


导语|仅需一小步,让文档错误无处遁形。如何借助 ChatGPT 和 OpenAI API 撬开文档校对的大门?希望能为大家提供一个可行的思路。
本文作者:walkercao,腾讯 CSIG技术产品
缘起
本文基于 gpt-3.5-turbo 模型来测试,按照 10000 tokens / 篇,共 200 篇文档的量级来估算,成本大概在 5$(算上测试)。
产品迭代的车轮滚滚转,产品文档的数量动辄成百上千篇。这个时候,还会有过去的“漏网之鱼”在不经意间埋伏你一手。
我们心里不免动起一个念头:
“不如我们把文档重新梳理一遍,将这些错误都揪出来,以绝后患。“
但真正打开文档后,我们不得不直面这些问题:
- 资源投入:对现有文档进行人工检查需要投入大量的时间和精力,可能会影响其他事项的时间安排,且投入不具有通用性和可复用性。
- 全面性与准确性:检查过程中需要兼顾全面覆盖、不重不漏,这对专注力和耐心也是挑战。
- 多语言:对于上线国际站的产品而言,不仅工作量翻倍,无论是用词还是拼写,都会为校对工作带来困难。
实际上不止产品文档,日常的 API 文档、公告、邮件、汇报材料等等都会涉及到上述问题,且必须想办法解决。
