


本文共计6044字 预计阅读时长19分钟
TBDS(Tencent Big Data Suite)是腾讯基于多年大数据实践构建的一站式、高性能、企业级大数据存储计算分析平台。该平台覆盖数据全生命周期,具备安全、可靠、易用等特性,能够全面满足企业在大数据处理与分析领域的多样化需求。
TBDS Lakehouse 作为 TBDS 产品的重要组成部分,目前已服务国内众多头部券商、大型能源国企、头部银行等大中小型客户。随着数据湖技术在企业中的广泛应用,Iceberg 凭借其独特优势成为数据湖领域的事实标准,但在实际生产中,数据湖规模扩张也带来了一系列治理难题。本文将围绕 TBDS Lakehouse 产品在 Iceberg 数据湖上的治理实践,详细介绍其发展历程、核心挑战及生产经验。
TBDS Lakehouse平台
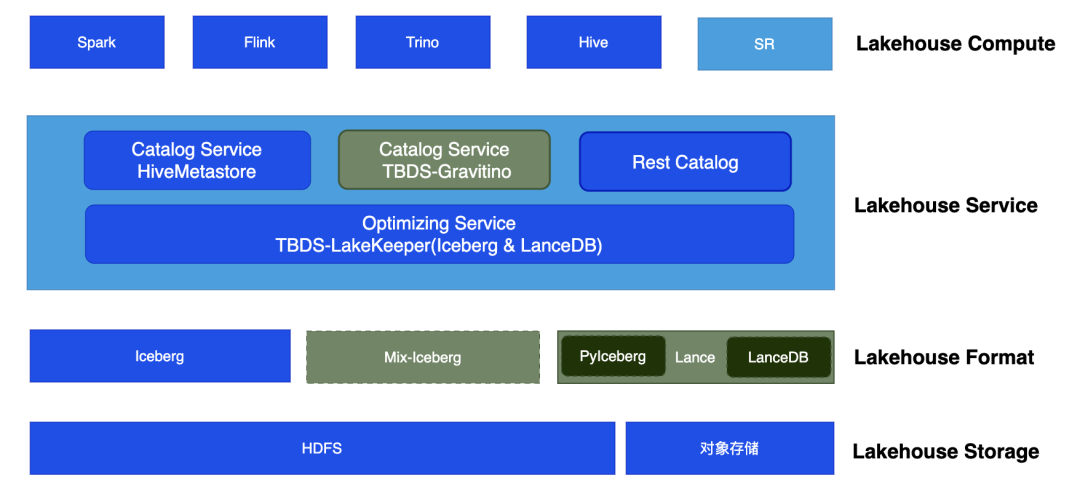
TBDS Lakehouse基本架构
TBDS Lakehouse 采用“统一存储基底+多模态格式与计算+统一服务治理”的模式,构建了一套覆盖多场景的数据湖体系,其核心架构组件包括:
- 计算层:支持 Spark、Flink、Trino、Hive 、SR等多种计算引擎,满足不同场景下的数据处理需求;
- 元数据服务层:包含 HiveMetastore Catalog Service、 Rest Catalog以及TBDS-Gravitino的提供统一的元数据管理能力;
- 治理服务层:通过 TBDS-LakeKeeper(支持 Iceberg & LanceDB)、Optimizing Service、Lakehouse Service 实现数据治理与优化;
- 存储层:基于TBDS-FS(HDFS、对象存储)构建统一存储基底,支持 Iceberg、Mix-iceberg、Pylceberg、Lance、LanceDB 等多模态数据格式。
基于该架构,TBDS Lakehouse 具备三大核心优势:
1.多场景适配:无需在数据仓库、数据湖、向量数据库等多个系统间进行复杂的数据同步和管理,一套平台即可支持多种数据处理场景;
2.数据共享与一致性保障:原始数据仅需存储一份,可通过 Iceberg 表、Lance 向量索引等不同格式暴露给不同工作负载,既减少数据冗余,又保证数据一致性;
3.AI 原生支持:通过深度集成 LanceDB,平台不仅能满足传统分析型需求,还能为推荐、搜索、AIGC 等基于向量相似性的智能应用提供坚实基础,成为 AI 原生的数据平台。
Iceberg数据湖治理的核心挑战
