


导语:
随着ELK方案在开源日志分析领域越来越流行,各种业务场景也给ELK方案带来了越来越多的挑战。本文将回顾一次真实客户案例,从使用姿势上,提供一些大集群、多日志主题场景下的集群优化思路。
一、ELK不香了?
我们客户的ELK已作为其日志分析平台的方案,服役了多年。随着新服务上线、业务增长,集群规模也随之扩大,每次集群扩容都成功使日志平台顶住了业务的压力。最近客户经历的几次高峰期,又按照以往的经验,紧急做了多次扩容,希望能快速解决问题。然而,依旧频繁出现大面积日志积压,甚至还出现日志查询变慢,集群飚红等从未出现过的情况。多次扩容后,ELK方案的月成本增加到了客户难以接受的6位数,然而问题接连不断,性能令人堪忧。难道ELK不香了?
二、找出问题核心
我们第一时间对集群做了分析,奇怪的是在客户反馈积压的时刻,集群各层面的压力并不高。为了快速恢复日志服务的实时性,客户对logstash也做了扩容操作,期望能快速消费完kafka的积压。然而扩容后收益甚微,集群的写入速度变化不大。经历了几次,从客户发现高峰期积压,到高峰期结束,通过扩容的方式没能有效的解决积压问题,只能等待积压消费完成。
进一步分析发现,客户的集群规模很大,接近PB级别。索引多,整个集群热温架构,100个数据节点,75个热节点,共2000多个索引,50000多个分片。这2000多个索引,基本采用的是{index_name}-yyyy.MM.dd命名的按天滚动的索引,索引大小上两极分化,大的索引2~3TB,小的索引几KB,各索引的主分片数设置、分片大小的也不尽相同。实际上这种索引写入的规划上,是存在很大的优化空间的,但此时还没有明确的证据表明,这是导致链路积压的直接原因。直到我们偶然发现有集群中两个异常节点,压力比其他节点高很多。通过监控发现这两个节点在写入速度上,明显高于其他节点。
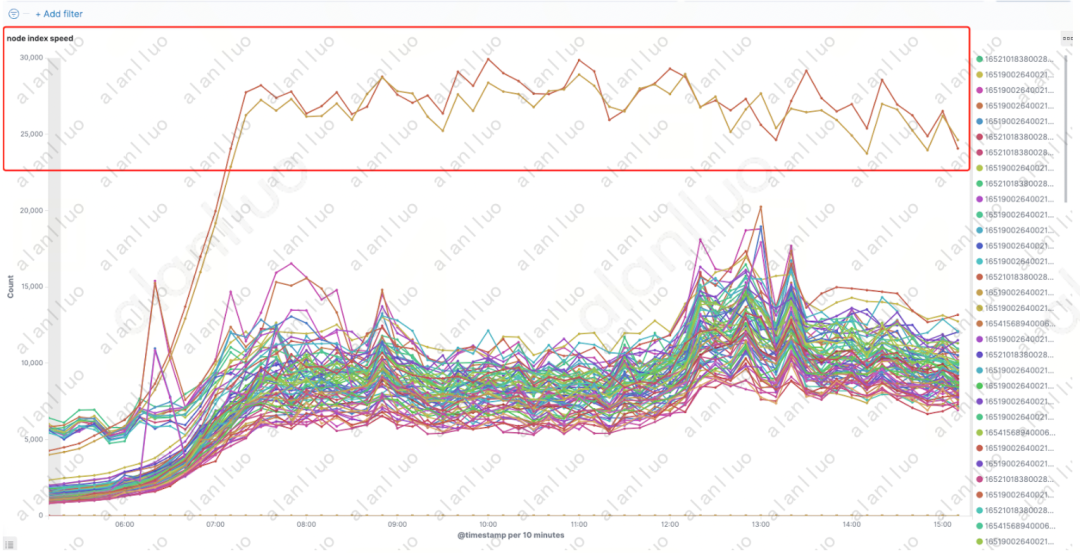
图1
这种明显的写入倾斜,一般是分片分配不均导致。通过近期实现的cerebro添加的节点、索引增强过滤功能,在众多索引中快速定位到了问题索引。
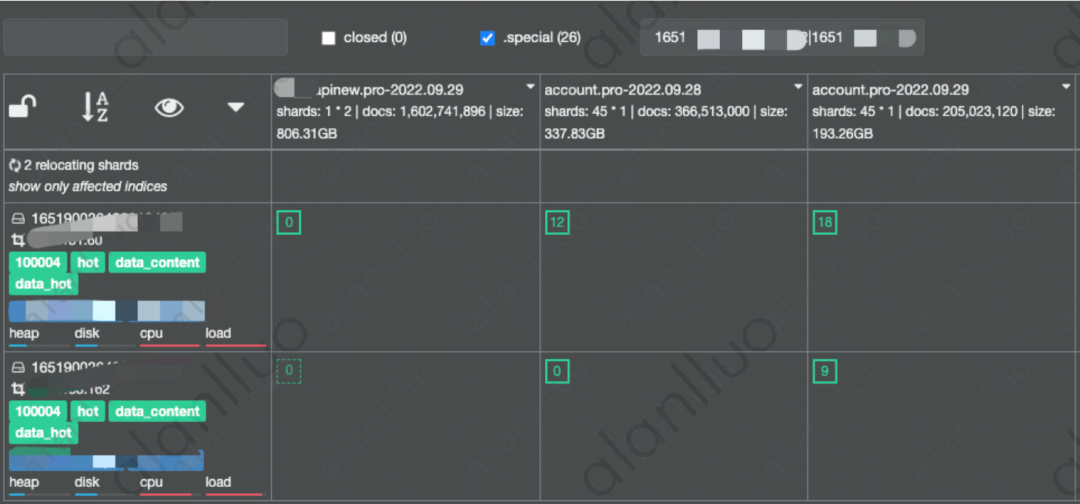
图2
