


导语|我不是一个喜欢宏大叙事风格的人,但目前正在发展的技术变革,对于一个普通人而言,或许就是一生中所经历的最大变局了。Perhaps, all we need is more than attention right now.
本文作者:yantao,腾讯用户研究员
文章概览
全文共 13940 字,阅读全文预计需要 20~25 分钟。完整版文章请戳👉:AGI近未来:见证、记录与思考

sd v1.5 Prompt: Sparks of Artificial General Intelligence
这段时间关于人工智能、大模型的信息轰炸实在太多,几乎是每周一个甚至多个breaking news的节奏,每天都在尝试梳理什么正在发生,又有哪些新观点、新应用问世,收藏夹和印象笔记内容数量指数型增加,家里的PS5都已经吃灰一个多月了。
写这篇文章最核心目的是想要帮自己做一个节点性记录,重新温习回顾一遍正在发生的事情,也让自己把目前所看的信息和知识再消化一遍。另外的一个现实焦虑是:如果再不做个阶段性的整理,等忙完手头其他的工作,再有精力码字的时候可能又有很多新的信息要消化和学习了……
混沌过程中,just for the record,把所见、所想先记录下来。本文内容中的观点部分仅代表个人意见,抛砖引玉,欢迎留言一起讨论。
全文目录:
一、关于ChatGPT/大模型/AGI的基础内容推荐
二、几个关键概念和信息的梳理
三、大模型带来了什么变化
四、围绕大模型使用角度的可研究问题
五、长期视角下有关大模型的一些预测
一、关于ChatGPT/大模型/AGI的基础内容推荐
当今时代的信息检索和质量分辨是一种核心能力,非常分高下。目前互联网上关于ChatGPT/大模型/AGI讨论的内容太多,真正有价值、值得认真读的观点和内容是很有限,需要甄别挑选的。这里要提到两个老生常谈的问题:
-
学会阅读。静下心来认真阅读,能够启发思考,有效获取更多的信息。视频/音频形式的内容传递过程过于单向,不利于个人独立的思考和记忆;
-
阅读一手信息。有能力的同学对于感兴趣的新闻/话题尽量去读一手的原文,少看营销号的二次搬运和讨论。
有关本文讨论的话题,以中文互联网内容为例,我会根据内容深入程度和内容形态分别推荐以下三类内容:
1.1 初级入门视频:
B站@YJango 的视频讲解了 ChatGPT 的工作原理、制造过程和未来影响等信息,技术细节和专业名词相对较少,例子多、普适性强,适合全家人空闲时一起投屏观看。
1.2 基础讨论音频:
这里推荐小宇宙上的五个播客内容,分别从技术科普、人文关怀、商业逻辑、创业一线等角度进行深入讨论,音频内容适合通勤途中消化。播客链接中有基础的名词解释,可以在收听前先扫一眼是否理解。
- 大白话聊 ChatGPT
https://www.xiaoyuzhoufm.com/episode/641183b5bb1fc0cb68f810c6
- AI狂飙的时代,人还有价值吗?
https://www.xiaoyuzhoufm.com/episode/641d59168aca9099d7312077