当前,鉴于Iceberg在:高效的数据更新与删除、灵活的查询能力、开放的元数据、多引擎兼容以及隐式分区等方面的优势,越来越多的用户选择了基于Iceberg表格式构建其数据湖能力。基于此,TBDS也将 Iceberg作为了TBDS数据湖组件主要的表格式。然而,随着企业数据湖规模的快速扩张,Iceberg 在实际生产过程中逐渐暴露出一系列治理挑战,亟需一套完善的自动化治理服务来解决。
在 TBDS 服务客户的实践中,随着数据湖数据量与表数量的快速增长,Iceberg 数据湖面临四大核心治理痛点,这些问题不仅影响系统性能,还导致存储成本攀升与运维压力增加:
主要表现在:小文件过多导致的性能瓶颈问题(如:I/O放大、HDFS元数据存储压力)、缺乏生命周期管理(快照清理、数据归档等)、孤儿文件难以治理、Iceberg元数据膨胀过快等问题。尽管 Iceberg 社区提供了 rewrite_data_files(小文件合并)、expire_snapshots(快照过期清理)等基础工具,但这些工具需手动调用,无法满足企业大规模数据湖的自动化治理需求。
为此,TBDS 在 Iceberg 应用的不同阶段,不断探索与优化治理方案,形成了一套从简单脚本到智能化平台的演进路径。
TBDS Iceberg治理发展历程
针对上述治理挑战,TBDS 根据 Iceberg 表数量、数据规模的变化,分三个阶段迭代治理方案,每个阶段的方案均有其适用场景与局限性,也为后续自研方案积累了实践经验。
阶段一:基于社区Spark-procedure方案
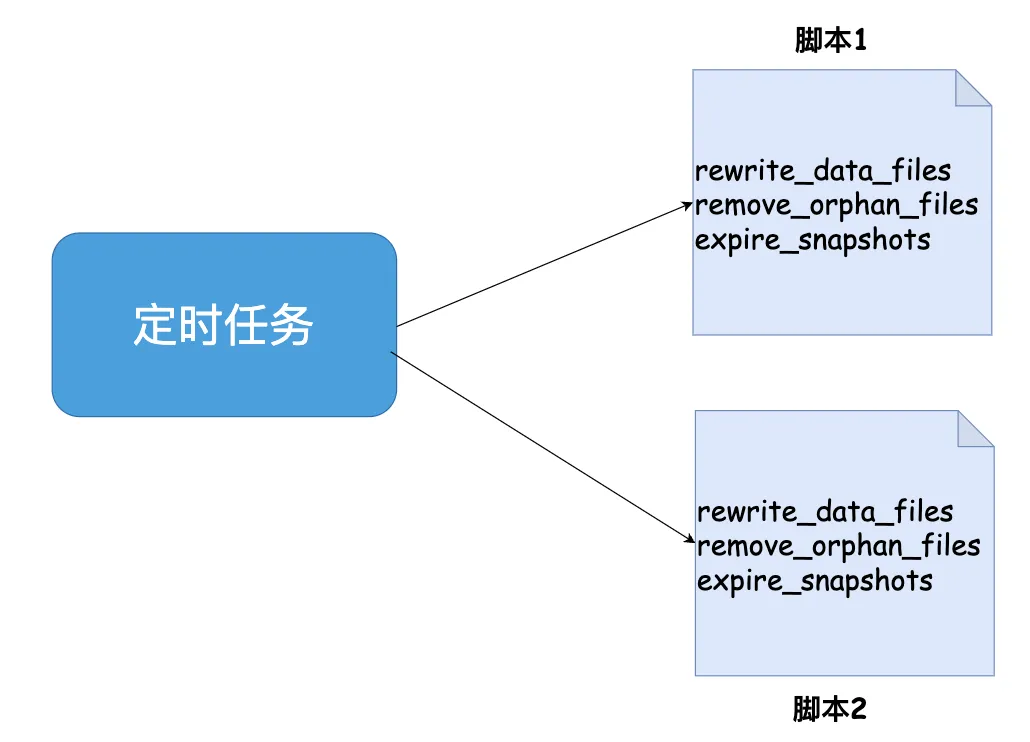
在Iceberg发展初期,TBDS采用定时脚本触发Spark SQL执行Procedure的方式处理小文件。该方案适用于Iceberg表数量较少的场景,不适合海量Iceberg治理场景。
实施效果
- 实现简单:基于 Iceberg 社区原生 Procedure,无需额外开发,快速上线;
- 方案灵活:适合Iceberg 表数量较少(<200张)的场景,可以根据表的使用场景针对性的配置优化周期等。
- 自动化提升:无需人工干预任务触发,降低运维成本;
实践瓶颈
- 运维能力不足:表数量增长后,需手动修改脚本以增加表名,无法支撑海量表(>1000张)治理需求。
- 运维能力不足:缺乏监控告警机制,任务失败后无法及时发现,需人工排查日志;
阶段二:基于最小均方误差算法(MSE)的方案
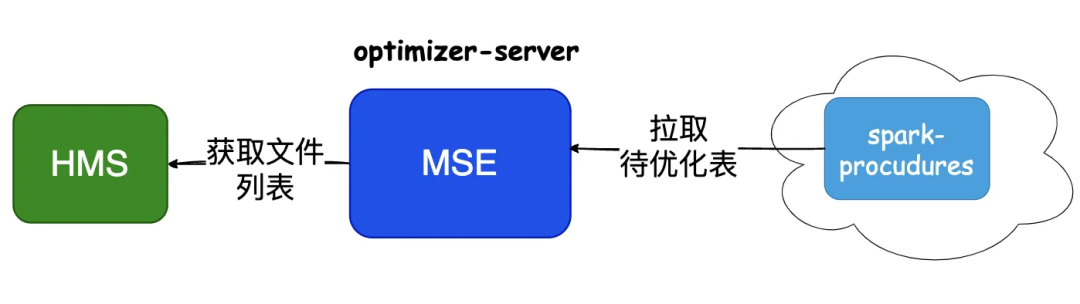
随着客户数据湖表数量增长至数千张,定时脚本方案的局限性逐渐凸显。TBDS 推出基于 MSE 算法的智能化治理方案,核心架构包含 Optimizer-Server 服务与常驻 Spark 程序,具体流程如下:
1.Optimizer-Server 服务周期性(如每小时)从 HMS(Hive Metastore)拉取 Iceberg 表文件列表;
2.计算每张表文件大小与目标文件大小(如 128MB)差值的均方误差(MSE);
3.若 MSE 超过设定阈值(如目标大小的 20%),判定该表小文件问题严重,自动生成合并任务;
4.常驻 Spark 程序周期性(如每 10 分钟)拉取任务并执行,避免资源抢占。
实施效果
- 智能触发:基于统计算法动态识别需治理的表,减少不必要的合并操作,节约计算资源;
- 自动化提升:无需人工干预任务触发,降低运维成本;
- 资源优化:常驻 Spark 程序独立运行,减少对线上业务的影响。
实践瓶颈
- 参数敏感度高:不同表的文件生成速率(如实时表每秒写入 vs 离线表每天写入)、文件大小差异显著,需针对每张表精细调整 MSE 阈值,运维复杂度高;
- 自适应能力弱:无法应对数据访问模式变化(如某张表突然从离线写入转为实时写入),易出现漏治理或过度治理;
- 扩展性不足:表数量超过 2000 张后,Optimizer-Server 扫描元数据的时间大幅增加,导致任务触发延迟。
阶段三:引入Apache Amoro
为解决 MSE 方案的扩展性问题,TBDS 引入 Apache Amoro(社区开源的 Lakehouse 优化引擎),采用 “AMS 服务 + 常驻计算引擎” 的异步架构,核心设计如下:
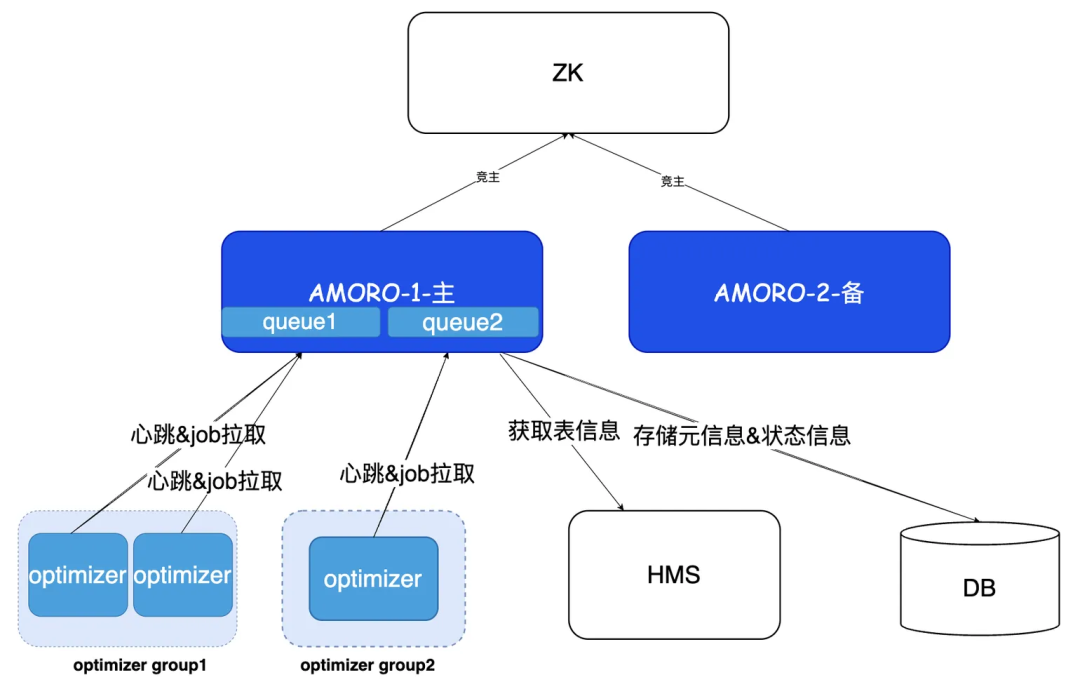
Amoro方案将数据文件重写分为两部分:AMS服务周期性扫描表元数据,识别需合并的小文件并生成任务放入队列;常驻Flink/Spark引擎主动拉取任务执行。Amoro采用“小步快跑”策略,将小文件合并划分为多个等级:
- Minor合并:处理小于target×1/8的碎片文件,合并至大于该阈值。
- Major合并:将大于target×1/8的文件合并至目标大小targetSize。
- Full合并:全量表重整。
具有如下的优势:
- 资源精细化控制:根据不同合并等级分配计算资源
- 异步处理模式:计算引擎主动拉取任务,提高资源利用率
- 但随着Iceberg表数量增长,其在生产上面临性能压力和运维负担越来越重:
- 主备架构存在单点瓶颈,扩展性受限
- 海量表面临元数据扫描性能压力
- 自动化运维能力不足,人工干预频繁
为此,TBDS在吸收Amoro优秀特性(如文件大小分级、任务等级划分等)的基础上,推出了TBDS解决方案:LakeKeeper,在架构设计和运维自动化方面实现重大突破。下文将重点介绍LakeKeeper在Iceberg小文件治理中的应用。
