



熊彪
腾讯云高级工程师,目前主要负责腾讯云可观测系统的开发与设计。
前言
无论是性能测试环境还是生产环境中,我们经常会遇到响应时间过长的慢调用问题。响应时间是性能评估的一个重要指标,会对最终用户产生直接影响。一个产品是快是慢,响应时间是最直观的感受。其中最让人感到头痛的偶发慢调用问题,算是最难解决的一类问题,那么如何去排查这类问题呢?
本文要介绍的持续线程剖析就是解决这类问题的利器:一种用于分析和诊断应用程序中性能问题的技术。
它提供了关于线程的详细信息,如线程的执行时间、等待时间、调用栈等,以帮助开发人员理解和优化应用程序的并发性能耗时问题。通过持续线程剖析,我们可以确定应用程序中哪些线程消耗了大量的 CPU 时间以及线程之间的相互作用,有助于发现性能瓶颈和优化并发代码。
分布式链路追踪的短板
在传统的监控系统中,我们如果想要清楚地知道系统中的业务是否正常,会采用指标监控分析、日志采集分析等方式来对业务系统进行监控。当服务出现问题时,通过触发告警的方式及时通知负责人。通过上述传统的方法,我们可以知道具体哪一个服务出现了问题。但是这时我们并不能知晓具体的错误原因出在了哪里,需要程序系统开发人员到日志系统里面查看错误日志,甚至进一步需要登录到真实的业务服务器上查看执行情况来解决问题。如下图所示:
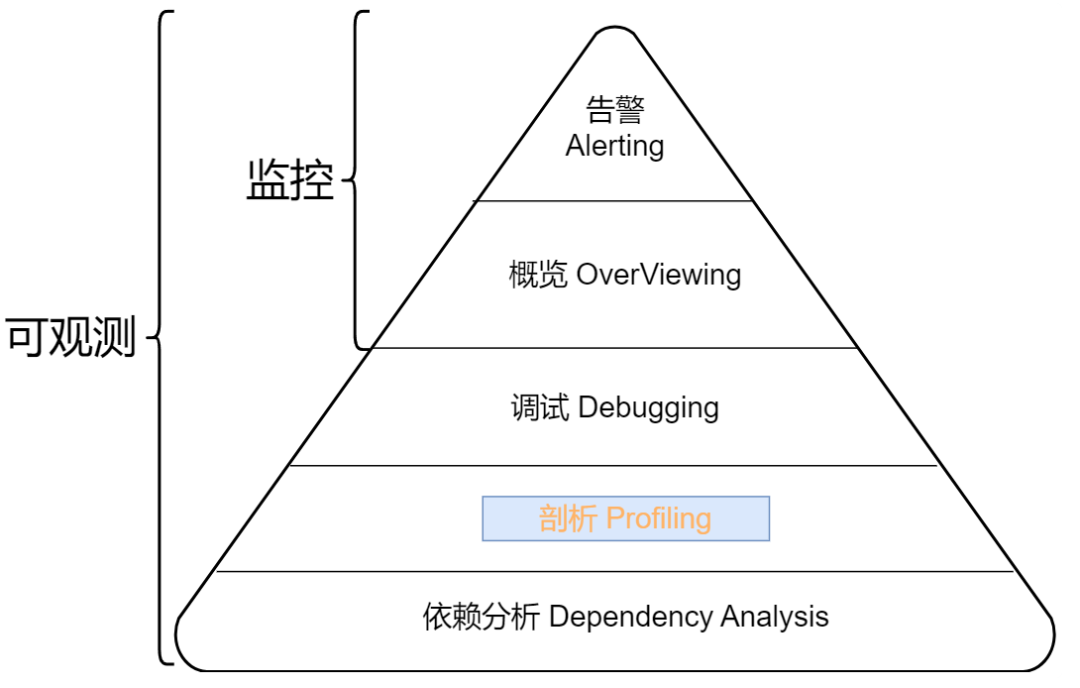
从上图可以看出传统的监控只能给开发带来最顶层的“告警”和“概览”。如此一来,仅仅是发现问题的阶段,可能就会耗费相当长的时间。另外,发现问题但是并不能追溯到问题产生具体原因的情况也常有发生,这样反反复复会极其耗费工程师的时间和精力。
于是我们便从可观测中衍生出了分布式链路追踪系统。通过将业务系统接入分布式链路追踪系统中,我们就像是给程序增加了一个放大镜功能,可以清晰看到真实业务请求的整体链路(依赖分析 Dependency Analysis),包括请求时间、请求路径,甚至是操作数据库的 SQL 语句都可以看得一清二楚。
那么分布式链路追踪系统是否能凭一己之力解决线上监控的任何问题呢?