总的来说,文档校对是一件人力投入很高、仅满足“基本需求”的任务。说到这,相信看过标题的你也已经知道接下来的故事大概是啥了:求人不如求己,AI 就是底气,我准备借助 ChatGPT 来尝试解决这个问题。准确地说,是借助 ChatGPT + Open AI API 来做。对于我们可能遇到的上述三个问题,都会从一定程度得到改善。
初探 · 校对单篇文档
首先试试直接发给 ChatGPT ,让它帮你纠错,效果如下:
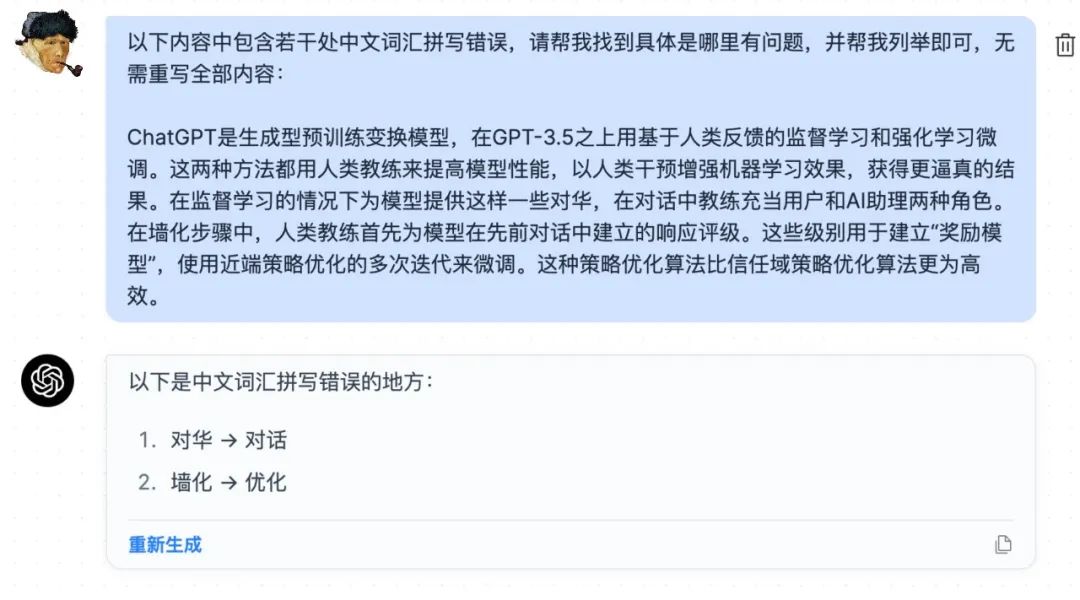
这个时候问题来了,但凡涉及到通用问题的检查,当你的面前摆着 100 篇文档时,一篇篇复制粘贴显然不可取。这个时候我们就得借助一些代码,通过调用 OpenAI API 来完成多篇文档校对的任务。不要觉得看到代码就头疼,你完全可以先让 ChatGPT 帮你写一段调用 Open AI API 的代码……我就是这么干的,如图所示:
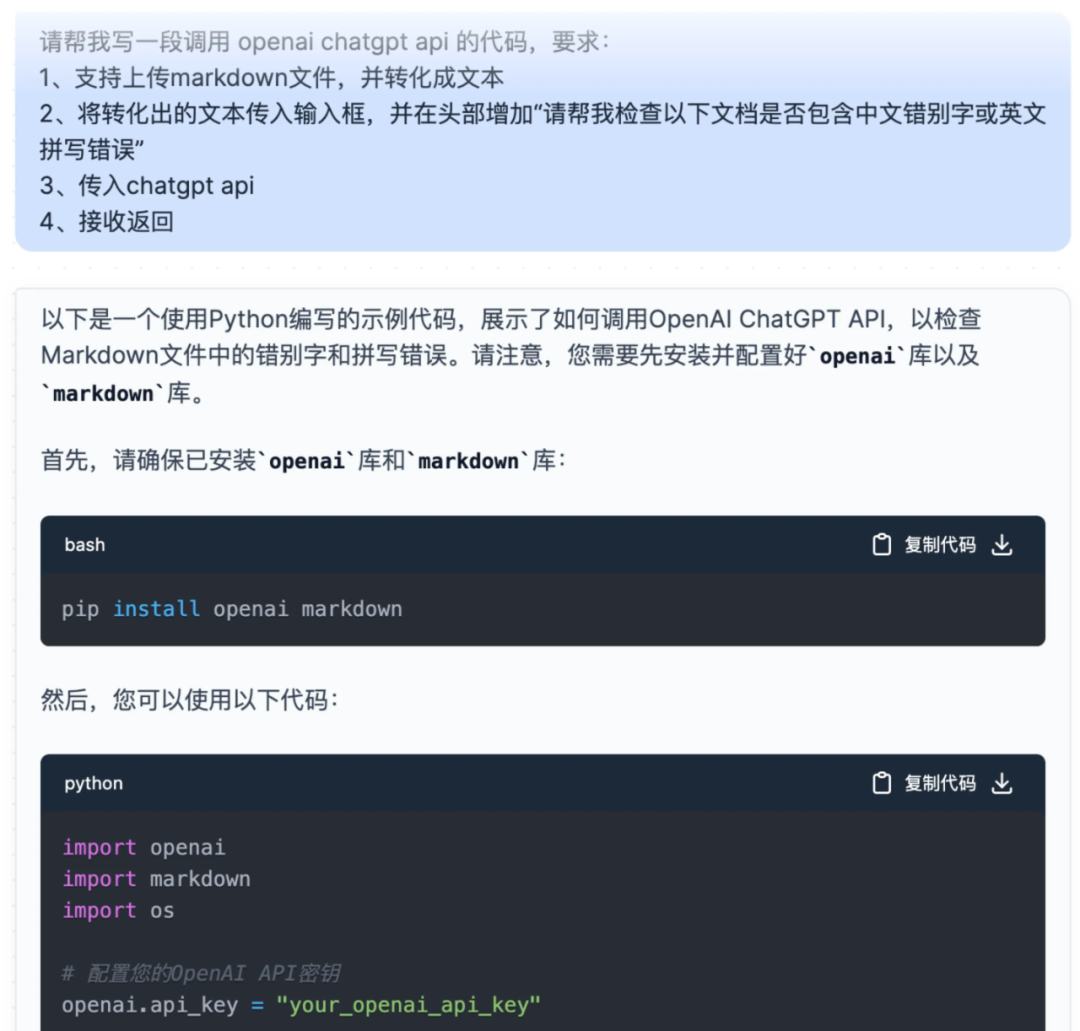
再探 · 校对多篇文档
简单来说,这部分工作,就是通过写代码来实现:
- 文档转文本;
- 将 Prompt + 文本传入 GPT 模型;