TBDS LakeKeeper:TBDS
Lakehouse治理平台
LakeKeeper 是TBDS 针对TBDS-Lakehouse治理推出的自研平台,目前在海量Iceberg表治理场景,通过 “主从架构 + 分桶策略 + 资源自适应” 三大核心设计,解决了 Amoro 方案的性能瓶颈与运维问题,实现了十万级 Iceberg 表的自动化、高性能治理。
LakeKeeper核心架构概述
LakeKeeper 采用分层架构设计,包含接入层、服务层、优化层三大模块,核心组件及功能如下:
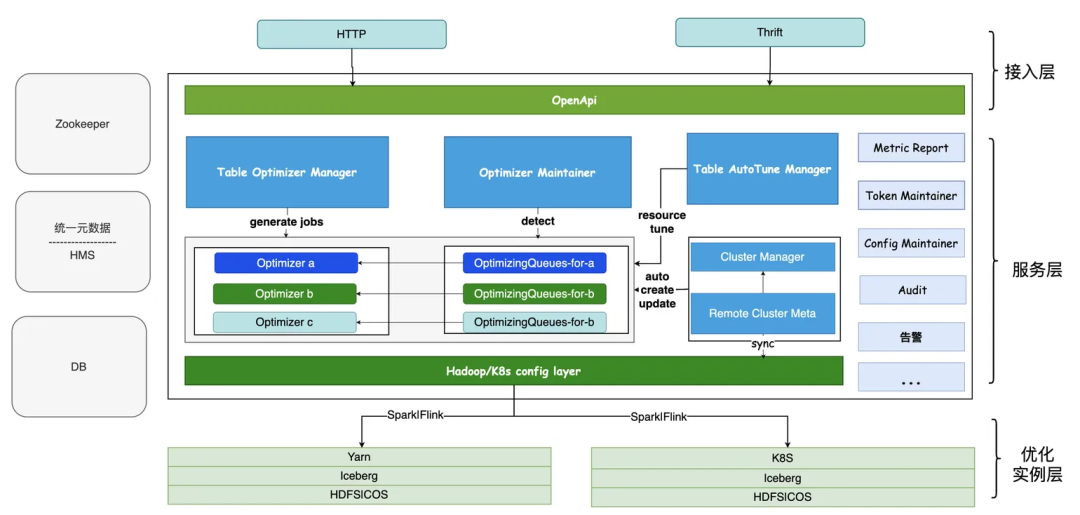
LakeKeeper架构核心包括以下服务:
- Table Optimizer Manager:表优化服务,按照分区的粒度将需合并的文件组装为Task并放入任务队列,由运行在YARN或K8s上的优化器主动拉取处理。
- Optimizer Maintainer:负责优化器生命周期管理,实现自动扩缩容。
- Table AutoTune Manager:负责自优化与自运维,包括队列空闲缩容、阻塞扩容、GC梯度扩缩容等。
解决海量表面临的性能问题:主从模式与分桶策略
针对 Amoro 主备架构的性能瓶颈,LakeKeeper 通过 “主从模式 + 分桶策略” 实现横向扩展,支撑十万级 Iceberg 表治理。
主从模式
LakeKeeper 将 Amoro 的 “主备模式” 升级为 “主从模式”,核心逻辑如下:
- 主控节点(LMS-Leader):负责表划分、分桶分配、故障转移;不直接扫描元数据,仅协调从节点工作,避免单点压力;
- 从节点(LMS-Slave):多个从节点并行工作,每个从节点负责部分分桶的表元数据扫描与任务生成;
- 任务拉取:优化器从轮询各从节点拉取任务,避免单节点任务堆积。
通过主从模式,LakeKeeper 实现了元数据扫描的并行化,将单节点的元数据扫描压力分散到多个从节点,扫描效率提升 N 倍(N 为从节点数量),可支撑十万级表的实时治理。
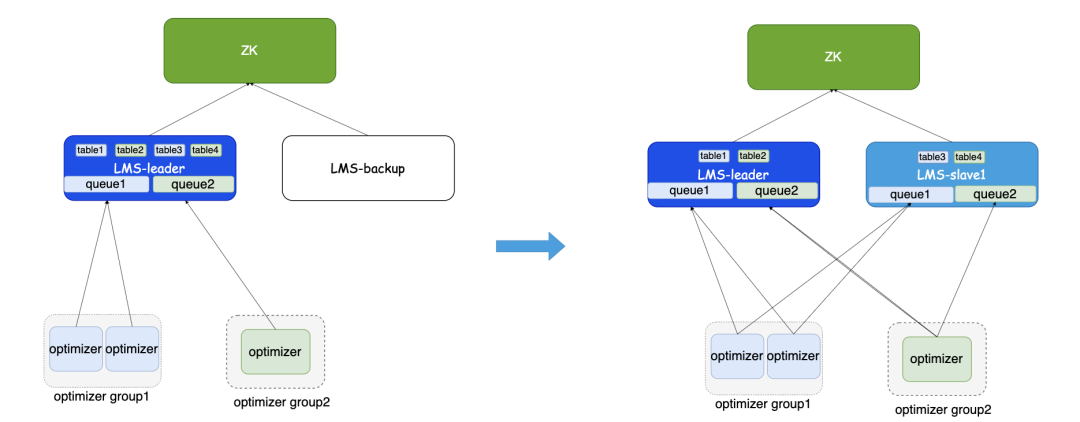
在主从模式下,所有LakeKeeper Server节点协同工作,主节点负责表划分与故障转移。
分桶策略:实现负载均衡
为将治理任务均匀分配到各个从节点,LakeKeeper 采用分桶(Bucket)策略,支持 “按表数量划分” 与 “按文件数量划分” 两种模式。以下以 “按表数量划分” 为例,详细介绍工作流程:
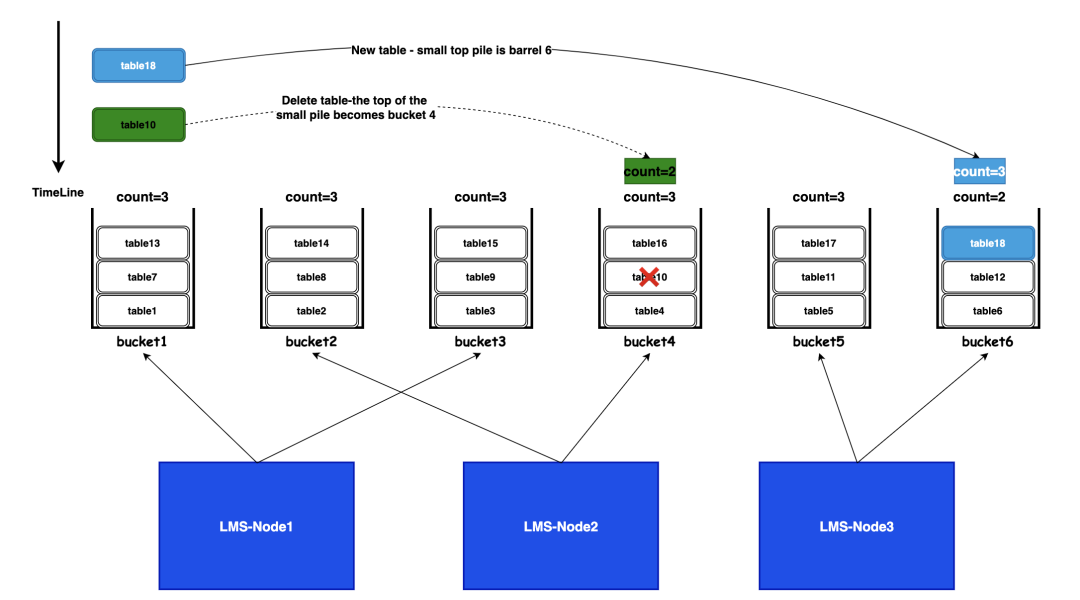
步骤 1:分桶初始化