可以看到这里只定义了一个主分片的索引,大小已经写到了800多G,其写入压力集中在了主分片和副本分配对应的两个节点上。这时我们和客户一起查看kafka的积压情况,果然也发生了积压。和客户了解到,这个索引是新业务上线写入,客户还没开始使用这个日志主题。这个单分片数也不是客户主动定义的,是索引模版的误修改,使得新增的日志主题匹配到了单分片的模版。了解清楚问题后,修正了模版,删掉了还未投入使用的日志索引。再次查看节点的写入监控,发现问题立刻得到了改善。
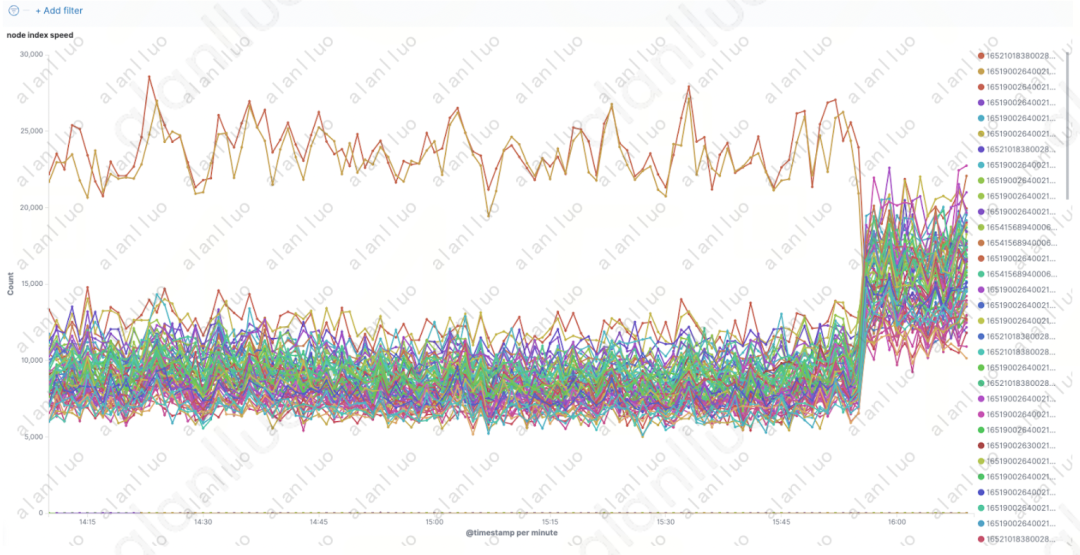
图3
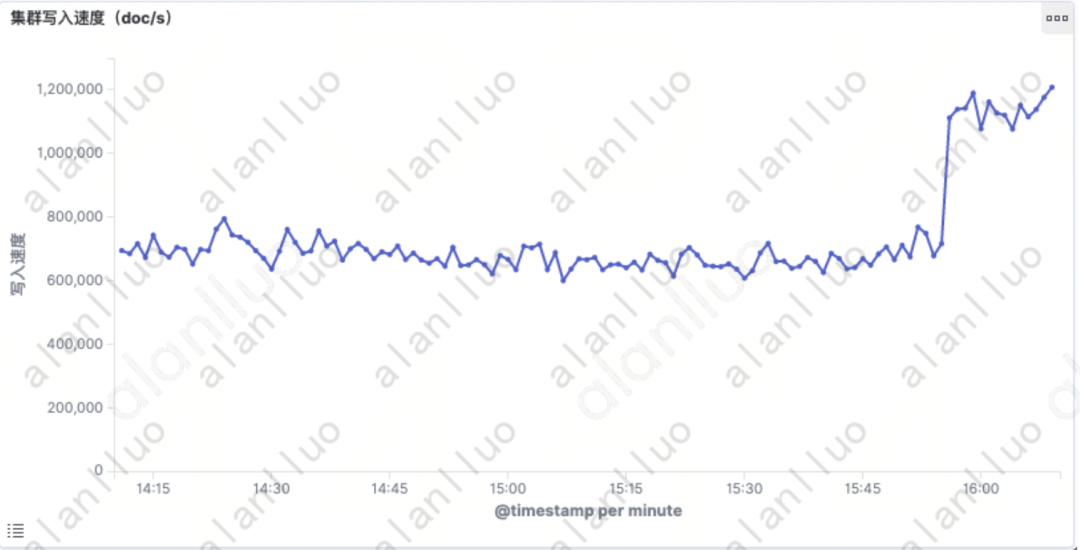
图4
不难发现,这两个异常节点写入速度恢复了正常,其余节点的写入速度、整体集群的写入速度也同时提升了!这是一次主动发现的,个别索引影响整个集群性能的问题。那么,是否客户在高峰期遇到的积压问题,也可能是个别索引造成的呢?我们虽然未能找出这种明显的证据,但还是合理的怀疑这个可能性。
为了求证这一想法,深入了解了客户日志集群的架构后,发现:
1.客户日志主题数以百计,由于历史原因日志主题在kafka的topic中是混用的,在logstash的管道中也没有做拆分,日志数据混合地向ES写入。
2.由于历史原因客户的索引模版定义未统一设规范,索引模版和ILM策略没有统一,有些索引匹配了不适合的模版。
3.日志主题没有做量级预估,均采用按天滚动的索引方式,分片数过多,大小上两极分化。
多个日志主题的数据混合写入到了同一个集群。几乎可以确定,只要有某个或某几个分片数规划不合理的索引,其写入性能受限,就会存在“短板效应”,引起整体集群写入速度受限!过多的日志主题,导致我们不易发现具体是哪个日志主题的索引拖慢了集群,很可能有很多索引都存在这样的问题。ELK的使用姿势优化势在必行。
三、优化无法实施
由于混合写入,带来了短板问题,那么最快的解决手段就是将量级较大的日志主题使用独立的kafka topic和logstash pipeline。然而,从客户的角度看,这几乎是无法实施的。日志接入是一直沿用的规范,由于历史原因中间的处理逻辑暂无人维护。且每个日志主题都对应了一个业务/微服务,需要推动对应的团队来修改,改造成本较大。
那么我们不得不换一个思路。既然数据接入层面混写无法优化,存在“短板效应”问题,那我们来解决短板问题不就好了吗?也就是说,我们回到ES本身,将ES的每个日志主题的索引,都来做最合理的配置,让集群中不存在“短板”。这样即便混写的数据进来,我们只要保证了每个索引都有最佳的写入能力,也能一定程度缓解短板效应。