- 获得反馈。
还是那句话,求人不如求己,代码部分的工作是借助 ChatGPT 来完成的,我们的需求整体比较明确,总结起来之后,交给 ChatGPT 即可:
| 需求总结 | 编写一段调用 Open AI API 的代码 |
|---|---|
| 需求点1 | 支持将一组文件内容转换成文本(markdown or pdf),或直接从网页解析文本(任选其一即可) |
| 需求点2 | 将 Prompt + 转换后的文本喂入 GPT 模型 |
| 需求点3 | 接收返回 |
当然,即使用到了 ChatGPT 来写代码,总不会一蹴而就,在运行过程中需要不断根据 IDE 的返回来微调代码,当然这步也可以由 ChatGPT 帮忙。举一个简明的例子:
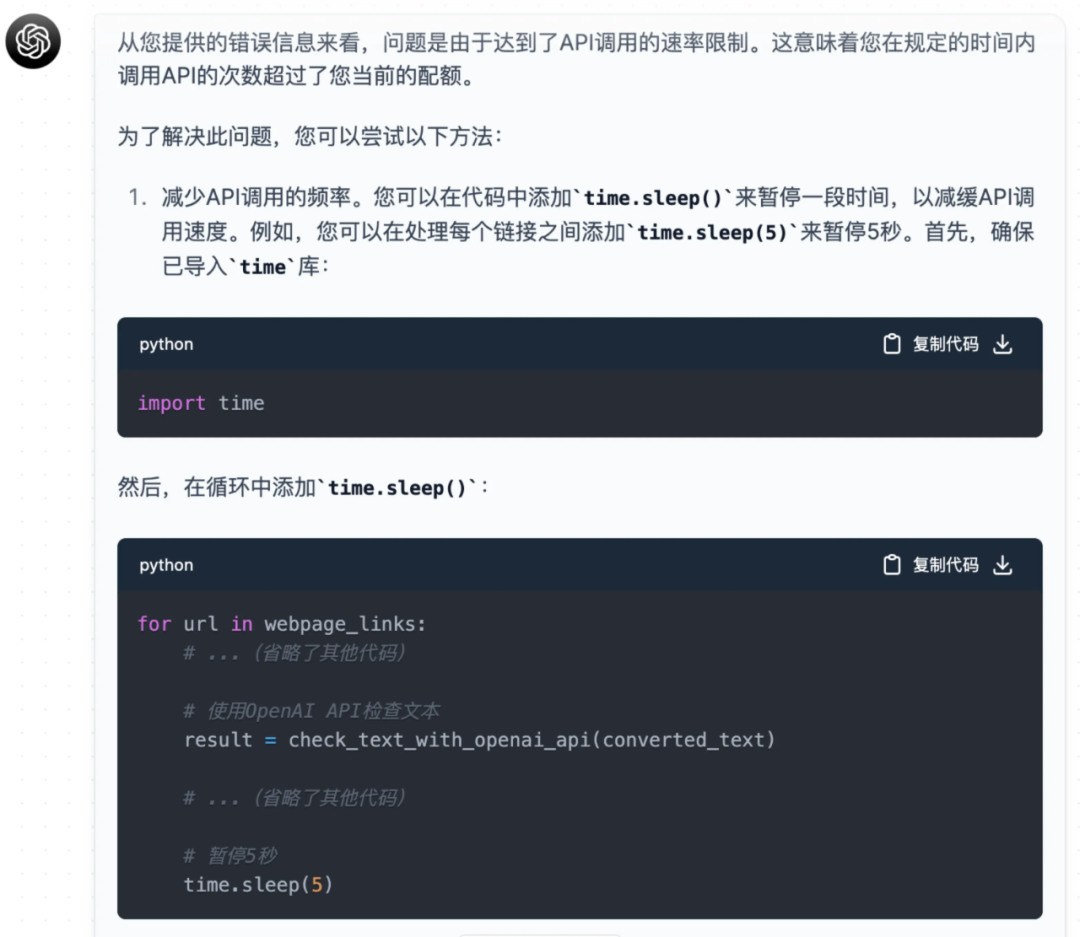
按照初步需求生成的代码,比较典型的一个报错是 OpenAI API 限频:
openai.error.RateLimitError: You exceeded your current quota, please check your plan and billing details.