将所有需要治理的 Iceberg 表通过哈希算法(如表名哈希)分配到多个固定的桶(Bucket)中,例如设置 100 个桶,每张表对应一个桶 ID。
步骤 2:负载评估
系统采用小顶堆(Min-Heap)数据结构,统计每个桶内关联的表数量;小顶堆的堆顶为负载最轻的桶(表数量最少),可快速识别空闲资源。
步骤 3:新表分配
当有新表接入治理系统时,系统从堆顶选取负载最轻的桶,将新表分配至该桶;分配后更新小顶堆,保证后续分配仍基于最新负载。
步骤 4:节点绑定
每个从节点(LMS-Backup)负责处理一个或多个指定的桶,例如 10 个从节点,每个节点负责 100 个桶;从节点仅需关注所属桶内的表,实现职责分离,避免跨节点元数据访问。
通过分桶策略,LakeKeeper 以较低的计算开销(哈希计算 + 小顶堆排序)实现了所有节点间的负载动态均衡,避免部分节点过载、部分节点空闲的情况。
动态分配及故障转移:保障系统高可用
LakeKeeper 通过 ZK 协调服务实现分桶的动态分配与故障转移,确保系统在节点上下线时仍能稳定运行,核心流程如下:
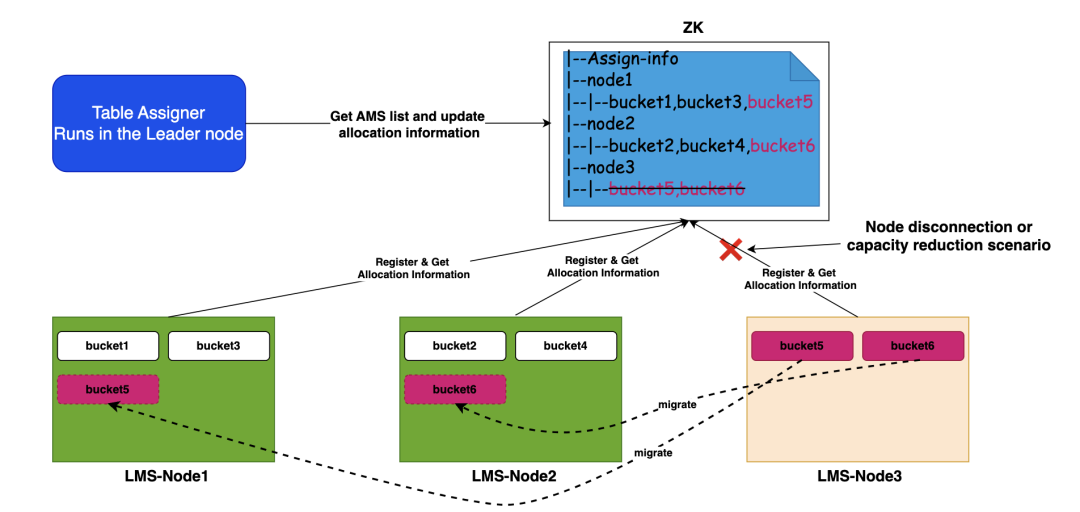
1.节点状态感知
所有从节点(LMS-Slave)向 ZK 注册临时节点(如 /node1、/node2),定期发送心跳(如每 30 秒);
主控节点通过 ZK 实时获取存活的从节点数量,例如生产环境建议 “从节点数量” 与 “桶数量” 可整数整除(如 10 个从节点、100 个桶,每个节点负责 10个桶),避免出现桶分配不均的情况。
2.正常场景:分桶分配
主控节点计算每个从节点应分配的桶数量:桶数量 ÷ 从节点数量,确保负载均匀;
采用轮询方式将桶分配给从节点(如桶 1-10 分配给 node1,桶 11-20 分配给 node2,以此类推),并将分配结果存储至 ZK 的指定节点(如 /bucket-assignment/node1);
从节点启动后,通过监听 ZK 对应节点的变化,获取自身负责的桶列表,随后从统一元数据服务拉取桶内表的元数据,执行扫描与任务生成操作。

3.故障场景:动态转移
当某一从节点(如 node2)因硬件故障、网络中断等原因心跳超时(如超过 90 秒),ZK 会自动删除该节点的临时注册信息,触发故障转移流程:
状态检测:主控节点通过 ZK 监听机制实时感知 node2 下线,立即标记 node2 负责的桶(如 11-20)为 “待重新分配” 状态;
负载计算:主控节点统计当前存活从节点的负载情况(如通过桶内表数量、未处理任务数评估),优先选择负载最轻的节点(如 node5)作为接收方;
桶转移:主控节点更新 ZK 中的桶分配信息,将原 node2 负责的 10 个桶分配给 node5,并向 node5 发送 “桶接管通知”;