客户对这种优化方式表示接受,同时也提出了几点诉求。需要考虑:
1.稳定性:优化需要平滑,保证各业务部门的正常使用;要能承受高峰期的写入
2.易运维性:简化的,新增日志主题方法、扩缩容后的分片策略调整方法
3.降低成本:过高的成本客户无法承受,要在保证性能的前提下降低成本
总结优化目标:
1、稳定性
1) 根治个别索引造成写入短板,阻塞整个链路。排除由于es原因导致消费能力无法提升的可能性
2) 保证分片的均匀分布和合理大小,提升各节点写入能力。排除单节点分配不均导致的性能问题
3)平滑优雅的过渡流程,最小化操作,过程中尽量保证业务无感、故障可回退
2、易运维性
1) 制定template和ilm策略的命名和管理规范,核心策略数量简化到个位数,完成替换后统一删除旧的。避免template过多不易维护,甚至错误覆盖导致一系列的集群、索引问题
2)仅用别名来读写索引,对外屏蔽内部索引策略
3、降低成本
优化项完成后视情况操作降配,兼顾稳定性
深入分析了每个日志主题的日增大小,可以将其分为4类

图5
四、优化思路
1、使用别名读写索引,索引按天滚动改为按量滚动
1)使用ilm索引生命周期的rollover能力,将rollover\_alias设置为索引名即可
2)例如,log1-2022.10.19这个索引,以后使用时,都仅指定log1,es会根据该别名,定位到需要读写的具体索引
3)写入时,以往logstash直接带出了后缀日期,后续这个后缀交给ilm索引生命周期来自动管理,logstash写入时只需指定log1
4)查询时,kibana的index pattern将通配改为使用别名log1来指定
2、分片均匀分布
1)热层索引主分片数等同于热节点数量
2)索引total\_shards\_per\_node=2,避免索引维度分片聚堆
3)提升分片均衡算法中的索引权重cluster.routing.allocation.balance.index,以保证索引层面的分片均匀分配
3、索引策略尽量减少,并抽象归类为
1)大日志主题(日增索引大小>960G),共用一套模版:
a.rollover条件,max\_primary\_shard\_size=40g,max\_age=1d,两条件触发任何一个即滚动一个新索引供写入