随着我们对应用性能监控理解的加深,我们发现事情并没有那么简单。以 Java 语言为例,分布式链路追踪系统中 Java Agent 探针埋点技术主要是针对框架级别:RPC 服务、HTTP 服务、MQ 分布式消息粒度的埋点监控。这种实现的方式我们依旧会遇到程序调用缓慢或者响应时间不稳定等情况下,无法具体查询到慢调用的原因。如下图所示:
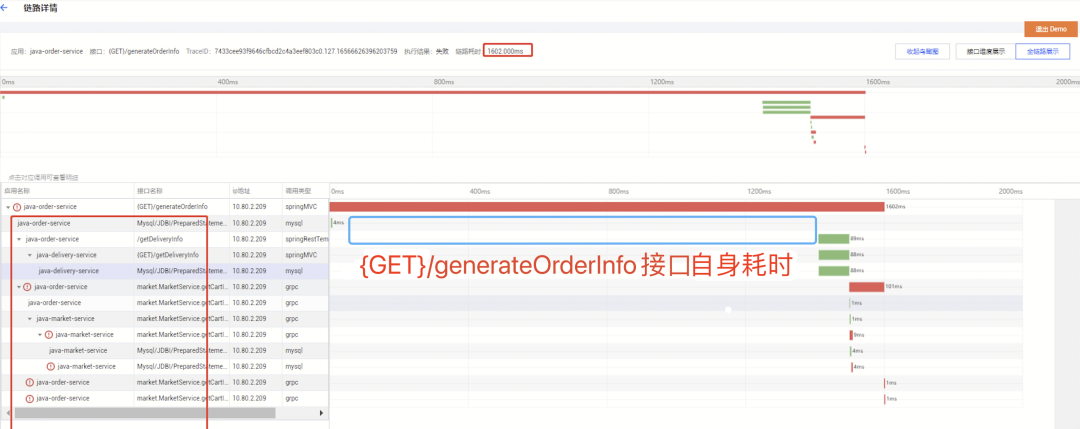
一次调用链作为一个 Trace 链路,存在一个唯一的 TraceId,该链路中包含多个 Span,分别代表调用的多个下游服务,每一个 Span 分别有一个对应的 SpanId 信息,从上图可知一次请求经过了多个服务。但却由于探针埋点技术主要是针对框架级(只针对框架的核心接口埋点),当调用耗时出现在探针埋点缺失的用户业务逻辑时,最终的调用链中会出现一段较长的耗时无法对应到具体的代码执行方法,从而导致无法对业务逻辑耗时进行准确的判断。
上图中可以很清晰的看出 HTTP 接口{GET}/generateOrderInfo 主要耗时原因未能在链路详情中展示出来,具体原因如上面所说:探针埋点针对的是框架级别网络请求的埋点,用户业务逻辑:HTTP 接口{GET}/generateOrderInfo 中调用的内部函数并未进行埋点,结果就是导致控制台链路详情页中 HTTP 接口{GET}/generateOrderInfo 大部分的耗时无法清楚具体什么原因导致。
那么分布式链路追踪系统就没辙了吗?