- 如何应对ChatGPT?二级市场闭门研讨会精选
https://www.xiaoyuzhoufm.com/episode/63f5f66e1324e63d1259b079
- AI大爆发:OpenAI极早期历史 ,以及图像领域的GPT moment
https://www.xiaoyuzhoufm.com/episode/64486f68baaef727ec431ff3?s
- 对话王小川:通用人工智能是一次文艺复兴
https://www.xiaoyuzhoufm.com/episode/6442527cfbc05629d3a0ac77
1.3 深入进阶文章:
对于有阅读能力、且对LLM有浓厚兴趣的读者,这里推荐四篇个人认为质量非常高的文章,分别从技术和商业的视角对于大语言模型的能力起源、底层技术、进化历程,大模型的商业前景、市场竞争格局以及OpenAI这家公司本身进行全面“逆向工程”讨论。优质的内容配合上notion的批注,阅读体验不会差,读到就是赚到。
- AI Platforms, Markets, & Open Source
https://blog.eladgil.com/p/ai-platforms-markets-and-open-source
- 深入理解语言模型的突现能力
https://yaofu.notion.site/514f4e63918749398a1a8a4c660e0d5b
- 拆解追溯 GPT-3.5 各项能力的起源
https://www.notion.so/GPT-3-5-360081d91ec245f29029d37b54573756
- 从OpenAI的愿景和技术选择推演大模型生态
https://www.notion.so/OpenAI-b1ccaaeecd77433cbdf4f10855878146#d9be3637e59546229398c7af0acb6bb1
除以上的内容外,直接去看推上的讨论、去读相关领域的paper也是非常高效的信息获取方式。作为一个Social Science背景的半桶水,真的很久没有像现在这样提高对paper内容的关注度了。
接下来我会梳理一些关键概念/信息、讨论大模型带来的变化、从模型使用角度做一些研究问题讨论,并尝试对于未来AGI发展做一些预测。欢迎各位根据目录自取所需,跳转到感兴趣的内容。
二、几个关键概念和信息的梳理
基于上文的几篇深入进阶文章,由于内容太好了,不想只做信息的搬运工,这部分会对与大模型相关的一些关键概念和信息做个梳理和提炼(当然还是推荐去读原文,收获更多)。
在去年12月之前,我对大模型的关注少之又少,只希望通过这部分写作的过程,帮助自己加深对相关信息和概念的理解。如果你和我一样,希望第二部分的内容可以对你有帮助。
2.1 大语言模型 vs 其他模型
目前AIGC的概念很火,但大语言模型(如GPT系列、Claude系列)和目前讨论比较多的AI作图、AI音频、AI处理蛋白质折叠问题等方面运用的模型并不是一个类型,很多在媒体上发声的人并不了解技术,才会把他们混为一谈,实际上不同领域有不同的底层AI模型架构、不同的规模化与应用需求,需要区分清楚再做判断。
