


一 背景
Elasticsearch技术栈一直是日志、安全、搜索场景的开源首选方案。随着数据规模的海量增长,数据的写入、存储、分析、搜索、排序等场景都会遇到非常大的挑战(存储成本大、写入查询慢等),同时客户降本增效的诉求也越来越高。本文主要解析基于腾讯云ES构建低成本、高性能、高可用日志平台所利用的核心架构和技术。基于腾讯云ES自研存算分离、读写分离、查询/IO并行化、查询裁剪等一套完整的降本增效解决方案。本文将围绕以下几个关键自研技术点进行深入分析:
1)存算分离:自研混合存储架构,实现冷热一体搜索,成本节约50%-80%。
2)读写分离:无依赖、自闭环,读写资源隔离的同时提升5-20倍写入吞吐。
3)查询/IO并行化:自研多级并行查询框架,支持全部查询场景,查询性能提升3~5倍。
4)查询裁剪:索引、分片维度裁剪,叠加二级索引裁剪,查询性能提升10倍+。
腾讯云ES全新技术栈:采用读写分离、存算分离和查询/IO并行化等先进技术,广泛应用于日志场景,实现冷热数据一体化搜索及弹性伸缩能力。全新架构助力内外部客户日志场景实现最高十倍性价比降本能力。
二 架构演进之路
2.1 原生架构
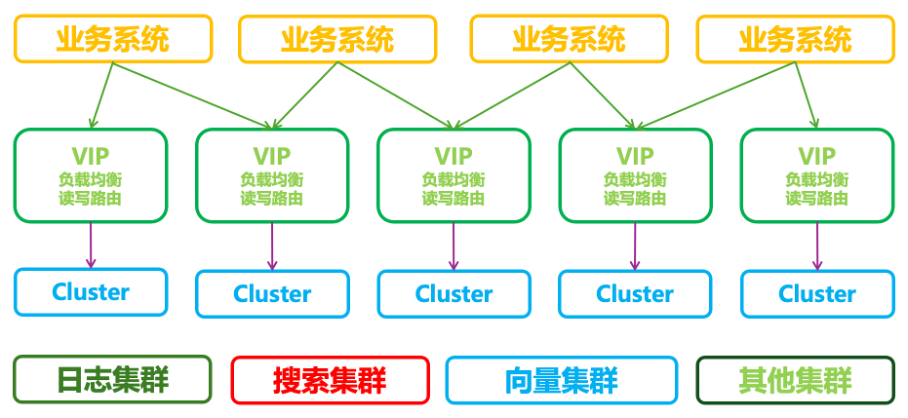
传统架构中,客户一般会申请一个或多个独立的ES集群提供服务,业务系统通过VIP连接到对应的集群中进行访问(可能一个业务会访问多个集群),集群可能按业务划分,分为日志集群、搜索集群、向量集群或者其它集群,此时独立集群的性能和成本在客户可接受的范围内。
原生架构的弊端:
1)各个集群是相互独立的,资源无法得到充分利用。
2)副本冗余写入,从副本上的写入计算开销冗余。
3)副本冗余存储,ES的冗余副本叠加CBS底层3副本,存储成本放大严重。
4)无法弹性扩缩容,需要大量的数据搬迁,数据迁移成本大。
5)存储与计算耦合,数据和计算在同一台节点,资源无法独立弹性扩缩容。
6)分片长尾效应,写入数据时需要将数据分发到索引各个分片,当一个分片执行较慢时就会拖累整体的写入吞吐。
图一
2.2 冷热分离架构
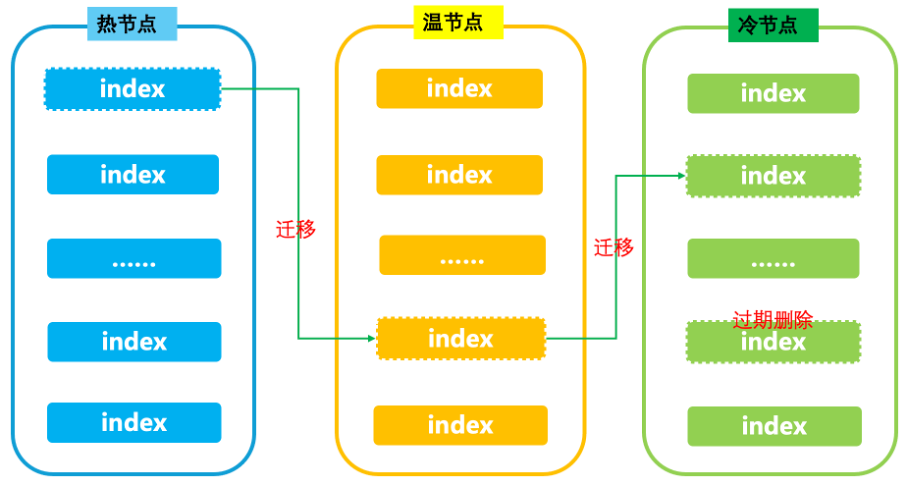
随着业务的不断增长,数据规模越来越大,客户需要对集群进行扩容,扩容后会带来成本上升,尤其是热机器资源成本高昂。根据日志场景的冷热特性,冷热分离架构成为了日志场景的标准方案,热数据频繁读写放到价格昂贵的ssd磁盘上,冷数据查询频率低数据量大,迁移到价格更低的hdd磁盘上进行降本。
冷热分离架构的弊端:
1)原生架构的缺点都存在。
2)需要做大量的数据迁移,迁移会消耗集群大量的资源,影响集群稳定性。
3)原生架构是所有节点都提供写入能力,冷热分离方案只有热节点提供数据的写入能力,特别是针对波峰波谷的场景会存在比较大的资源浪费。
图二
2.3 读写分离架构
冷热分离架构只有少部分热节点提供数据的写入能力,默认情况下客户支撑原来的写入量热节点资源需要和原集群保持不变,另外再申请温节点或冷节点来提供冷数据的存储和查询,这无疑增加了客户的成本,因此在客户降本增效的诉求下,提升ES写入性能成为了重要目标。
ES写入数据时最终是通过Lucene写到内存中,一段时间后refresh成Segment,我们可以在外部(Flink、Spark、独立ES集群等)提前通过Lucene的API构建好Segment,然后转发给具体索引分片,分片收到内存Segment后定时追加到Lucene中,通过Segment内存生成和拷贝,内存merge,Hard-Link,自定义merge policy、定向路由等亮点思想和技术,提升写入吞吐5-20倍。