无缝衔接:node5 接收到通知后,立即拉取新分配桶内表的元数据,继续未完成的扫描与任务生成工作,整个过程无需人工干预,业务无感知,保障治理任务不中断。
4.扩容场景:负载再平衡
当 Iceberg 表数量持续增长,现有从节点负载过高(如单个节点负责的表数量超过 1 万张),可通过手动或自动扩容增加从节点,触发负载再平衡:
自动扩容触发:Table AutoTune Manager 实时监控各从节点的 CPU 使用率、元数据扫描耗时等指标,当指标超过阈值(如 CPU 使用率持续 5 分钟高于 80%),自动向资源调度平台(如 K8s 集群、YARN)申请新增从节点;
负载迁移:新增从节点(如 node11)注册到 ZK 后,主控节点重新计算每个节点的桶分配数量(如 11 个节点、100 个桶,每个节点负责约 9 个桶),并将部分高负载节点(如 node1 原负责 10 个桶)的多余桶(如 1 个)迁移至 node11;
平滑过渡:迁移过程中,原节点继续处理已生成的任务,新节点仅接管新分配桶的元数据扫描,避免任务重复或中断,实现负载无缝转移。需要注意的是:在迁移 bucket 时,采用最小变更原则,尽量减少表迁移的范围。
资源自适应与自动扩缩容
可以简化一下LakeKeeper中优化任务可以概括为生产消费者模型:
- 任务生产端:将待处理任务放到服务端队列。
- 消费端:多个常驻消费者(spark/flink)主动拉取任务。
Iceberg表写入是动态的,不同表之间数据写入量,更新量,小文件的产生频率等都有很大的差别,这也就表明了需要处理的优化任务具有较大差异,也即不同的任务需要的资源需求不同,如果资源配置不合理则比较容易出现任务因资源不足导致OOM的情况,如果靠人工运维配置则需要非常大的人工运维压力并且使用复杂度高,因此需要一个自适应的资源使用方案,来简化LakeKeeper的使用门槛和降低人工运维的投入度。下面会介绍LakeKeeper是如何实现这一目标的。
普通资源组与大任务资源组
普通任务资源组与大任务资源组对应的优化器资源可以按照比例分配(一般建议按照8:2的比例进行分配),在实际生产中可以根据实际情况调整。
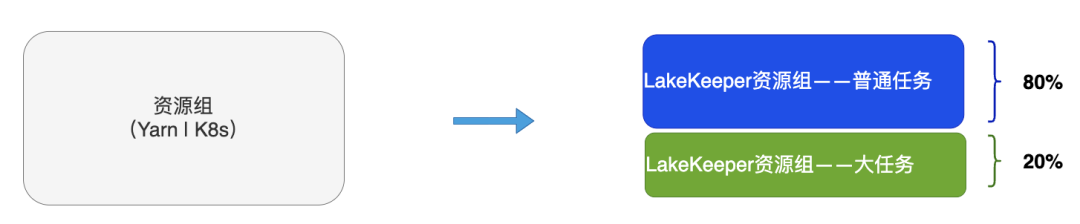
基于此一个资源组对应一个队列,改成一个资源组对应一个普通队列和一个用于处理大任务的队列, 如果普通队列中的表出现OOM失败后,则自动迁移到大任务队列,大任务队列中有表处于Pending状态后,自动触发启动资源组对应的优化器进行处理。表被迁移到大任务队列后,经过多轮成功的优化任务后自动迁移回普通队列。此外,还需要实现根据队列积压状态对优化器实现自动扩缩容能力。