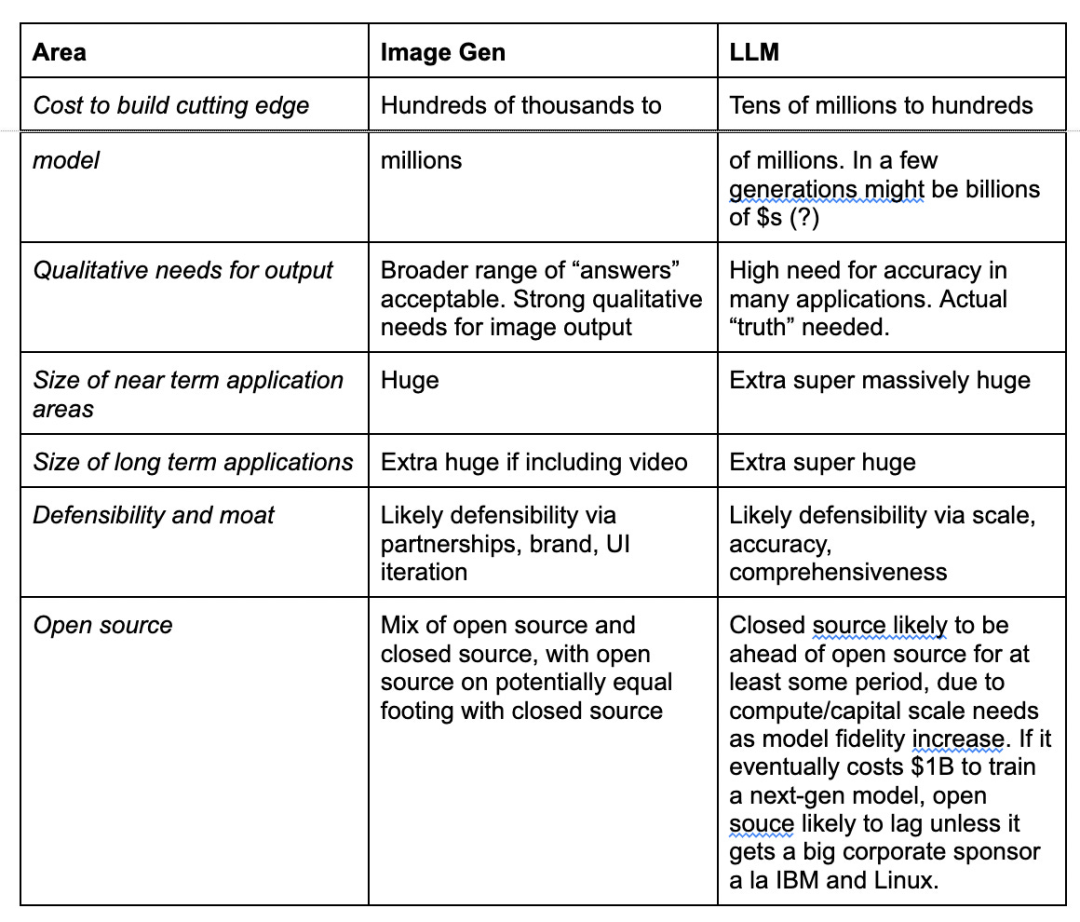
以大语言模型(LLM, 下文均简称大模型)和文生图的模型为例,他们在训练成本、模型参数、质量要求、长远市场空间、打造壁垒方式、开源情况上都有差异,Elad Gil在博文里用表格的方式清晰的展示了两者之间的差异:
2.2 GPT发展到现在做到了什么
符尧在去年的两篇文章非常清晰的展示了GPT在发展过程获得了什么样的能力,这些让人如此重视的能力包括但不限于:推理能力、响应人类指令+泛化的能力、自然语言与代码的生成与理解能力、思维链条与复杂推理的能力。文章中拆解分析了各项不同能力的起源,结论如下图所示:

这里特别提一嘴关于语言模型在编码知识这一问题上的突破:

有趣的是,去年底完成的文章里也从当时的视角里提到了GPT-3.5的局限性,什么需求无法做到,但在AI领域快速发展的今天,随着GPT-4、new bing和plugin们的到来,我们已经拥有了更长的prompt、多模态能力、从互联网进行检索并给出reference的能力、通过plugin的功能检查AI是如何使用其他工具服务,并支持修改与提供反馈……
当然在大模型的快速发展过程中,仍有很多问题尚未被解决甚至解释清楚,强如GPT-4,怎么给提示也算不对5,5,5,1四个数字做24的问题。微软研究院的文章也提到哪怕是早期未交对齐税的GPT-4,在“慢思考”方面的能力(计划、反思、长期记忆等)目前仍有很大的提升空间。
OpenAI自己发布的system card也提了12个细分风险点,从短期的使用过程中遇到的Hallucination幻觉问题,到人类过度依赖AI造成的代替人类思考、信息操控等风险,甚至未来AGI能力过于强大之后的寻求权力(Power Seeking)、AGI间交流等潘多拉魔盒的可能风险。
这些当下的缺陷和潜在的风险,并不能阻止人类继续对于大模型、AGI的研究,毕竟当下GPT-4的能力是实打实看得见的,也带给各行各业丰富的想象空间。只希望未来的发展过程中,开发者能像现在的OpenAI一样交够对齐税,花上充足时间重点针对各种Alignment问题进行大量测试和校准。
2.3 OpenAI的过人之处
虽然事后检验的成功学很无聊,不过在这样一个重要技术的诞生之地,分析是必须要做的事情,Kiwi的团队的这篇分析文章对OpenAI做了逆向工程,从团队的终极愿景出发,分析推演OpenAI发展到现在的每一步过程,并预测大模型未来的发展。
要明确的是一点是,AGI是一个需要大量时间和经费的事情,短视、快钱和刻舟求剑在如今这个重视工程思路的大模型领域注定不会有好结果,OpenAI的过人之处在于在整个AGI发展愿景过程中,保持对技术选择的理性判断并持续付出大量的成本投入,以优秀的战略眼光避开了众多可能通向失败的道路,最终获得了当前的成功和关注度。

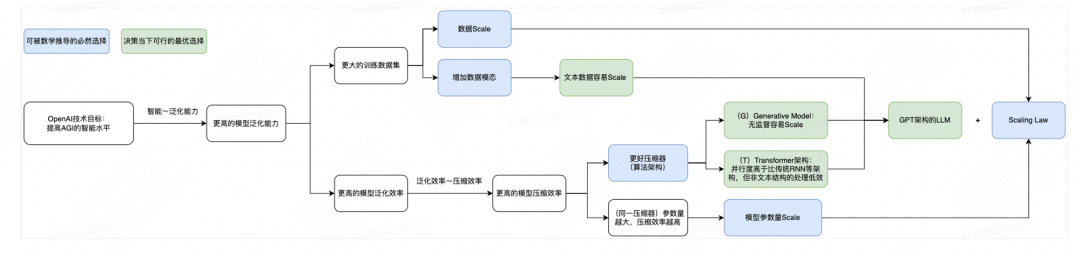
文章中对于OpenAI的技术路径选择部分的推导过程和历史行为通过文字和可视化流程图的形式进行了总结,对于公司未来的技术发展方向预测也从数据层面给出了清晰的判断.