读写分离分为两种架构模式。第一种是本地读写分离,或单一集群读写分离架构,协调节点实现Segment内存构建并物理拷贝至主从副本。集群可以按读写分区节点部署,也可以混合部署。这种架构适合读写资源隔离、提升写入性能场景。第二种架构是共享集群架构,借助无状态的共享资源池,外部构建内存Segment,客户集群无需写入计算开销,共享集群以海量计算资源换取超高写入性能,适合超高吞吐、波峰波谷、容灾切量等场景。
读写分离架构的弊端:该方案解决了副本冗余写入的问题,提升了写入性能,但没有解决存储成本的问题。
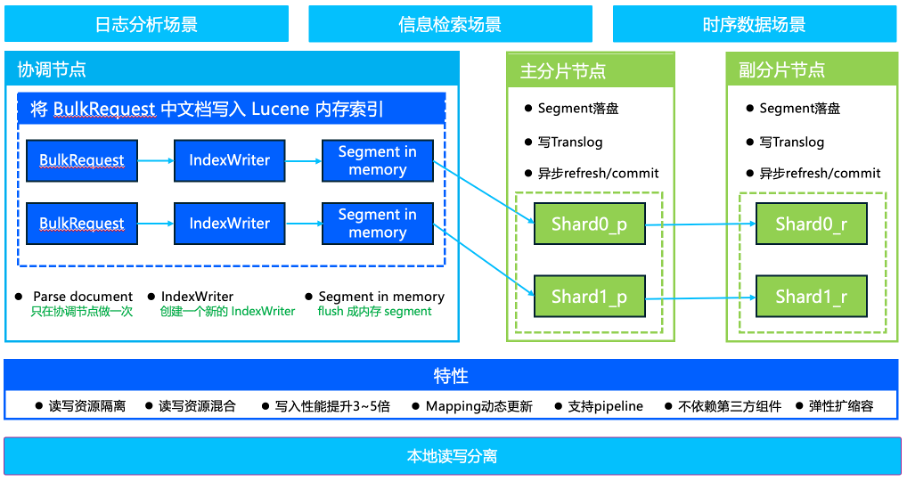
本地读写分离:
特性:本地读写资源隔离、写入性能提升3~5倍、mapping动态更新、支持pipeline、不依赖第三方组件、弹性扩缩容。
图三
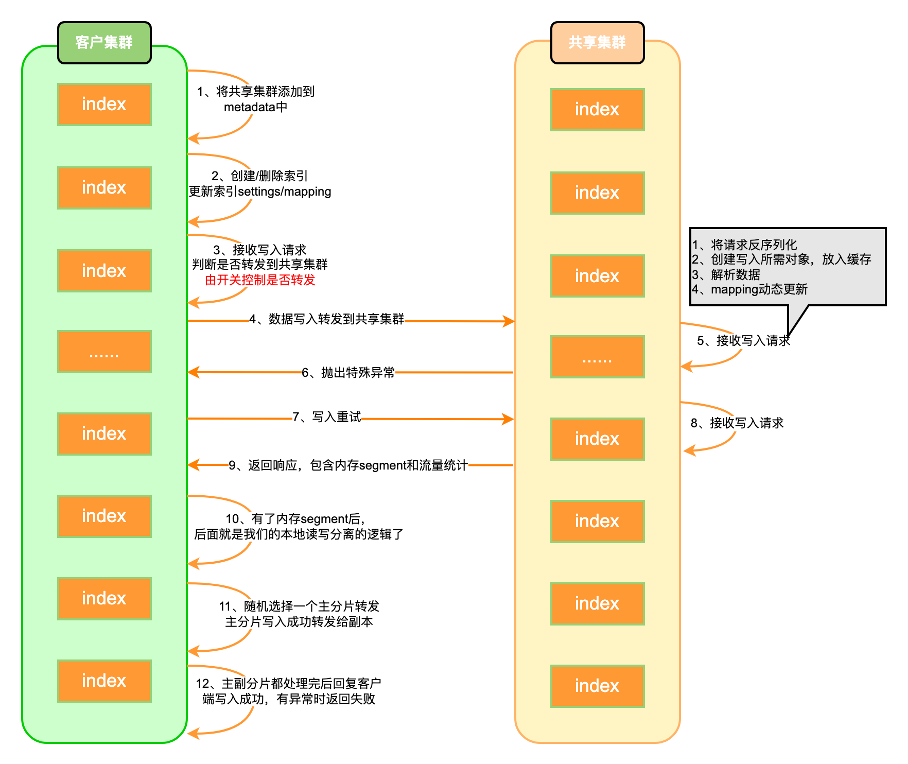
共享读写分离:
特性:读写资源隔离、无状态共享资源池、写入性能提升5~20倍、mapping动态更新、支持pipeline、不依赖第三方组件、弹性扩缩容。
图四
2.4 存算分离架构
读写分离架构的弊端是没有解决数据的存储成本问题,在日志场景海量数据的背景下,存储成本一直是客户的痛点,基于以上方案的弊端,同时考虑到客户降本增效的诉求也越来越高,因此自研存算分离架构优化。
存算分离的核心思路是基于物理复制消除副本冗余计算并确保主从副本分片完全一致,同时采用delta + base架构,本地SSD扛高并发写入并承载Merge计算开销,合并好较大的数据文件实时下沉至海量的对象存储,基于对象存储实现高可用,同时大幅降低存储成本。缓存模块同时对高频访问数据进行缓存,降低对象存储的访问频次。针对对象存储和本地磁盘访问性能差异,采用IO并行化技术结合多级缓存实现冷热一体混合搜索能力。
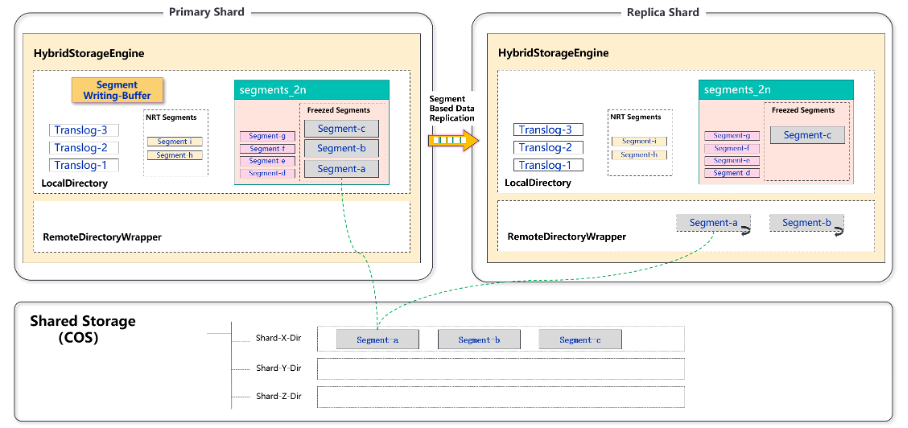
图五
2.5 腾讯云ES日志场景全新技术架构
在全新的技术架构下,我们整合了存算分离、读写分离、查询并行化、自治索引等核心能力,实现全链路降本增效。
基于读写分离、物理复制的能力实现日志场景超高吞吐写入,以及在波峰、高负载场景提供灵活的写入共享计算资源池调度,以实现高性能、高可用。同时实现了读写资源的物理隔离,避免大查询、突发流量的相互影响。
基于对象存储的存算分离架构,热数据实时下沉、按需卸载,降低存储成本。同时基于共享存储实现逻辑副本、弹性伸缩。索引实现跨节点、跨集群挂载,实现一份数据应对检索过滤、分析等不同的使用场景。
基于查询/IO并行化实现了查询并行和IO并行的能力,充分利用空闲资源达到性能倍数级的提升,同时利用 IO 并行化技术弥补对象存储访问延时等。
基于自治索引实现分片、索引多级智能分区托管。用户无需管理繁琐的索引、分片滚动策略、降冷、删除策略等,提升用户易用性。同时基于自治索引和原生二级索引支持索引、分片、Segment 维度多级裁剪。
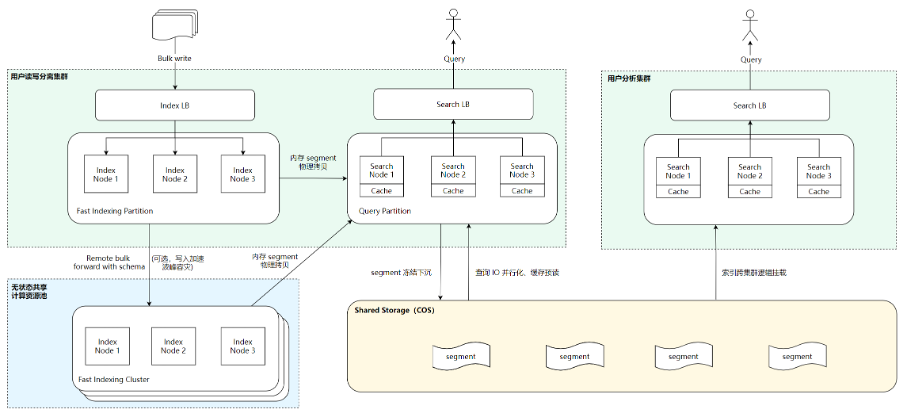
图六
总结一下核心技术点:
存算分离:逻辑副本、存储与计算弹性伸缩,降本 50%~80%。
物理复制:消除冗余副本写入计算开销,写入性能提升 50%。