b. rollover后1d降温,即从创建开始,最长2d会降温
c. 降温后13d删除,即从创建开始,最长15d会删除
2)小日志主题(240G<日增索引大小<960G),共用一套模版:
a.rollover条件,max\_primary\_shard\_size=40g,max\_age=2d,两条件触发任何一个即滚动一个新索引供写入
b. rollover后1d降温,即从创建开始,最长3d会降温
c. 降温后13d删除,即从创建开始,最长15d会删除
3)小日志主题(60G<日增索引大小<240G),共用一套模版:
a.rollover条件,max\_primary\_shard\_size=40g,max\_age=4d,两条件触发任何一个即滚动一个新索引供写入
b. rollover后1d降温,即从创建开始,最长5d会降温
c. 降温后10d删除,即从创建开始,最长15d会删除
4)微日志主题(日增索引大小<60G),共用一套模版:
a. 索引热阶段分配在即冷节点,索引从创建到删除始终在温节点,
b.rollover条件,max\_primary\_shard\_size=40g,max\_age=8d,两条件触发任何一个即滚动一个新索引供写入
c. rollover后1d降温,即从创建开始,最长9d会降温
d. 降温后6d删除,即从创建开始,最长15d会删除
4、ilm+组件模版本次优化核心配置示例
PUT _ilm/policy/ALIAS_POLICY_VER.2022.11.02-large_topic_ilm
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_primary_shard_size": "40gb",
"max_age": "1d"
}
}
},
"warm": {
"min_age": "1d",
"actions": {
"allocate": {
"include": {
"_tier_preference": "data_warm"
}
}
}
},
"delete": {
"min_age": "13d",
"actions": {
"delete": {
"delete_searchable_snapshot": true