流程图总结:
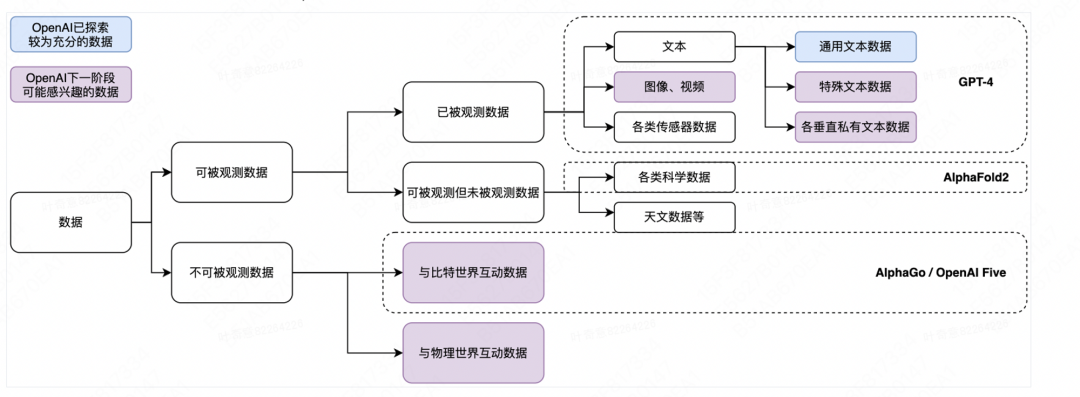
数据层面的下一步:
再一次,推荐感兴趣的同学去花时间读原文和相关reference。
三、大模型带来了什么变化
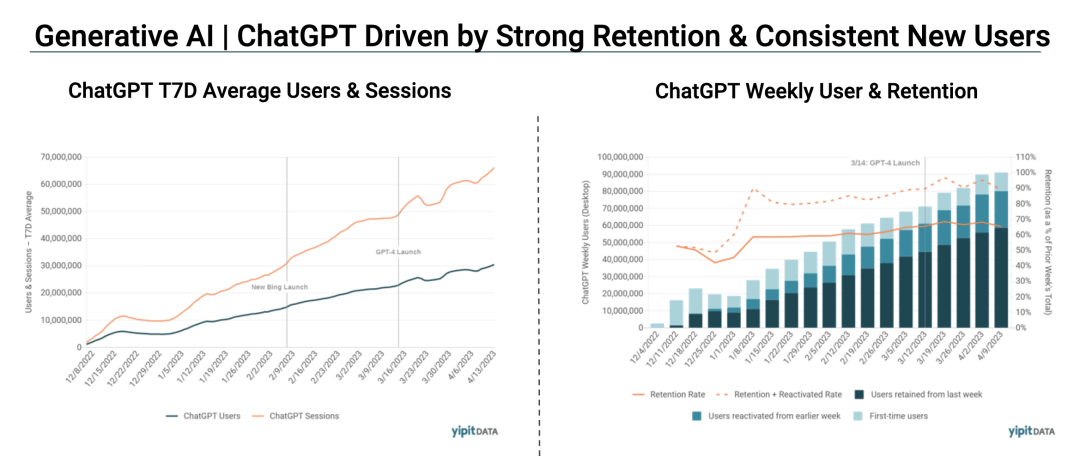
讨论这个问题前,先说一个最最实际的变化 —— ChatGPT已经在成为一个C端的超级流量入口。下图是YipitData有关ChatGPT的周活用户和留存率相关的数据表现,为什么AI的话题这么热,稳定增长的用户量和优秀的留存率通过数字做出了解释。
虽然目前AI领域每天都有新鲜事,但不可否认目前与大模型相关的业务发展仍处于相对早期的阶段,看到不少人会复读“高估的短期与低估的长期”这样多少有些“正确的废话”性质的观点来评价当下AIGC/LLM相关领域的发展,要想真正对大模型带来的变化有较好的趋势性把握,还是需要从与大模型相关的核心维度理解当下正在发生什么。
目前按照大模型的产业结构,可以划分为四个核心的模块:硬件/算力、模型、数据/工具、应用/产品,下文的内容也会围绕这四个维度分别展开。
3.1 硬件/算力:需求量会诞生更多AI垂类的基础设施解决方案
经历过国内移动互联网时代的人或许都还记得,当年的流量费用价格之高。给技术提供基础设施服务支持的平台通常都是在变革过程中获得最多收益的一方:根据硅谷风投A16Z的文章,"Infrastructure vendors are likely the biggest winners in this market so far". 目前大模型相关的产业中,与算力支持硬件与云服务商会拿走50-70%的价值,基础设施提供商是这个目前市场当中最大的赢家。
作为算力领域的纯门外汉,只能从市场角度去做推倒:既然有如此庞大的需求和收益空间,厂商没理由不为大模型领域去做更多更符合当下需求的专业适配产品,OpenAI目前和微软、英伟达的合作只是目前看到的最为成功案例,未来一定会诞生更多大模型/AI垂类的基础设施解决方案。
按照目前的A100价格计算(如果能抢得到的话),规模如GPT-3.5的千亿大模型训练成本至少在千万级人民币以上,加上过程中的各种工程误差,最终的训练成本只会比这个数字高得更多。大家看到国内声称在做/要做这块业务的,可以先把相关算力和硬件资源盘一盘,如果既没有准备设备又没有经费,还在说自研通用大模型的,可以粗暴定义为在诈骗。