读写分离:资源隔离提升可用性,内存 Segment 构建与拷贝,写入性能提升 3-5 倍。
无状态共享计算资源池:超大资源池换取额外性能,写入性能提升 5-20 倍。
查询性能优化:IO 并行化、查询裁剪,实现冷热一体搜索。
智能分层:按数据查询频率智能下沉、卸载,提升易用性实现无感知降本。
三 核心技术剖析
3.1 存算分离
3.1.1 设计思想
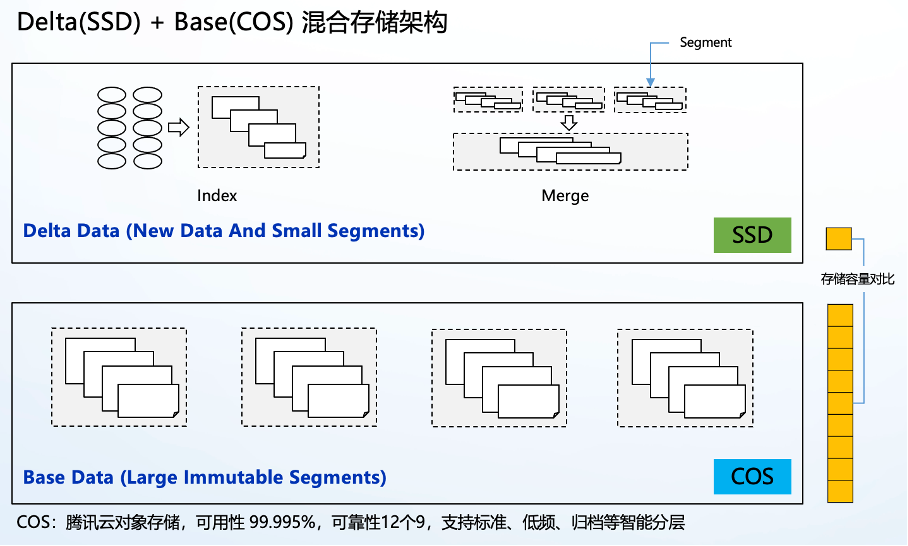
图七
混合存储引擎的整体设计思想是基于典型的 delta + base 架构。其中 delta 部分我们采用 SSD,主要目的为了扛高并发写入,以及小 Segment 的存储及合并;而 base 部分采用对象存储,用于存储大量不可变的大 Segment,一方面其高可用(4个9一个5)、高可靠(12个9)、按量付费、免运维的架构降低了大量运维成本,更重要的是其提供的标准、低频、归档等灵活的低成本存储方案能大幅降低海量日志的存储成本。
3.1.2 设计流程
下面我们细分流程看看整体方案的设计细节。
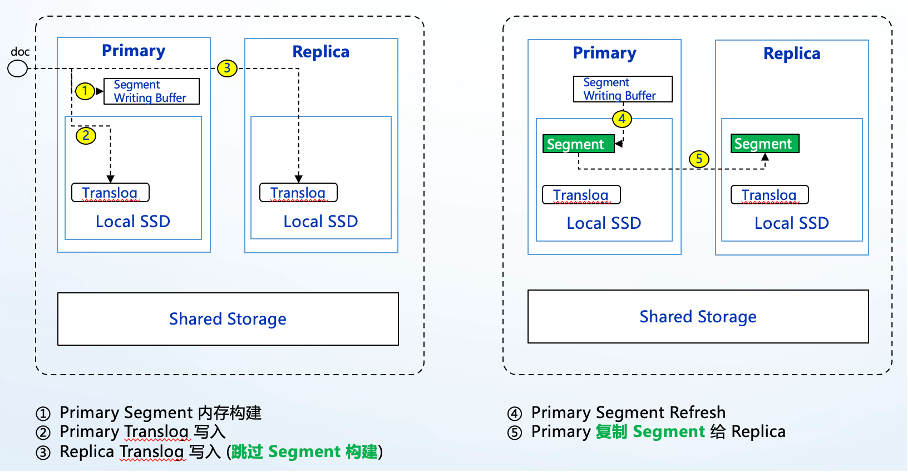
图八
如上图所示,前五个阶段,主要是物理复制的流程,主要目的是为了提升写入性能,确保 primary 和 replica 数据保持完全一致,为后续的数据共享提供基础。
第一个阶段,和原生ES写入逻辑一致,新写入的Document通过Lucene写入到IndexBuffer中。
第二个阶段,Lucene写入完成后,ES会将数据写入到Primary侧的Translog,防止节点down机导致数据丢失。
第三个阶段,主分片写入完成后,转发完整写入请求到Replica,Replica侧只需要将数据写入Translog即可。主分片会通过物理复制将Segment发送给副本。
第四个阶段,IndexBuffer中的数据达到阈值或者触发了refresh周期,将内存中的数据刷新成Segment。
第五个阶段,物理复制模块会检测到有新的Segment生成,启动新任务将新产生的Segment复制给Replica。
图九
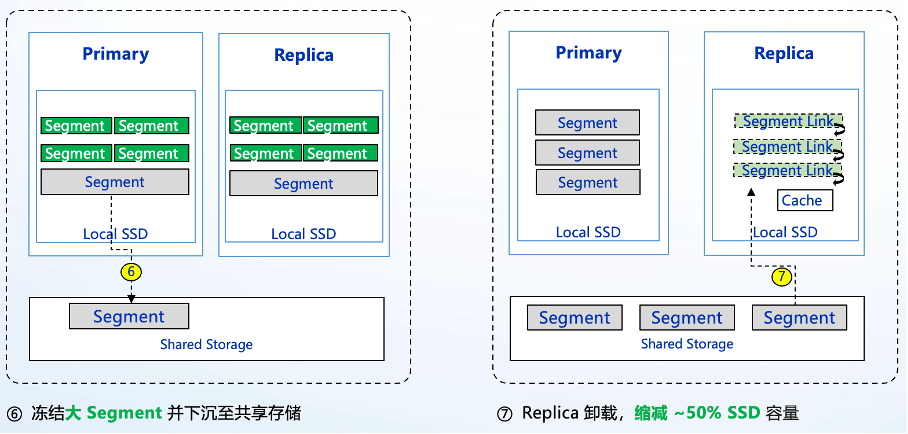
第六个阶段,本地 Segment 通过 merge 产生了较大的 Segment,会被冻结不再参与 merge,并下沉至底层共享存储。注意这个阶段是从热数据就开始的,并不是数据降温后才启动下沉,可以避免数据降温后整体下沉的排队拥塞,当然可以根据用户的需求进行灵活配置。此时,日志场景大量的查询会集中在本地,本地 primary 和 replica 也能很好的抗住读写压力。
第七个阶段,数据的查询频次有所降低。一般情况,本地的 primary 即可满足绝大部分查询性能需求。此时 replica 会从本地卸载,读取会走远端共享存储,同时本地会有缓存机制保存用户常用查询数据提升性能。此时的查询会优先打到 primary。通过卸载本地 replica,我们可以缩减约 50% 的 SSD 容量。

图十
第八个阶段,查询频率大幅缩减。Primary 上只有部分数据或部分 Segment 需要被查询,此时 primary 上的部分文件或 Segment 会先被卸载。同时本地构建缓存体系加速查询。本阶段 SSD 的缩减达到 70% 左右,但仍然能满足业务的查询需求。
第九个阶段,查询几乎没有了,数据处于归档状态。本地的 primary 彻底实现卸载,依靠本地的缓存加速满足极少量的查询需求。本阶段 SSD 的缩减到达 90% 左右。