再让我们反过来看看图1可观测的金字塔,在可观测领域不仅有概况、告警、链路 Dependency Analysis,而且还有很重要的 Profiling 剖析的能力。结合 Profiling 剖析的能力,上述提到的问题就能找到解决路径。这就是接下来要引出的解决方案:Profiling 持续线程剖析。
APM 持续线程剖析方案
借助 Java 字节码注入技术,许多基于 Java 的框架可以实现自动埋点,从而帮助您了解请求具体发生在哪两个埋点之间。但这不足以定位代码层的所有问题,如需精确定位导致请求出现问题的代码方法,需要使用持续线程剖析。
持续线程剖析是代码级的诊断工具,就是利用接口对应的方法栈快照,并对方法执行情况进行分析和汇总,再结合有限的分布式追踪 Span 上下文,对代码执行速度进行估算。持续线程剖析激活时,会对指定线程周期性的进行线程栈快照,并将所有的快照进行汇总分析,如果两个连续的快照含有同样的方法栈,则说明此栈中的方法大概率在这个时间间隔内都处于执行状态。
因此,通过这种连续快照的时间间隔累加成为估算的方法执行时间。时间估算方法如下图所示:
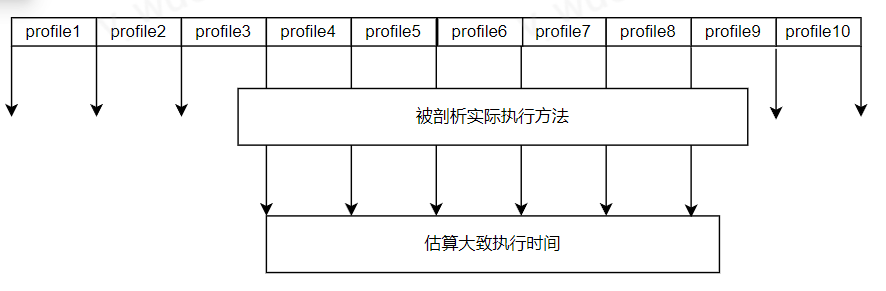
如上图所示,profile1-profile10代表10次连续的线程栈快照,实际方法执行开始时间在 profile3-profile4区间,方法执行结束时间在 profile8-profile9之间。线程剖析无法告诉您方法的准确执行时间,但是他会估算出方法执行时间为 profile4-profile8 的4个快照采集间隔时间之和,这已经是非常精确的时间估算了。
而这个过程因为不涉及探针对业务代码的埋点,所以整体的性能消耗是稳定和可控的。不需担心是否被埋点,是否埋点了 JDK 方法等问题。同时,由于上层已经在分布式追踪之下,线程剖析方法可以确定分析开始和结束时间,减少不必要的性能开销。最终通过探针 Agent 埋点+持续线程剖析的结合,排障服务棘手偶现慢调用问题。具体实现方案如下所示:
1. 腾讯云可观测 APM 持续线程剖析 Profiling 架构如下图所示:
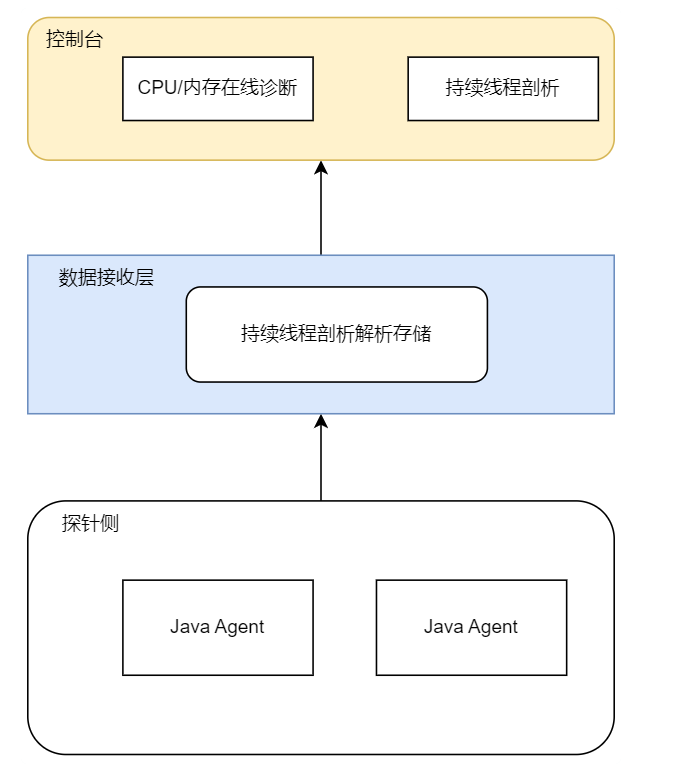
2. 接收层收集符合超过慢调用阈值的服务端接口(Span.kind=server),将其存放到 Redis 缓存中,具体流程如下所示:

3.探针 Agent 从接收层获取慢调用的接口列表。在触发调用了慢调用接口列表中的接口时,就会自动的触发线程剖析,具体流程如下所示:

结合上面三个图,我们就可以很清楚的知道:腾讯云可观测 APM 系统是如何实现持续的线程剖析能力的。接下来让我们介绍一个案例让大家加深理解用这种方式分析慢调用问题的好处。
APM 持续线程剖析案例
理解了什么是持续线程剖析理论概念之后,接下来我们就以一个用例来说明此方法的执行效果,让大家有一个更真实的体感:
@RequestMapping(value = {"/user/{id}"})