我们可以将诸如此类的信息传给 ChatGPT ,依此来解决问题,并且它还会“贴心”地为你输出修改后的代码:
类似错误均可以通过这种方式来与 ChatGPT 协作,以完成最终的任务。当然,这个过程中难免踩到坑,下面便是一些避坑指南。
坑 · 之一:文档转文本
原则是简单、代码易理解、文本可操作。
有三种选型,网页爬取、Markdown转文本、PDF转文本。这三种选型在 Python 中都有成熟的第三方库来调用,这里仅叙述我在尝试过三种选型之后,自己的评价:
| 特性 | 网页爬取 | Markdown转文本 | PDF转文本 |
|---|---|---|---|
| 内容完整性 | 高 | 高 | 较低 |
| 无用信息量 | 多 | 适中,处理相对简单 | 较低 |
| 原文件获取 | 网页链接 | 文档编辑工具 | 文档页直接导出 |
这里详述一下劣势
- 网页爬取:包含过多无用信息(文档以外的内容、html 标签等),不处理,徒增 Token 数;处理,代码设计相对复杂。特别是用 ChatGPT 来生成代码时,这部分的 Prompt 让人很是头大。
- Markdown转文本:同样会包含一定量的无用信息,但是处理起来相对简单,主要是这部分信息相似度比较高,可以根据第一次转换出的内容不断迭代,ChatGPT 会贴心地帮你通过正则表达式逐类删除。
- PDF 转文本:转换内容不全面(如果原文档包含“页签”,PDF 可能无法完整呈现对应内容);同样会包含一定量的无用信息。仅在针对产品文档这个场景下,个人不推荐这种形式。
综合考虑,最终我还是选择了 Markdown 。当然,实际应用时根据自己遇到的情况灵活应对即可,也一定会有更优的办法。
坑 · 之二:Token 数量优化
虽然有 Key 了,但费用依旧不低,“降本”是重中之重。在优化成本的过程中,我主要做了以下动作:
- 不在同一会话内完成任务;
- 删减无意义字符;
- 分步骤测试。
不在同一会话内完成任务:事实上是由于 Open AI API 计费的模式带来的问题,文档校验本身不需要上下文信息,所以每次校验任务创建一个新会话即可,完成后关闭,这样在计费时就不会计算上下文信息的 Token 数了。
删减无意义字符:不论哪种文档转文本的方式,必然会带来很多无效字符,如:html 标签、Markdown 格式标签、多余的空格……徒增 Token 数。我在此选择了正则表达式,因为从 Markdown 转换而来的纯文本,其无效信息相似度颇高,不需要太多复杂的正则就可以清理干净。
# 删除不需要的字符
text = re.sub(r'\[|\]|\*|<|>|#+', '', text)
text = re.sub(r'\n\n+', '\n', text)
text = re.sub(r'\\n', '', text)
text = re.sub(r'\n', ' ', text)
# 删除多余空格
text = re.sub(r' +', ' ', text)
# 删除以 " https://write-document- " 为开头的内容及其包含的括号
text = re.sub(r'\( https://write-document- [^)]+\)', '', text)
分步骤测试:主要是转换文本这一步的测试,可以单独进行,待到转换出的文本完全符合要求,再转向输入模型,接收结果的测试。