3.2 模型:等开源 vs 练闭源,做通用 vs 抓垂类
对于模型层本身,OpenAI目前的普惠策略基本让这个部分基本没有什么油水可捞,如果OpenAI自己在定价方面不做调整,那么其他的大模型厂商一方面要背负高昂的训练测试成本,一方面还要面临与OpenAI的直接竞争,商业化前景堪忧……
目前围绕大模型本身,有两个绕不开的讨论话题,开源 or 闭源,通用 or 垂类,或许十年后这些问题都不再是问题,但在大模型发展的早期,这些讨论是有价值且有必要的。
开源 vs 闭源。对于大模型业务的跟进与研发,这个问题应该是所有决策层都需要面对的。对于这个问题的预判,基本又取决于对于以下几个判断:
- 这一次的大模型,和过去十多年AI领域的深度学习相关模型是否类似,可以在1年左右的时间被开源模型赶上?
- OpenAI目前的工程思路和数据飞轮是否是核心竞争力,开源领域拿什么训练数据集去追赶OpenAI?
- 在大模型的研发领域,开源模式相对闭源而言的优势在哪里?是更省钱还是更省电还是提供给服务客群更多独特的价值?
- 大模型目前的发展处于S曲线的什么阶段?仍处于快速上升期还是已经趋于平缓?趋于平缓的话,开源模型追上GPT的n-1版本,能否满足大部分客群的需求?
- 开源的商业化路径是什么?大模型开发这种对于成本投入要求巨大的事情,开源模式拿什么和有明确商业壁垒和成熟GTM策略的闭源模型竞争?
通用 vs 垂类。目前的一种思路是,既然OpenAI的通用模型这么强,不如放弃通用做通用大模型的思路转而往细分行业赛道的垂直领域进发,做个垂类的大模型解决方案,抢占细分市场…… 这里同样也面临几个方面的问题需要思考:
- 做垂类领域的大模型,还是绕不开算力和数据的问题,你的训练数据从哪来?尤其国内目前很多行业数字化转型都走得磕磕绊绊的前提下,是否有足够多的高质量数据用于垂类模型?
- 相关的细分行业,是否真的需要一个垂类的大模型来解决问题?市场空间是否足够大,能不能收回成本?BloombergGPT在大洋彼岸风生水起,有几个行业的购买力能和金融比?国内的同类Wind/iFinD们卖得好吗?
- 即便数据和市场都不成问题,训练出来的细分垂类领域模型效果如何是必须面对的问题。能不能做得赢现在的通用大模型?如果通用大模型迭代了一个版本后呢?
- 现在对标通用大模型能够有优势,但这行业如此有搞头,保不齐竞对也会去做相关的训练,如果还和大模型厂商合作了,你的垂类模型还有十足的竞争优势吗?