@ResponseBody
public User selectUser(@PathVariable String id) throws SQLException, IOException {
// getUser耗时3000ms,用于模拟真实业务的耗时;
getUser(3000);
// mysql查询调用逻辑
selectMysql(id);
return new User(id, "opentelemetry");
}
private void getUser(long sleepTime) {
try {
Thread.sleep(sleepTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void selectMysql(String id) throws SQLException {
Connection connection = null;
PreparedStatement preparedStatement = null;
try {
connection = dataSource.getConnection();
preparedStatement = connection.prepareStatement("SELECT name FROM mock_project_userinfo WHERE id = ?");
preparedStatement.setString(1, "1");
preparedStatement.executeQuery();
} finally {
if (preparedStatement != null) {
preparedStatement.close();
}
if (connection != null) {
connection.close();
}
}
}
这是为了验证持续线程剖析的能力而故意加入的问题代码。在上述代码逻辑中,第24行为数据库连接相关的执行逻辑,这类逻辑在 APM 系统中都会对其进行埋点覆盖,但第5行的具体客户业务耗时,一般都是由于缺失对应的监控埋点,导致其耗时最终都被统计在了上一层入口 HTTP 网络请求接口/user/{id}中。
这种情况若是在线上发生,对于运维和开发团队来说,是很难定位到这个方法片段的(在实际的生产场景中,调用链可能会很复杂,如果对业务方法执行不熟悉或者是一些复杂的异步调用场景难以利用该工具进行问题排查)。
首先我们先打开对应慢调用服务的线程剖析能力(用户可以动态开启关闭此按钮,无需重启探针):

1.开关开启后,我们看看性能剖析会怎样分析定位此类问题:

上图所示的就是我们在进行链路追踪时所看到的真实执行情况,其中我们可以看到在/user/{id}接口执行速度缓慢,这正是我们植入问题代码的方法。此时在这个调用中没有后续链路了,所以并没有更细致的原因。这就让我们看看线程剖析解决这个慢调用的问题,点击接口维度展示 tab:
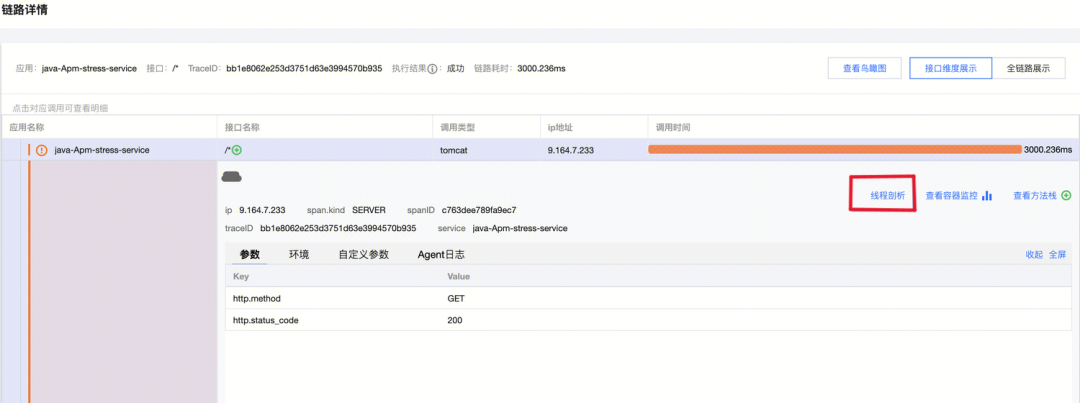
2.点击线程剖析按钮,查看线程剖析堆栈结果:
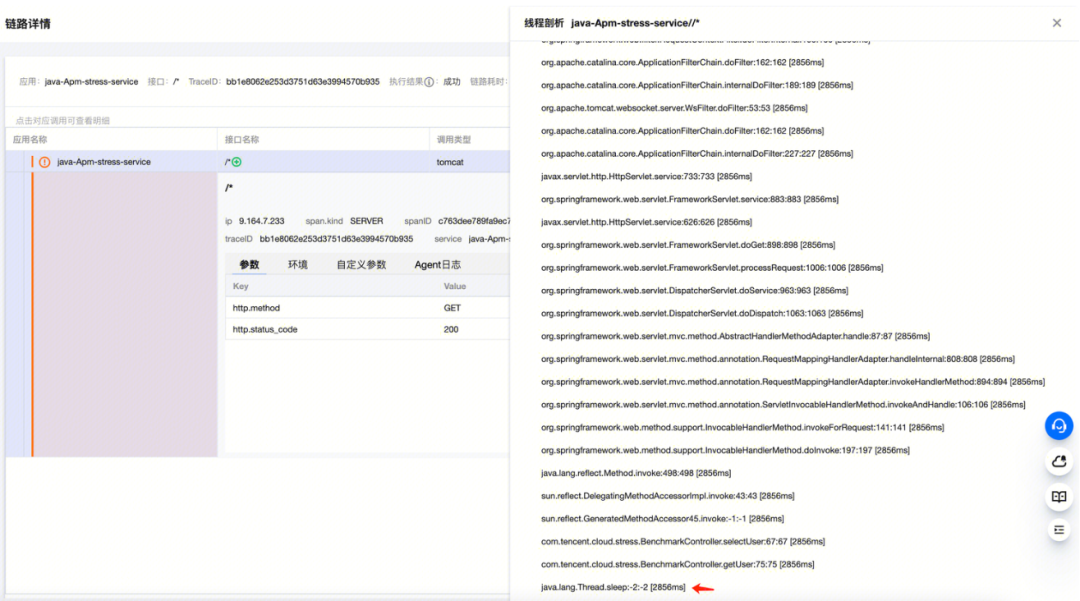
上图就是我们进行持续线程剖析后的真实结果图。从左到右分别表示:栈帧名称、当前栈帧自身耗时和监控次数。我们可以在最后一行看到,线程耗时真正主因就是 java.lang.thread.sleep。也就是如下代码:
private void getUser(long sleepTime) {
try {
Thread.sleep(sleepTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
到这里我们就完整地走了一遍用持续线程剖析如何定位慢调用的方法。
APM 持续线程剖析优势
接下来让我们正式介绍下腾讯云可观测 APM 持续线程剖析优势。
注意:文章所提到的持续线程剖析功能必须在腾讯云增强版 OpenTelemetry Java 探针下才能支持
- 性能开销很低
通过基于链路采样的措施,腾讯云可观测 APM 持续线程剖析 CPU 开销在5%以内,内存消耗在 30M 以内。GC 额外开销不明显,支持在生产环境常态化开启。
- 精确的问题定位,直接到代码方法和代码行
通过与链路 TraceId 信息关联提供针对调用链级的方法堆栈详细信息,可有效帮助诊断偶现慢调用的问题。
- 无需反复的增删埋点,大大减少了人力开发成本
不用承担过多埋点对目标系统和监控系统的压力和性能风险,减少分析和故障排查的工作量。持续线程剖析使不同应用程序版本和环境的性能比较变得容易。它可以减少发现性能瓶颈(包括微小瓶颈)所需的工作量,最终增加持续性能改进的可能性。
通过腾讯云可观测 APM 持续线程剖析,您可以在以下场景中助力问题排查:
- 当线上打折促销活动出现慢调用时,腾讯云 APM 线程剖析可为您快速定位到问题代码。
- 当系统出现大量慢调用时,腾讯云 APM 线程剖析可为您自动保存第一现场。
- 当业务太复杂,偶发性慢调用无法复现时,腾讯云 APM 线程剖析可为您还原代码真实执行轨迹。
总结
腾讯云可观测 APM 持续线程剖析系统支持持续的性能分析,并将数据保存在服务端,提供 Profiling UI 近实时的查看、回溯、分析。持续线程剖析的关键在于将性能分析持续化,由于性能分析的采集性质,若不持续对一个运行中的程序持续采样,可能某些时候的代码执行数据可能会被遗漏,或当程序在过去的某个时间点 Crash 时,进行程序运行时回溯是缺少运行时信息的。在对程序进行少数几次的性能分析时,可观测出的系统全局的资源消耗信息是片面的,所以我们需要持续线程剖析,方便连续、低成本的分析。
腾讯云可观测系统愿景:能够帮助工程师研究任何系统,无论多么复杂,且不需要依靠经验或熟悉的系统知识所构建的直觉,工程师也能有条不紊、客观地研究任何问题。