坑 · 之三:Prompt 怪象
尽信书,不如无书,共勉。
在最终的测试环节,我发现了一个奇怪的现象:我以为表述清楚的 Prompt,结果不能很好地纠错。实际上这里反映出了一个核心问题:Prompt 设计的质量,会直接决定预设任务的完成度和完成质量。
篇幅有限,仅列举 3 个 Prompt:
| 前提:手动为 md 文档中增加了若干错别字 | |
|---|---|
| Prompt 1 | 请帮我检查以下内容是否包含中文词汇拼写错误,后略。 |
| Prompt 1 效果 | 检查出了错别字。 |
| Prompt 2 | 请帮我检查以下内容是否包含错误的字词拼写、语法错误、标点符号错误等,如果没有,仅需告诉我'不包含'即可;如果有,以纯文本的形式告诉我出现在什么位置,以及修改建议,后略。 |
| Prompt 2 效果 | 这段文本不包含错误。 |
| Prompt 3 | 请根据输入的文本内容,找出其中的错误。这些错误可能包括但不限于:1. 拼写错误2. 语法不通顺3. 标点符号错误4. 不恰当的用词或词组5. 成语或俗语使用不当6. 句子结构混乱7. 逻辑不清晰请仔细检查以下文本,并指出其中的问题:后略。 |
| Prompt 3 效果 | 检查出了错别字,但同时列举了更多其他“错误”(未必全都合理)。 |
对于 Prompt 的设计,实际上和产品迭代的思路是一致的,一开始可能我们并不明确要解决问题的细节与边界,这个时候需要从“MVP” Prompt 开始,快速获得反馈,然后根据反馈的内容,对 Prompt 进行有针对性的优化。
最后提一嘴,在测试时还需要关注另外一些限制,本文遇到的情况如下:
- 接口限频:18$ 的 Key,每分钟限 3 次;
- 模型输入的最大 Token 数:gpt-3.5-turbo 单次最大输入 4096 个 Token。
往后 · 来日方长
我想起了学生时期折腾黑苹果的事,多少个无人的黑夜,我孤身坐在昏暗的灯光下,刚把左脚从水坑里摘出来,右脚紧接着踩了一脚泥。如果那时就有 ChatGPT 该多好。
已实现的效果见下图,不但能检查出错别字,还会对其他内容有优化建议。虽然但是,仍有诸多优化点,以更好地完成文档校对的任务,但我目前相信沿着这条路前进准没错。
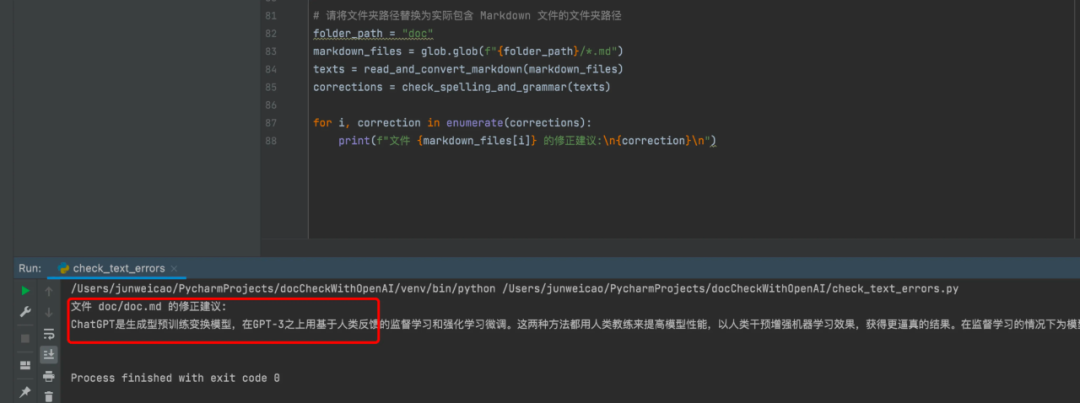
正如本文开头所说,基础的文档校验工作可以说“吃力不讨好”,恰好 ChatGPT 在这个任务场景中能有比较优质的表现,为什么不借此提高效率,转而将精力投入到更多高优的事项中呢?
尾声
特别感谢提供 AIGC 相关服务的团队,在探索 AI 的路上,你们助力我颇多,抱拳拱手。授人以鱼不如授人以渔,本文所述只是一个简单的 demo ,源代码就不放了,欢迎大家一起交流。另外附上一些可能会用到的内容:
- OpenAI Pricing:Pricing
- Azure OpenAI Service:Azure OpenAI Service – Advanced Language Models | Microsoft Azure
- Prompt Engineering Guide:Prompt Engineering Guide | Prompt Engineering Guide
扫码预约,get开播提醒
往期文章:
基于ChatGPT+Stable Diffusion实现AI绘画
点个关注,下期再见👋