}
}
}
}
}
}
PUT _component_template/ALIAS_POLICY_VER.2022.11.02-large_topic_component_template
{
"template": {
"settings": {
"index": {
"lifecycle": {
"name": "ALIAS_POLICY_VER.2022.11.02-large_topic_ilm"
},
"number_of_shards": "32",
"number_of_replicas": "0",
"routing": {
"allocation": {
"total_shards_per_node": 2,
"include": {
"_tier_preference": "data_hot"
}
}
}
}
}
}
}
PUT _component_template/ALIAS_POLICY_VER.2022.11.02-tiny_topic_component_template
{
"template": {
"settings": {
"index": {
"lifecycle": {
"name": "ALIAS_POLICY_VER.2022.11.02-tiny_topic_ilm"
},
"number_of_shards": "24",
"number_of_replicas": "0",
"routing": {
"allocation": {
"total_shards_per_node": 2,
"include": {
"_tier_preference": "data_warm"
}
}
}
}
}
}
}
5、后续新日志主题的添加方法(日志名称以log1为例)
PUT _index_template/ALIAS_POLICY_VER.2022.11.02-log1
{
"template": {
"settings": {
"index": {
"lifecycle": {
"rollover_alias": "log1"
}
}
}
},
"index_patterns": [
"log1-*"
],
"composed_of": [