以上这些问题,即便是业界目前也存在争议和讨论,think twice, pick one and go on. 短期内没有人有标准答案,未来不论是开源还是细分垂类,都会有很多工作需要投入,Ilya Sutskever自己在接受采访的时候也预测到未来的大模型工作将会是收拢-发散-再收拢(convergence - divergence - convergence)的过程。
3.3 数据/工具:新工具快速迭代中,做不了大模型的都会去搞数据
在聊具体的应用/产品层面前,还是要提一嘴工具和数据层面的变化,但个人对于这块的积累相对较少,只抛砖引玉,期待更多的交流与讨论。
个人感觉大模型在工具层目前仍处于geeks for fun的阶段,很多中间层的工具仍处于待观察的阶段,即便是LangChain这样在大模型领域具有一定影响力的平台,目前提供的服务方向也在快速的迭代中。不论是围绕prompt engineering的开发框架还是模型评估与优化层面的服务提供,对开发者友好的大模型中间工具层目前看起来是一定会有人持续做的,直到大模型本身完全可以直接用于各个具体场景当中。
数据层面,大模型让数据标注这样的工作有了新的门槛,RLHF 的数据标注不再是落后地区的“互联网民工”就能够胜任的工作任务。以OpenAI为例,数据处理的工作是由很多负责一线预训练和对齐税的高精尖科学家/各领域PhD们共同完成的,其供应商Scale AI同样是高规格接待,找了一批博士们来服务OpenAI的数据业务。
仅从目前的发展看,目前的工作对于人类反馈部分的要求高且强依赖,给大模型做标注也不是什么草台班子喊一嗓子就可以做的,对于数据格式、内容、对应问题和回复逻辑等方面的专业性要求非常高,或许未来做不了大模型的厂商,都会转而去做数据相关的业务。
这也衍生到一个更长远的话题,随着大模型的发展,未来有一天互联网上的优质训练数据总会被耗尽,到那时或许会有专业的公司去研究多模态的合成优质数据,也会有一批企业付费给普通用户和专家用户,给钱让他们提供符合格式要求的个人日常数据。
3.4 应用/产品:现有互联网业务的商业逻辑受到冲击与颠覆
过去VC们投资互联网项目,主要核心投资于“网络效应”带来的垄断,用户因网络效应而来,把社交关系、业务关系和核心数据沉淀在产品/应用层,这些产品抢到了多少核心用户,决定了能创造多少的投资回报收益。
因此很长一段时间里,与用户数相关的各类指标,一直是互联网从业者最为关注的核心数据,日活、周活、月活,次日留存、七日留存、次月留存……仿佛专家产品的数据在第三方榜单上排到了某个位置,就可以高枕无忧了,对于产品/应用本身的创造价值点关注度相对有限,毕竟各家竞品之间创造的价值大同小异。
然而在大模型时代的相关应用,即便是同样面向C端的业务,这一套抢占用户的逻辑也并不那么行得通,大模型应用本身对用户的价值来源于模型能力的提供,这种能力也随着大模型本身的迭代而不断优化。如果依托大模型做的产品应用提供的价值过于单点,应用做得太薄,很容易被大模型自身在能力升级过程中所取代超越,即便如Jasper这样的服务,选对了赛道抢占了早期用户,随着ChatGPT的推出,自身的价值提供不再具备优势,用户自然会用脚投票做出选择。
大型互联网公司的战略布局中经常会提到一个概念叫做“防御”,公司做某业务是为了防御竞对在同类业务上的发力,这里简单举个例子,对于Jasper而言,ChatGPT防得住吗?这些竞争过程中是否出现过以拉人头、抢用户为目标的价格补贴战?价格战打完真的抢到用户的又是什么样的应用/产品,而价格战无效的领域,背后对于用户粘性强相关的真正底层价值又是什么?