3.1.3 Segment形态
在整个数据生命周期中,Segment 呈现三种形态:
1)Local Segment:行列存、索引文件等全部在本地,抗住热数据高并发读写请求。
2)Mixed Segment:行列存等数据文件可能卸载,只有部分索引文件在本地,满足少量的查询请求。
3)Remote Segment:行列存、索引文件等全部在远程,本地只有少量元数据文件,满足冷数据低成本归档需求。

图十一
3.1.4 生命周期
图十二
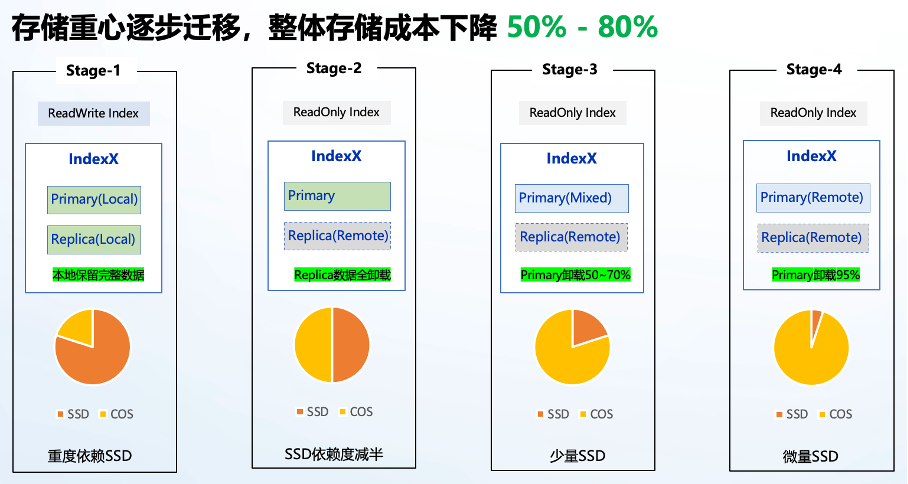
上面是完整的索引生命周期中数据的演变过程,存储重心随着数据逐渐降温过程逐步从 SSD 到对象存储迁移,且用户无明显感知,最终整体存储成本下降 50% - 80%。
3.1.5 方案对比
图十三
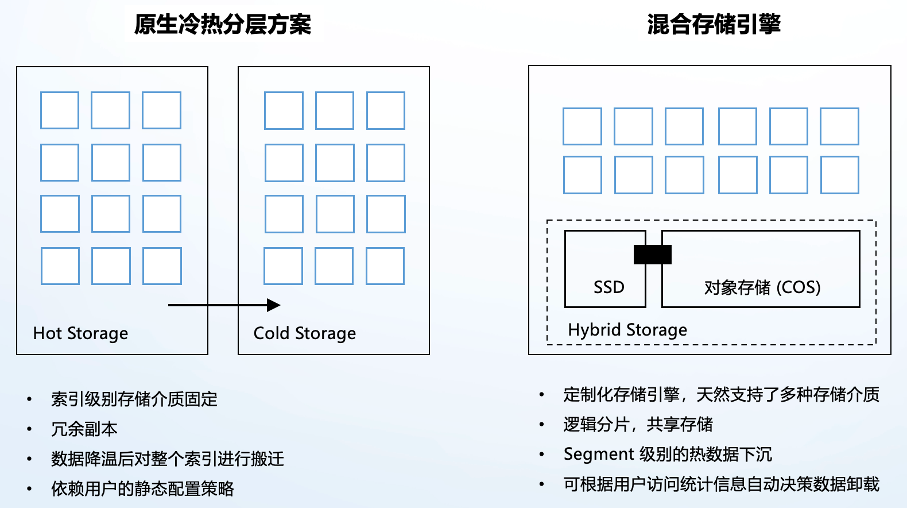
日志场景传统的降本方案一般采用冷热分层。混合存储引擎与冷热分层主要的区别包括:
1)存储架构差异
传统冷热分层索引级别存储介质固定。
混合存储 SSD 和对象存储是一个整体,数据可以双向局部流通。
2)副本差异
传统冷热分层存在冗余副本。
混合存储底层采用共享存储,上层分片最终形态为逻辑分片,消除了云原生环境下的冗余副本。
3)数据搬迁差异
传统冷热分层数据降温后索引需要整体搬迁。
混合存储支持在热数据阶段 Segment 级别的数据下沉。
4)配置策略差异
传统冷热分层依赖用户的静态配置策略,灵活性低、运维成本高。
混合存储除了支持用户配置外,还可根据用户访问统计信息自动决策数据下沉、卸载时机,实现数据智能分层。
3.2 读写分离
3.2.1 设计思想
ES写入数据时最终是通过Lucene写入到内存中,一段时间后refresh成Segment,我们可以在外部 (Flink、Spark、独立ES集群等) 提前通过Lucene的API创建好Segment发送给ES,ES接收到内存Segment后转发到索引分片对应的数据节点中,索引分片直接追加到Lucene中即可,因为ES的refresh(Lucened的flush)也是类似的原理。
3.2.2 本地读写分离流程图
图十四
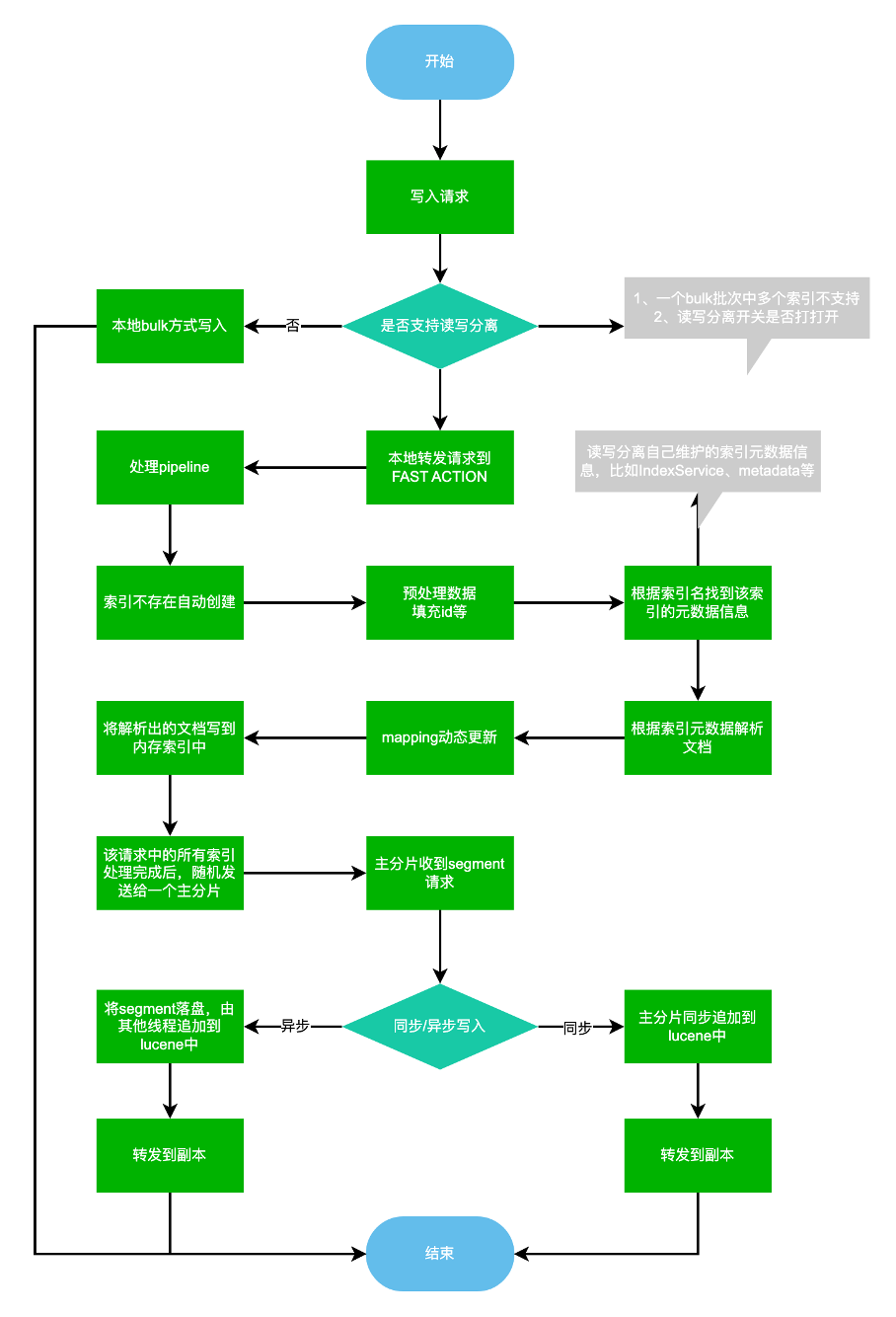
1)创建集群时设置部分节点为专属协调节点,数据节点也可以充当协调节点(只提升写入性能不关心资源隔离场景)。
2)创建索引,索引分片默认会分配到数据节点中,此时专属协调节点的元数据中已经有了索引的settings和mappings信息(读写分离自动维护)。
3)复用bulk接口,客户在发送写入请求时不需要任何更改。
4)客户在发送写入请求之前需要保证每一个批次bulk大小不能太小,和官方bulk接口保持一致最好,每一个批次在5~15mb。
5)当ES协调节点收到写入请求后,在协调节点内存中构建Segment。
6)协调节点在内存中构建完后转发给相应的主分片,追加到Lucene中。
7)主分片收到请求后可根据索引配置(同步/异步)选择直接追加到Lucene中或者先落盘,主分片追加完成后转发给副本分片。
8)副本分片收到请求后可根据索引配置(同步/异步)选择直接追加到Lucene中或者先落盘,副本分片追加完成后返回响应给主分片。
9)主分片收到副本返回的响应后,返回响应给协调节点,协调节点返回给客户端。
3.2.3 共享读写分离流程图