水平扩缩容
LakeKeeper中采用基于Spark DRA来实现了优化器在水平方向上的动态扩容,在Spark优化器中,由Driver从LakeKeeper Management Server(LMS)中拉取待处理的任务后交给Executor上执行。在这里通过DRA可以实现单个优化实例上的动态扩缩容。在实际的实现上LakeKeeper还会根据LMS对应的计算资源的动态变化自动的创建和销毁优化器实例数。
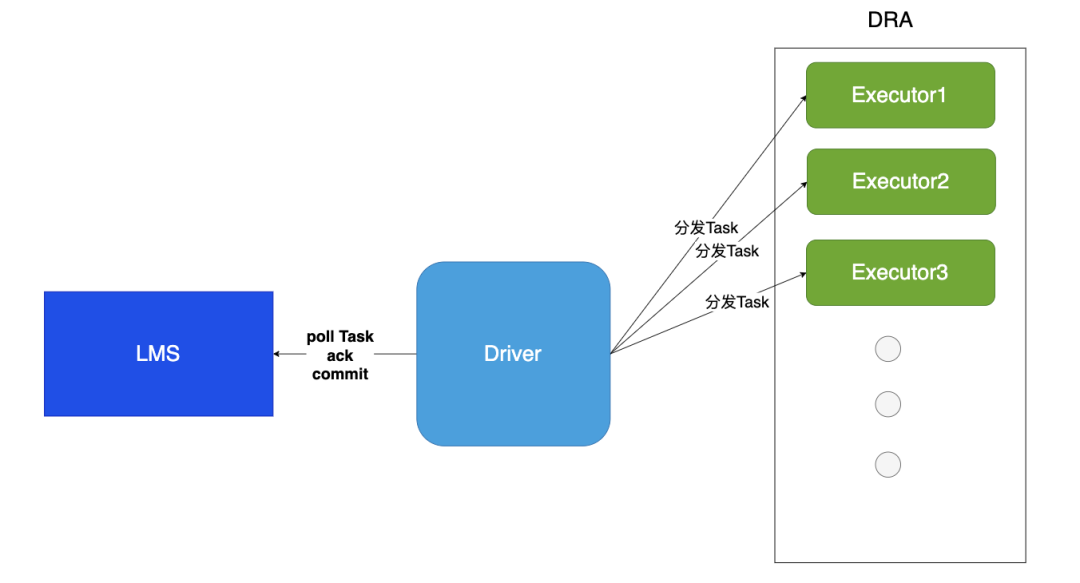
基于此,在LakeKeeper中采用了如下的实现方案来达到资源自使用与自动扩缩容的目的。
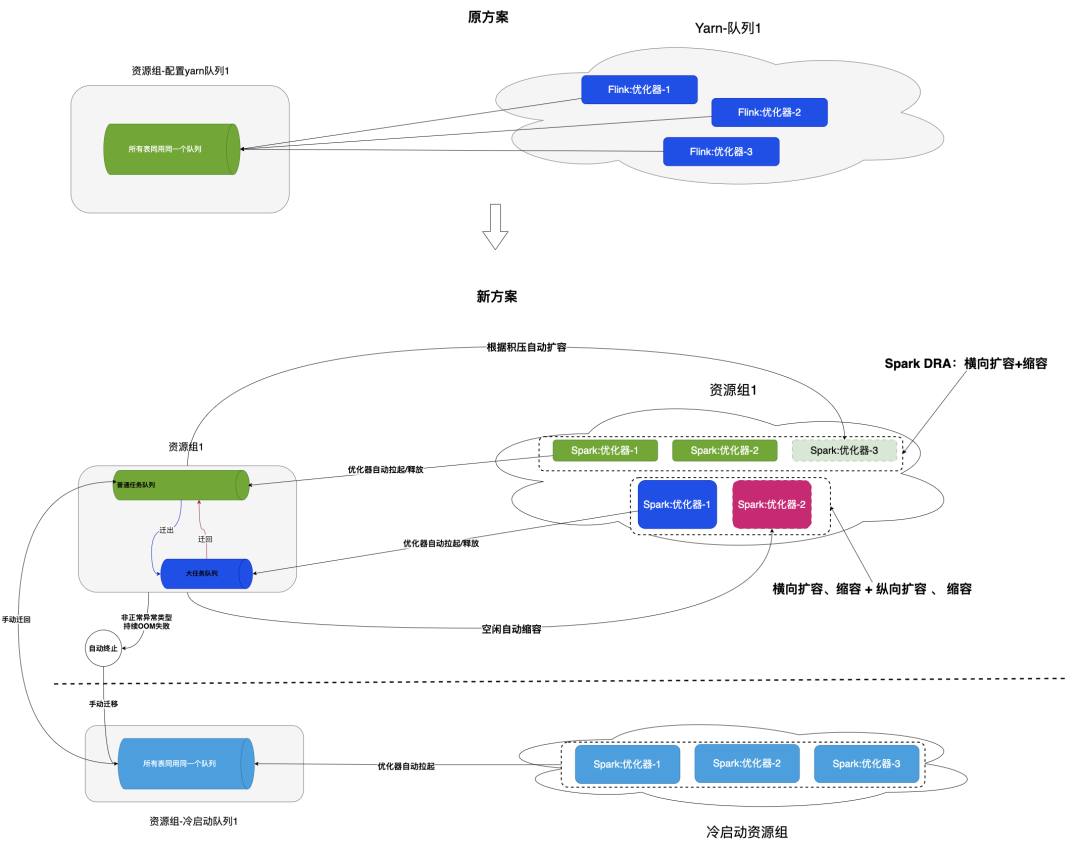
纵向扩缩容
除了普通队列上的水平扩缩容外,对于某些对资源需求比较高的任务,设计了大任务队列,这个队列对应的优化器的资源会比普通优化任务资源更高,如果任务在当前资源下仍然不足以处理,那么就需要自动触发大任务队列上的纵向扩缩容能力。
触发条件
- 当 countOOM ≥ 设定阈值(如连续 3 周期均出现 OOM)时,认为现有优化器内存不足,触发纵向扩容。
扩容策略
确定新内存大小:
- 可按步进式(如每次 +2 GB,步长可配置),或按故障时的内存乘以安全系数(如 1.2)来设置。
- 释放老的优化器,启动新配额优化器。
缩容策略
从上一次OOM到现在已经成功运行了多个task,并且连续多个周期没有再出现过OOM,则触发缩容(最低缩容到初始默认值)。
缩容时有两种策略:
- 一种是直接恢复到原始值;
- 一种是采用梯度下降逐步恢复的方式;
- 可按固定增量(如每次 -2 GB,步长可配置),或按故障时的内存乘以安全系数(如 0.8)来设置逐步的降低内存。
- 释放老的优化器,启动新配额优化器。
基于洞察的使用规范:从"被动救火"到"主动预防"
随着Iceberg表在TBDS客户数据湖中的广泛应用,我们发现用户在Iceberg使用过程中并没有严格参考TBDS-Iceberg使用规范及最佳实践的建议,存在诸多不规范现象,比较典型的问题有如下一些:
- 分区设计不合理导致查询性能下降
- 任务并发度和提交不规范导致小文件过多影响存储效率
- 并发写入冲突频发影响业务稳定性
- 缺乏统一的数据治理标准
这些问题不仅影响查询性能,还增加了存储成本和运维复杂度,为Iceberg的治理也带来了比较大的使用成本。因此,TBDS产品中TI(TBDS Insight)提供了一套实现方案,来主动检测和发现客户在TBDS中使用不合理或者存在使用优化空间的问题,针对这些现象给出优化建议。
