总结出来的“实时美声”的实现方法。而且,我们已经推出业界首个实时美声方案,适用于包括语音通话、互动直播、语聊房、开黑聊天室、K歌房、线上KTV、FM 电台、桌游狼人杀等语聊场景,以及互动直播、K歌房、线上KTV、FM 电台等歌唱场景。通过调用一些 API,即可实现。
那么通过这样一顿操作,实时美声的效果是怎样的呢?
为了让大家可以直观感受美声处理前后的效果,我们也在网站上提供了音频小样,(推荐在 Web 浏览器打开,体验更好):https://www.agora.io/cn/audio-demo
最后,如果正在运营或开发一款包含实时语音功能的应用,并有兴趣在应用中增加美声的功能,可以点击下方访问官网与客服沟通,并获取体验版 SDK 与相应开发文档。