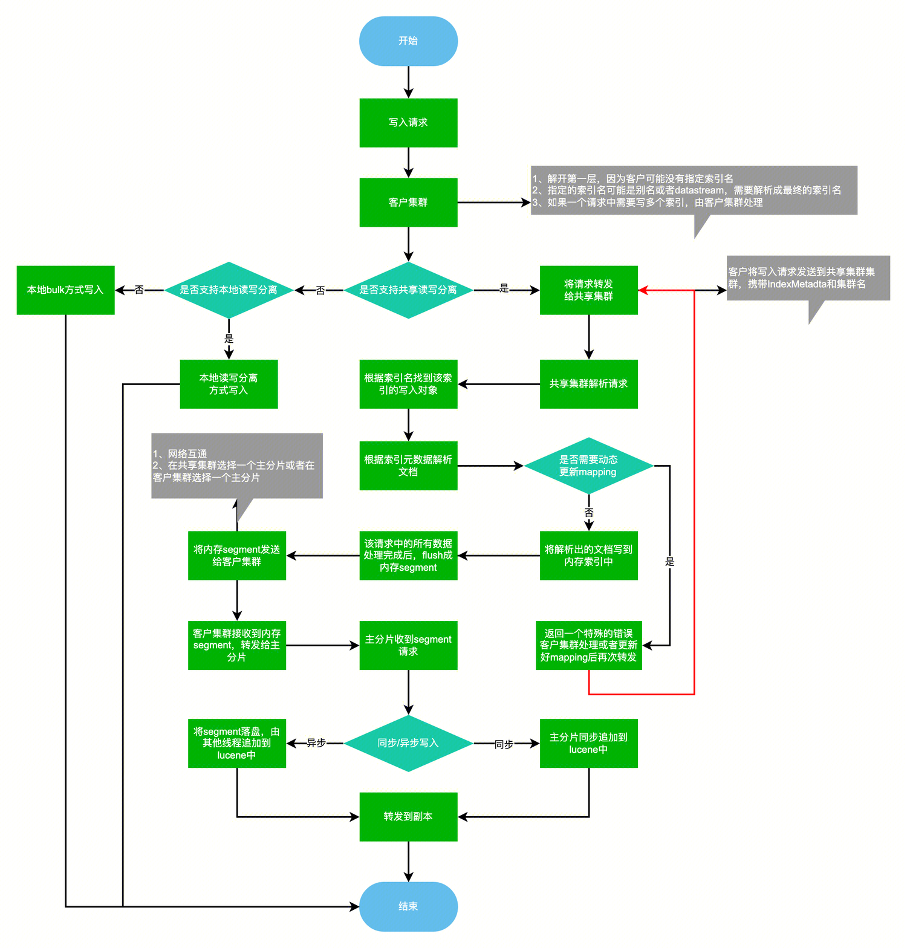
图十五
1)创建一个大的ES共享集群,不需要存储数据和translog,因此不需要数据盘,只需要少量的系统盘,共享集群可能也会有多个,做一个大的资源池,当某个集群资源使用率较高时部分流量分发到其他集群。
2)客户创建集群时可以选择是否使用共享集群的方式。
3)当客户集群选择使用共享集群,且索引打开共享读写分离开关时,此时可以将写入请求转发给共享集群,客户集群转发写入请求给共享集群时,需要携带集群名,IndexMetadta等。
4)共享集群根据传递过来的IndexMetadata,通过equals方法检查缓存中是否已经缓存了所需写入对象,如果无需要创建相应的写入对象,比如IndexService,然后放入缓存中,如果找到了说明客户索引的mapping和settings并无更改,则直接使用。
5)共享集群解析数据,并在内存中构建完Segment后,返回response给客户集群(response中携带内存segment和流量统计信息),客户集群随机选择一个主分片并转发请求。
6)客户集群主分片收到请求后可根据索引配置(同步/异步)选择直接追加到lucene中或者先落盘,主分片追加完成后转发给副本分片。
7)副本分片收到请求后可根据索引配置(同步/异步)选择直接追加到lucene中或者先落盘,副本分片追加完成后返回响应给主分片。
8)主分片收到副本返回的响应后,返回响应给协调节点,协调节点返回给客户端。
3.2.4 赋能性能提升
1)定向路由:一批数据只发送给一个分片
减少网络转发和请求调用。
每个分片单位时间内处理的数据会增多,提升吞吐量。
减少cpu的占用(默认情况下,一个bulk请求发送给所有 分片,也就是说同样的数据量原来需要占用主分片个数的核数,现在只需要一个核)。
2)数据在协调节点或者共享集群构建
没有了锁的争抢(比如permit、merge限速的锁、version map等等)。
数据解析只有一次,主分片和副本不再需要解析,默认方式主分片和副本都需要解析。
3)translog:写translog更轻量,只需要写入临时目录名称即可,默认方式需要把完整的数据写入到translog中。
4)批量追加顺序写:Segment批量追加到Lucene中,追加到Lucene中时只需要读取这些Segment的Segments-N 和 si 文件即可,性能高、吞吐量大。
5)内存Segment:基于内存传递,共享集群不需要落盘重复读取;主分片和副本也是异步IO落盘,落盘即返回响应。
6)磁盘硬链接:向Lucene中追加Segments时使用了硬链接,避免了磁盘数据copy,只需要更改文件的inode即可。
7)逻辑推理:
假设客户集群只有5台32核机器,共享集群20台32核机器,索引有20个分片1个副本,那么客户集群每台节点需要分配20*2/5=8个分片,共享集群每台需要分配20/20=1个分片(副本不写),客户集群的每个分片可以分到的核数是32/8=4核,共享集群是32/1=32核,因此,不考虑其他索引的影响,最佳状态下,默认写入性能也会提升32/4=8倍,如果共享集群更多节点更多核数,性能会增加更多,而且在加上本地读写分离的特性加持,性能在此基础上还会再乘以3~5。
3.3 查询/IO并行化
3.3.1 设计思想