TBDS Insight

因此,TI(TBDS Insight 承担着TBDS平台大脑的角色)设计和实现了一套Iceberg表规范洞察的方案。主动发现客户中这些不良的使用方式并给出优化建议。上图简要描绘了TI的实现架构。其目前实现了一套基于规则和基于AI分析相互配合的洞察能力,范围涵盖了存储、计算、资源以及基础使用等场景。
针对于Iceberg的使用场景,TI目前提供了表结构、表存储、写入、读取和治理等等方面的主动洞察能力。当然我们也在积极探索和完善基于AI的更高层次的洞察能力,比如:写入频率、写入方式、查询模式分析、历史任务及耗时、历史治理情况等层面针对Iceberg的使用给出更深入的优化建议。
通过Iceberg使用上的洞察能力,为数据工程师和平台管理员提供优化建议,能够清晰地看到数据湖的内部运行状态,从而做出数据驱动的决策,最终实现一个高性能、低成本、高稳定的现代化数据湖平台。
总结与展望
实践总结
TBDS 在 Iceberg 治理的实践中,经历了从 “脚本工具” 到 “智能平台” 的演进:从初期依赖社区工具解决小规模表治理,到通过 MSE 算法实现智能化触发,再到引入 Amoro 支撑万级表场景,最终自研 LakeKeeper 平台突破十万级表治理瓶颈。这一过程的核心经验可概括为三点:
- 能力持续迭代:围绕客户实际痛点(如小文件、元数据膨胀、运维复杂)优化方案,确保技术落地价值;
- 架构横向扩展:通过主从模式、分桶策略解决单点性能瓶颈,是支撑海量表治理的关键;
- 自动化降低运营成本:从任务触发、资源分配到故障恢复,全链路自动化设计大幅降低运维成本,提升系统可用性。
在过去半年从在某国有大型能源企业和头部金融客户生产实践上看,实现了十万级Iceberg表的自动化治理,至少节省了50%+的资源开销。
LakeKeeper除了满足TBDS-Lakehouse在海量Iceberg表治理需求外,其能力上还设计包含了支持海量Hive表治理、Lance表格式治理、HDFS治理等场景,是一个比较通用的资源治理实践方案。
未来展望
随着 AI 与大数据融合趋势加强,TBDS 对 Iceberg 治理的规划将聚焦在如下方向:
- AI驱动自优化:引入大模型能力,基于历史治理数据(如合并耗时、查询性能变化)预测最优合并策略(如动态调整目标文件大小),进一步提升治理效率;
- 多模态数据治理:扩展 LakeKeeper 对 Lance、LanceDB 等向量数据格式的支持,解决 AI 场景下向量文件的小文件、生命周期管理、索引构建等核心问题;
- 提高Iceberg实时性:突破Iceberg主要面向是近实时数据湖场景使用限制,为用户提供更实时的数据出入湖体验。