"ALIAS_POLICY_VER.2022.11.02-small_topic_component_template"
]
}
# PUT <log1-{now/d{yyyy.MM.dd|+08:00}}-000001>
PUT %3Clog1-%7Bnow%2Fd%7Byyyy.MM.dd%7C%2B08%3A00%7D%7D-000001%3E
{
"aliases": {
"log1": {
"is_write_index": true
}
}
}
五、ES的平滑蜕变
1、原始的索引读写策略
读写方需指定日期后缀,集群未使用别名(客户的logstash实际是混写,为了方便理解,将索引对应的数据流单独体现出来)
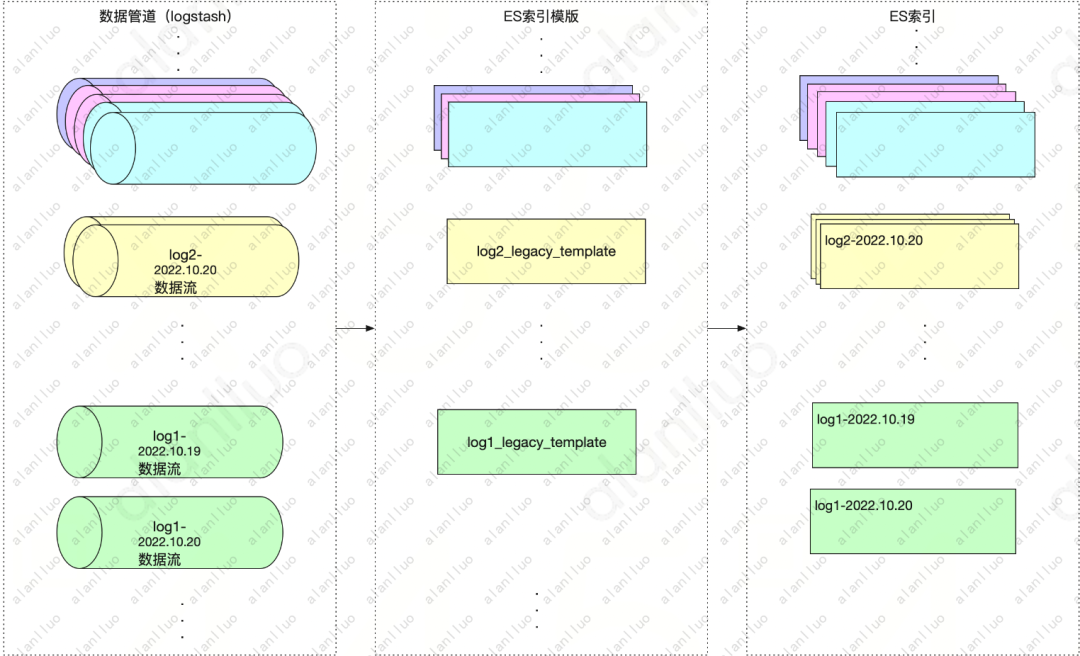
图6
2、过渡的索引读写策略
写入需指定日期后缀,读取可指定别名无需指定日期后缀
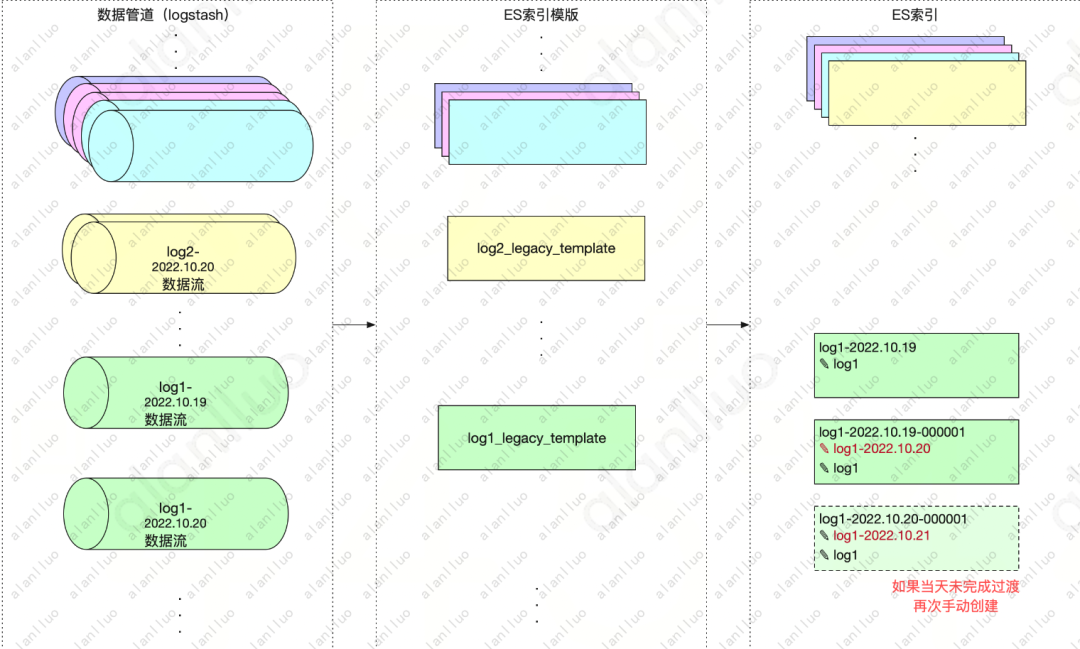
图7
3、优化后的索引读写策略
采用ilm定期定量rollover后的索引使用方式,索引切分策略交由ES来管理,读写访问无需带日期后缀
红色的别名代表is_write_index=true,当前写入指向的索引
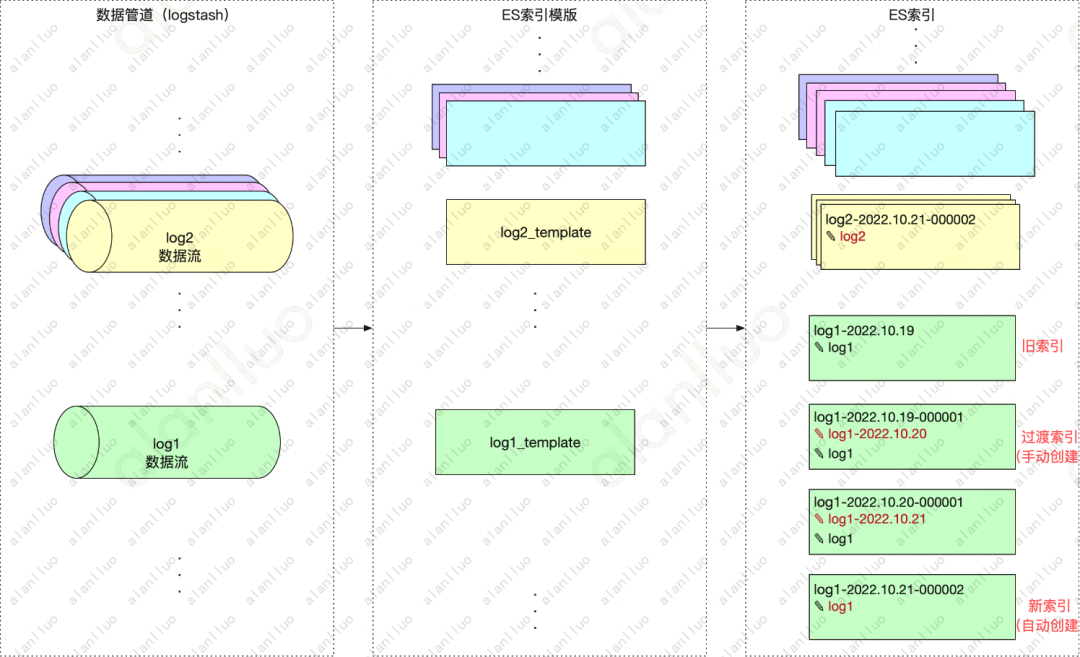
图8
4、操作步骤
1)升级7.14版本,支持component_template特性
2)梳理当前集群所有索引主题(日志主题),整理作为脚本配置。确保优化过程中不会有新的日志主题被创建
3)操作过渡的前一天
a.通过脚本1,为所有历史索引赋予别名(形如log1)
b.通过脚本2,提前创建所有日志主题的日期后缀别名(形如log1-2022.10.20)索引,保证第二天的数据流不会创建新的日期后缀索引
4)提前将新模版(使用component_template)都创建好,但不激活(不创建匹配index_pattern的index_template)。索引日志主题较多,需一一梳理后,编写脚本自动生成来提交index_template
5)准备进入关键流程,以下步骤需在一天内完成
a. 通过脚本3,将所有日志主题最新的写入指向的索引,更新别名log1的属性is\_write\_index=true
b. 通过脚本4,激活所有新模版(提交index_template)