ES查询模型是将查询请求拆分成分片级的子请求转发给各个分片执行,最后在协调节点合并各个分片的结果,在每个分片内部有多个Segment,默认情况下ES执行分片级查询时是单线程串行处理每个Segment的,由于分片内的Segment是独立的,是不是可以再拆分几个子请求,由多个线程并行处理,在数据节点合并多个线程的结果后再返回给协调节点,在数据节点合并每个线程的结果跟在协调节点合并每个分片的结果道理是相同的。
该方案意在压榨空闲cpu资源,将ES的单个分片级请求拆分成3~5个子请求并行处理该分片下的Segment或者docs,根据docs或者Segment切分,每个线程只处理一部分docs或者Segment,在数据节点合并每个线程的结果后再返回给协调节点,协调节点合并各个分片的结果返回给客户端,从而达到性能倍数级的提升。
3.3.2 耗时分析
通过profile接口查看某查询各个阶段的耗时,通过下图可以看出该查询score和next_doc等阶段耗时偏大。
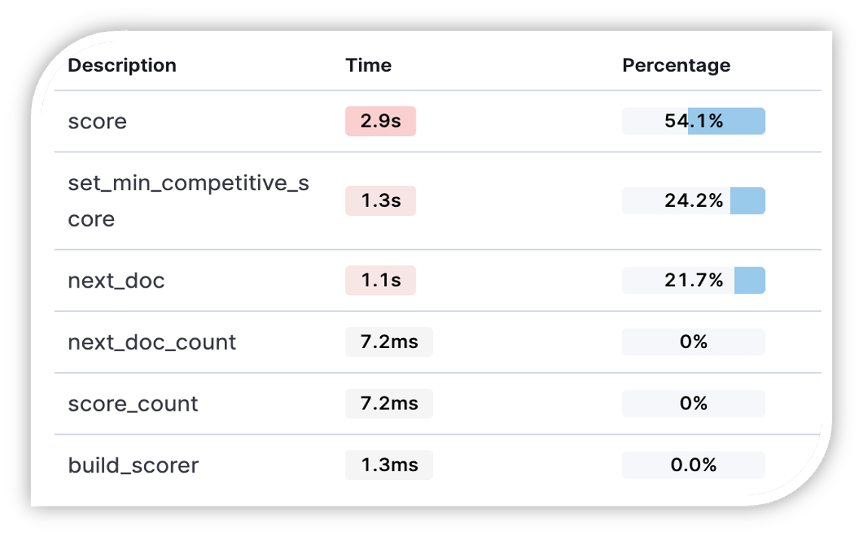
图十六
以score阶段为例:score阶段表示打分的耗时,这个是该分片所有Segment中所有匹配的文档的打分的累加值,假设有3个Segment,每个Segment的打分耗时如下,默认情况下是单线程串行处理每个Segment,score阶段整体耗时=1000+1000+900 = 2.9s。

图十七
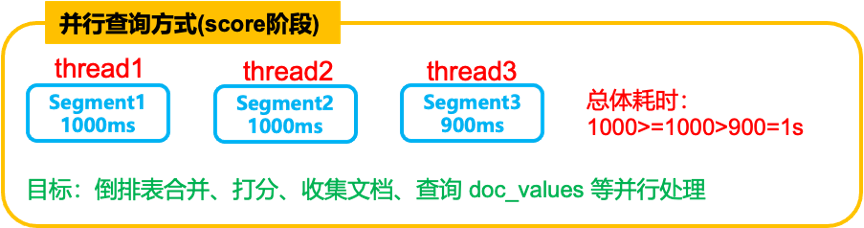
假设让3个线程并行处理这3个Segment,由于是3个线程同时处理,因此整体耗时等于耗时最长的那个线程的执行时间,score阶段整体耗时=1000>=1000>900 = 1s,理论上比2.9s快3倍。
图十八
3.3.3 切分逻辑与算法
3.3.3.1 按照Segments切分
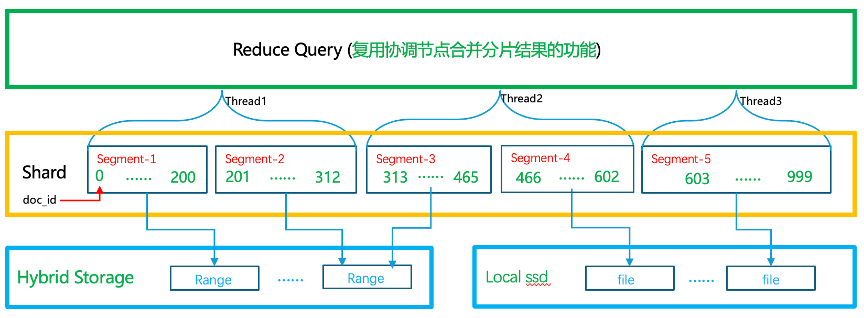
图十九
当数据节点接收到某个分片查询时,根据并行化设置的并发度切分Segments或者docs并行执行查询,Segment的切分逻辑如下:
1)判断查询类型,是aggs、range、sort或其他类型,对于按照date/number类型的 range 的查询,Segment 的 build_scorer 阶段的耗时比较长,此类型查询方式切分 Segment 最好,防止一个 Segment 被多个线程处理。
2)获取该分片总共有多少Segments,因为需要保证每个线程尽可能平均处理相同个数的 Segment。
3)获取设置的并发度。
4)根据平均-剩余-再平均的算法保证每个线程处理相同个数的 Segment,如果Segments个数不能被并发度整除,该算法也可以保证最后启动的线程处理少一些Segment(因为前面的线程先启动先处理,最后启动的线程不能成为长尾)。
5)大小Segment组合:较大的Segment处理耗时理论上较长,因此为了避免某个线程处理的都是大Segments,其他线程处理的都是偏小的Segments,这种情况下处理大Segments的线程就会成为长尾,优化效果不明显。在切分时将大小Segment组合起来,保证每个线程处理相同个数的Segments的同时确保每个线程处理差不多的数据量。
6)Segment裁剪:该分片真正执行并行查询时会在查询流程中裁剪掉不相关的Segments,确保每个线程只处理分配给他的Segments。
3.3.3.2 按照Doc切分
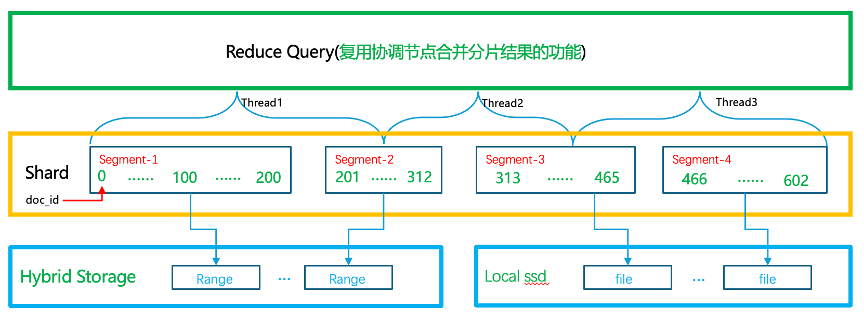