6)修改logstash的写入方式,去除时间后缀,重新部署所有管道
7)通过脚本5,将当前各主题最新索引赋予rollover_alias策略并手动执行rollover
8)观察写入稳定后,关键流程结束
9)待所有旧索引生命周期结束后(预计两周),删除所有旧模版、旧ilm策略
原本希望不引入脚本操作,尝试使用alias date math的功能,但其不支持在模板中定义https://github.com/elastic/elasticsearch/issues/75651 。所以最终还是编写了批处理脚本,按照上述方式,基本完成了平滑无感的变更。完成后集群压力明显下降,随后便顺利地完成了集群的降配。
六、案例总结
从结果上看,本次针对es集群的优化方案,已经达到了预期的效果,成功的解决了客户的问题。客户关注的几个方面都顺利完成
1、稳定性
节点压力得到了均衡,客户遵循该策略后,ES层面不会再出现个别短板阻塞整个链路的问题
2、易运维性
梳理了187个日志主题,归纳并制定了4套索引策略,告别客户之前无序的维护
3、降低成本
集群按预期降配,性能和集群压力都维持正常,ES成本降低约50%
【核心问题】
多索引场景下,部分索引有写入瓶颈,混写时产生“短板效应”。
【核心优化点】
使用rollover的按量滚动能力,使所有分片均工作在合理的大小,使索引、集群维度,分片都是均衡分配的,充分发挥集群性能。
使用component_template功能,抽象并简化索引策略,大幅提升集群的可维护性。
【优化难点】
本次优化,一方面是在制定更加合理的ES使用规范,解决稳定、易运维、降本三方面的问题;另一方面更是在帮助客户梳理其整个业务日志链路,给杂乱无章的梳理工作起了个头,让客户对ELK方案重拾信心。后续客户表示会逐步推动拆分logstash、kafka仍存在的混写情况。
【结语】
如果您对ES比较了解,或者是ELK的老用户,希望本文能给您带来一些新的启发。如果您面临新的使用场景,也强烈推荐使用腾讯云ES的自治索引来保持正确的使用姿势。腾讯云ES团队可以提供专业的技术支持,期待能够与您合作。
免费体验活动专区
Elasticsearch 新用户可享 2核4G,0元 体验 30 天!顺畅体验云上集群

推荐阅读



关注腾讯云大数据公众号
邀您探索数据的无限可能

点击阅读原文,了解更多产品资讯
↓↓↓