图二十
当数据节点接收到某个分片查询时,根据并行化设置的并发度切分Segments或者docs并行执行查询,docs的切分逻辑如下:
1)判断查询类型,是aggs、range、sort或其他类型,所有查询都适合切分 Segment 吗?对于聚合和排序这种查询 doc_values 的场景,切分文档性能更好,因为可以保证每个线程处理差不多的文档数量,如果按照 Segment切分,Segment 有大有小,大的 Segment 处理时间长就会成为长尾。
2)获取该分片总共有多少docs,因为需要保证每个线程尽可能平均处理相同个数的文档。
3)获取设置的并发度。
4)根据平均值+1的算法保证每个线程处理相同个数的 文档,该算法也可以保证最后启动的线程处理少一些docs(因为前面的线程先启动先处理,最后启动的线程不能成为长尾)。
5)边界归并:当某个线程需要处理某个Segment超过 2/3 的docs时,此时会将该Segment全部交给该线程处理,因为如果将剩余的 1/3 的数据交给另外一个线程处理,此时另外一个线程就需要执行该Segment的 query_rewrite、create_weight、build_score等阶段,执行这么多阶段只处理一小部分文档不划算。
6)Segment裁剪:该分片真正执行并行查询时会在查询流程中裁剪掉不相关的Segments,确保每个线程只处理该线程文档范围内对应的Segments。
7)倒排链表跳转:可能某个线程只处理该Segment一部分文档,因此当合并倒排链表时需要advance到该线程处理的文档范围内的最小值,到文档范围内的最大值时提前退出。
四 性能测评
使用esrally压测http_logs和geonames数据性能,各对比项释义如下:
50th percentile latency: 50分位耗时
90th percentile latency: 90分位耗时
99th percentile latency: 99分位耗时
100th percentile latency: 100分位耗时
Min Throughput: 最小吞吐量
Mean Throughput: 平均吞吐量
Median Throughput: 吞吐量中值
Max Throughput: 最大吞吐量
4.1 存算分离
压测环境:3台标准型SA2 16核64G, 1500GB SSD云硬盘 x 1
压测数据:http_logs
压测工具:esrally
4.1.1 存算分离与可搜索快照查询性能对比
下图中,第三列数据是可搜索快照的查询耗时以及吞吐量,第四列数据是存算分离的查询耗时以及吞吐量,第五列则是两者的差值。从数据可以看出,自研云原生存算分离架构查询性能大幅领先可搜索快照。
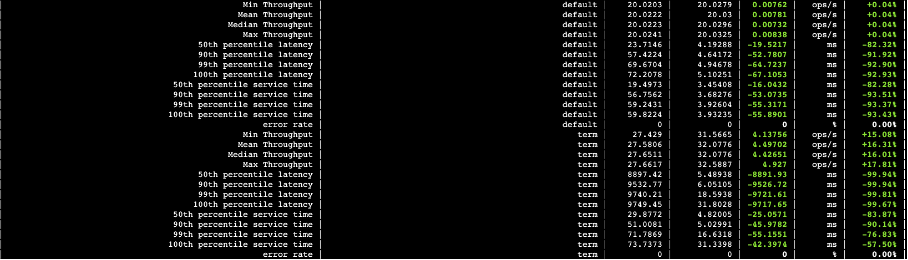
图二十一
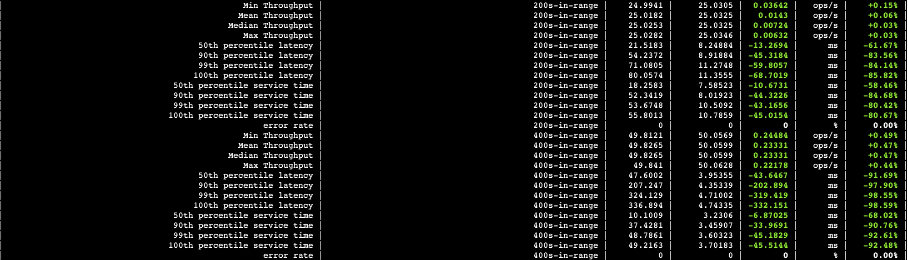
图二十二
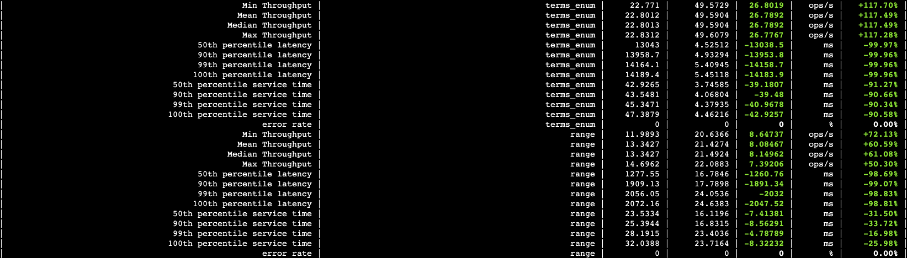
图二十三
4.1.2 本地盘与存算分离查询性能对比
下图中,第三列数据是本地盘的,第四列数据则是存算分离的,第五列则是两者的差值。
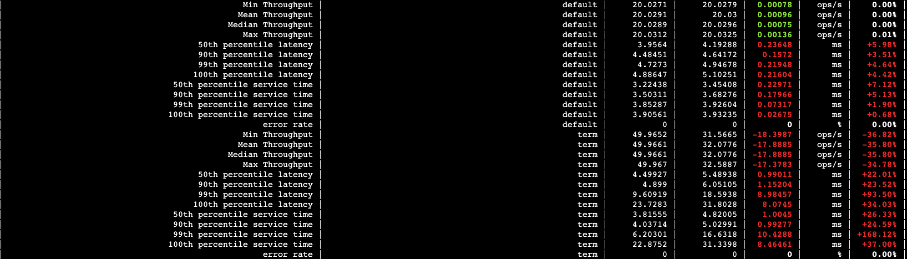
图二十四
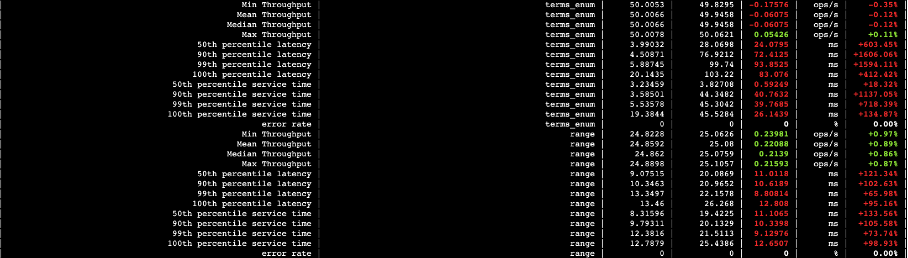
图二十五
4.1.3 本地盘与可搜索快照查询性能对比如下
下图中,第三列数据是本地盘的,第四列数据是可搜索快照的,第五列则是两者的差值。
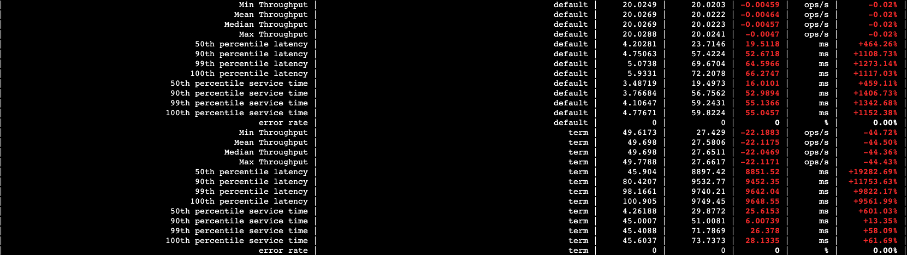
图二十六
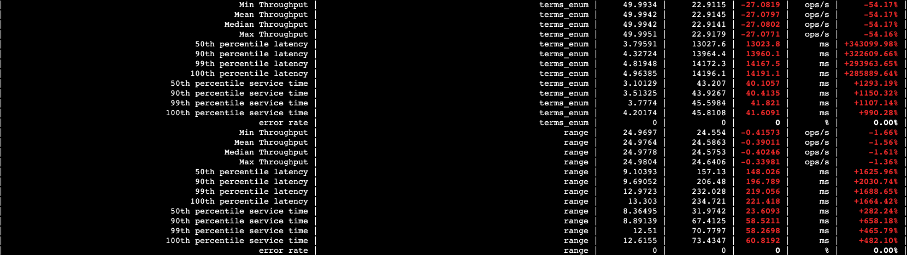
图二十七
4.1.4 总结
从和本地盘的查询性能损耗可以看出,可搜索快照的查询性能损失太大,自研云原生存算分离相较于本地盘的查询性能损耗,仍在可接受的范围内。增加并行化压测后大部分场景比本地还要快2~3倍。(查询延时单位:ms)
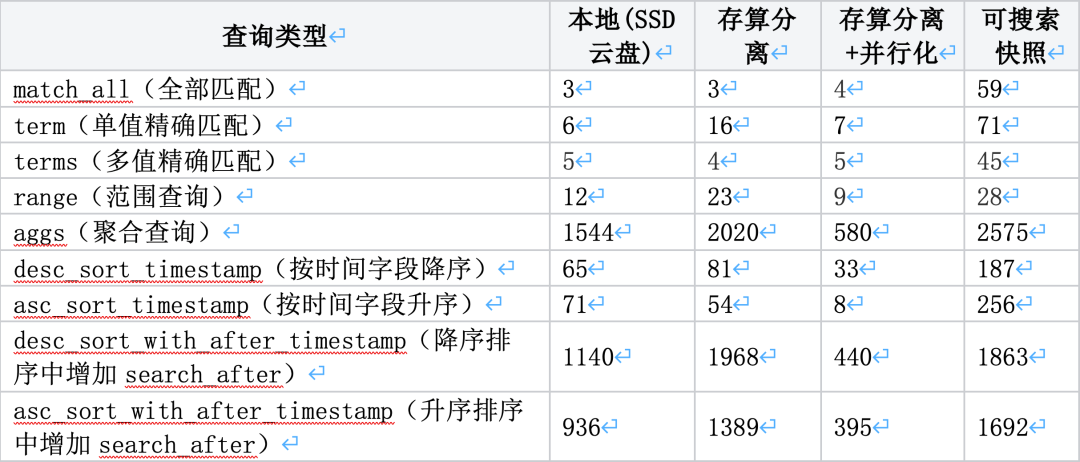
图二十八
4.2 读写分离
压测环境:3台标准型SA2 16核64G, 1500GB SSD云硬盘 x 1
压测数据:随机生成
压测工具:编写代码消费kafka
4.2.1 ES默认写入性能
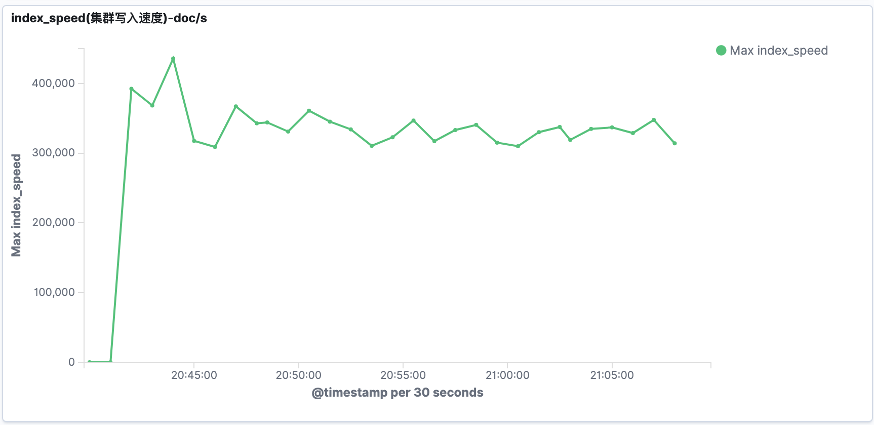
图二十九
4.2.2 本地读写分离写入性能
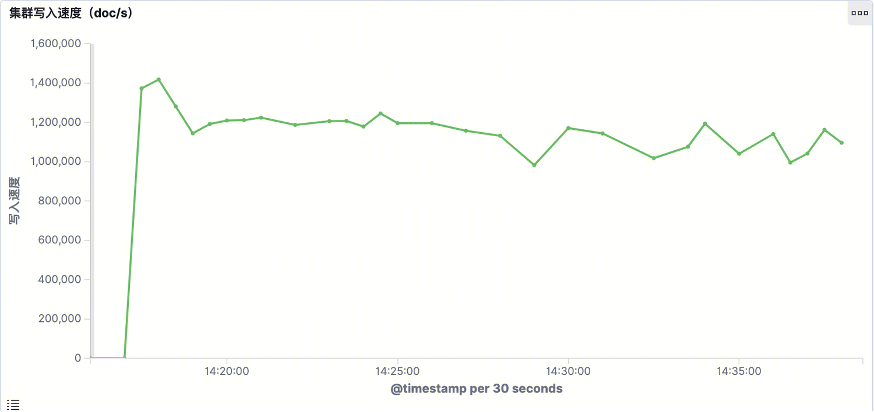
图三十
4.2.3 共享读写分离写入性能
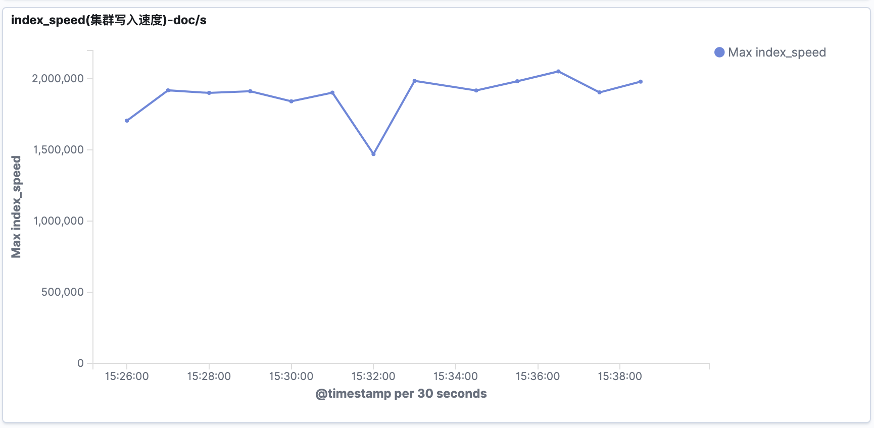
图三十一
4.2.4 总结
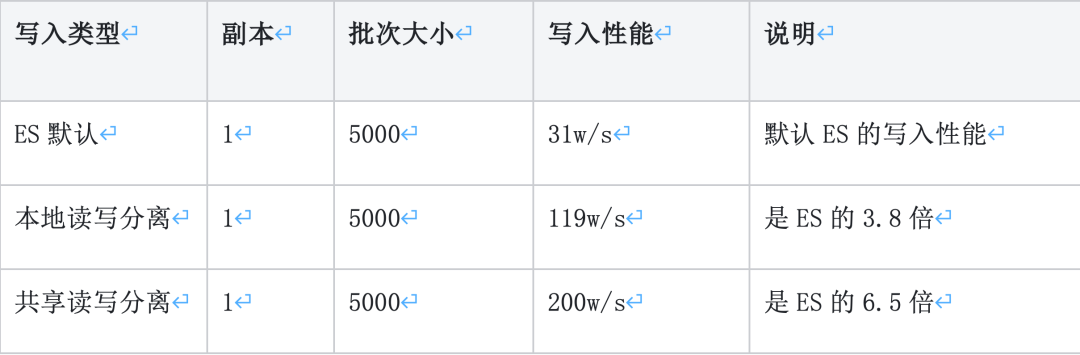
图三十二
4.3 IO并行化
压测环境:3台标准型SA2 16核64G, 1500GB SSD云硬盘 x 1
压测数据:geonames
压测工具:esrally
压测背景:此处IO并行化并发度设置为3
4.3.1 压测明细
下面的图中,第三列数据是关闭并行化的查询耗时以及吞吐量,第四列打开并行化的查询耗时以及吞吐量,第五列则是两者的差值。
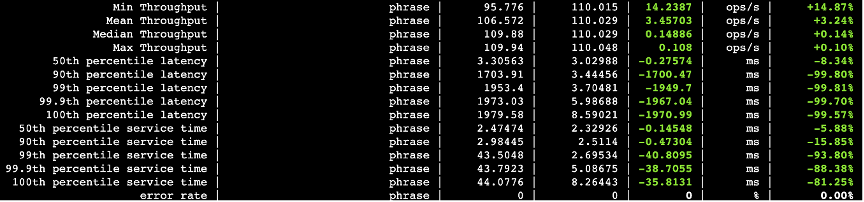
图三十三
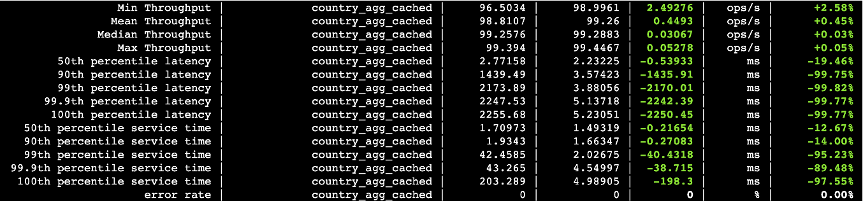
图三十四
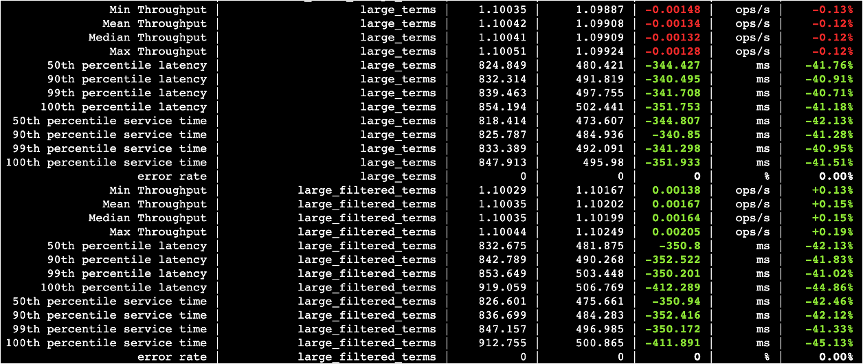
图三十五
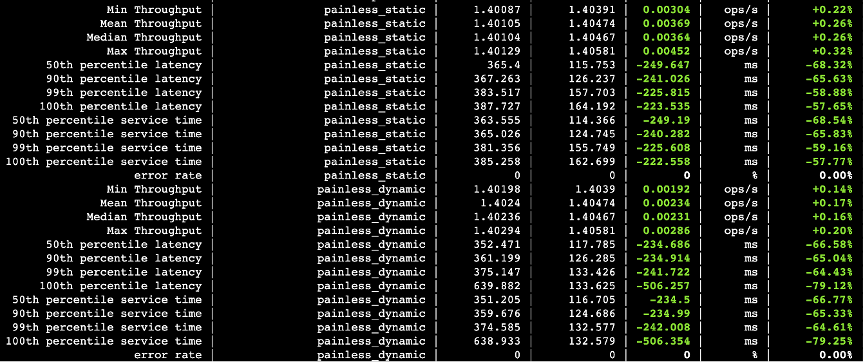
图三十六
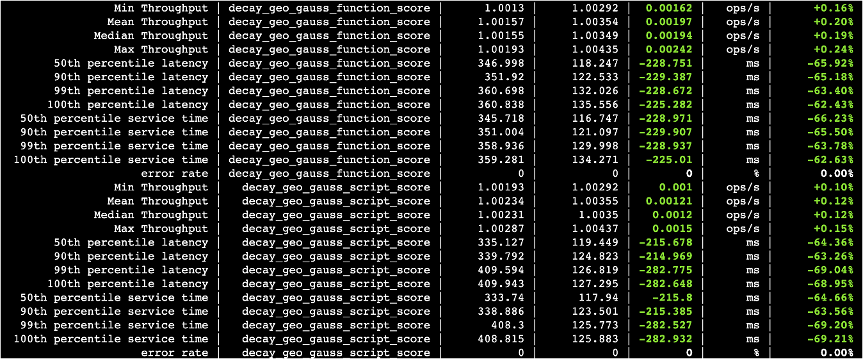
图三十七
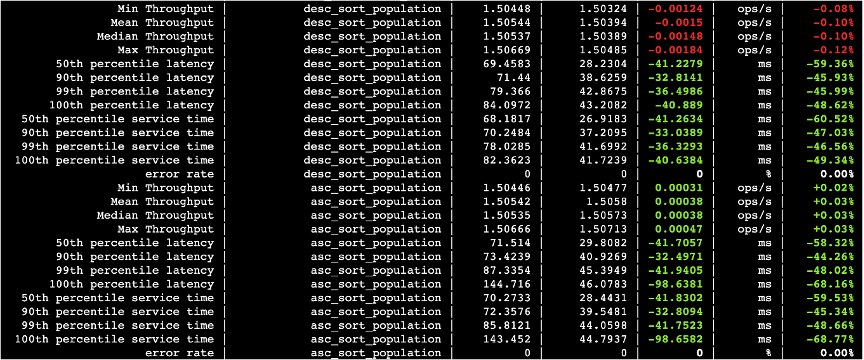
图三十八
4.3.2 总结
IO并行化并发度设置为3,性能普遍提升3倍左右,经过压测对比发现,P50,P90,P99耗时普遍减少5~10倍,查询抖动更少更稳定。
如果cpu核数更多,拆分的子请求可以更多,性能会更好,如果将并发度设置为5,理论上性能会提升5倍左右。
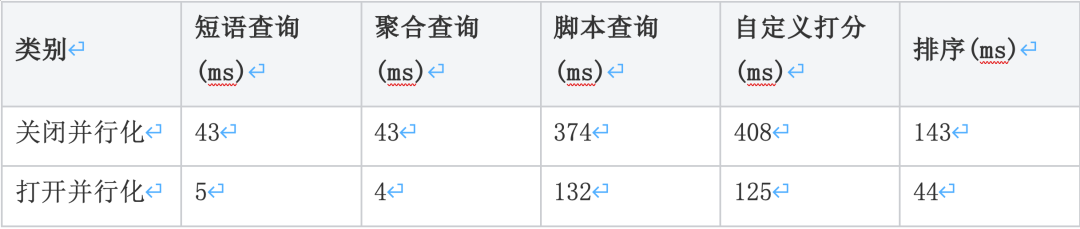
图三十九
五 未来规划
在基于 ES 的全新架构下,未来我们还有进一步的性能优化空间:
1)聚合下推。扩展聚合分析场景,实现聚合算子下推 Lucene或者bkd代替doc values,聚合分析性能提升50到100倍+。
2)排序优化。利用point values代替doc values,缓存每次访问的最大的maxDocVisited和maxValue(正序排序)以及minValue(倒序排序),在遍历倒排表时跳过不必要的计算,支持所有number类型字段的排序优化,排序性能提升10倍+。