最近这两年自己的工作和SaaS有点关联,对于SaaS的关注相对较多。目前整个SaaS行业仿佛进入了当年“互联网+业务”和“传统行业+互联网”的年代,都在讨论有关“AI for SaaS”还是“SaaS for AI”的问题。不管在思路选择上决定以哪种方式去打磨产品/应用,大模型时代的底层商业逻辑到了拼内功的时候,价格战、捆绑销售等小伎俩或许依旧会让产品数据在短期内有喜人的变化,但从长远看给用户提供的价值捕获是微不足道、极易被取代的。
今年2月底Atom Capital整理过一版大模型相关领域的业务方向和标杆团队/产品,随着GPT-4的诞生,目前的应用生态更加丰富多元,试着找到你所在的领域,了解更多的相关信息,知道世界在发生什么,发生到哪一步了,是非常重要的。
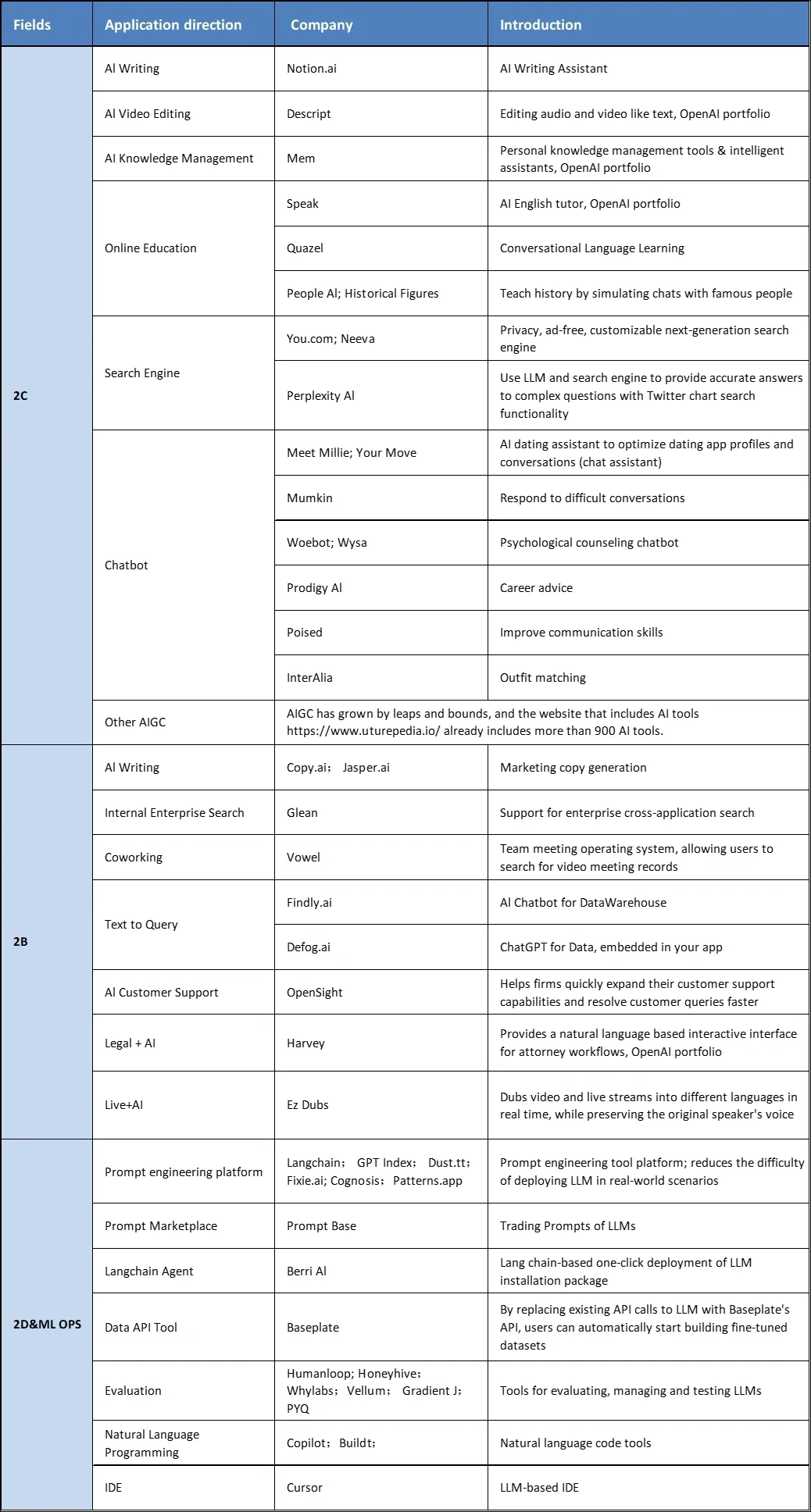
四、围绕大模型使用角度的可研究问题
回到跟自己工作岗位挂钩的话题,在这样一个技术变革进行时的当下,有哪些可以去做的事情?这里从大模型相关应用的使用视角,抛出一些个人视角的思考,与读者交流讨论。
4.1 用户使用方式层面:以三个传播学话题内容的讨论为例
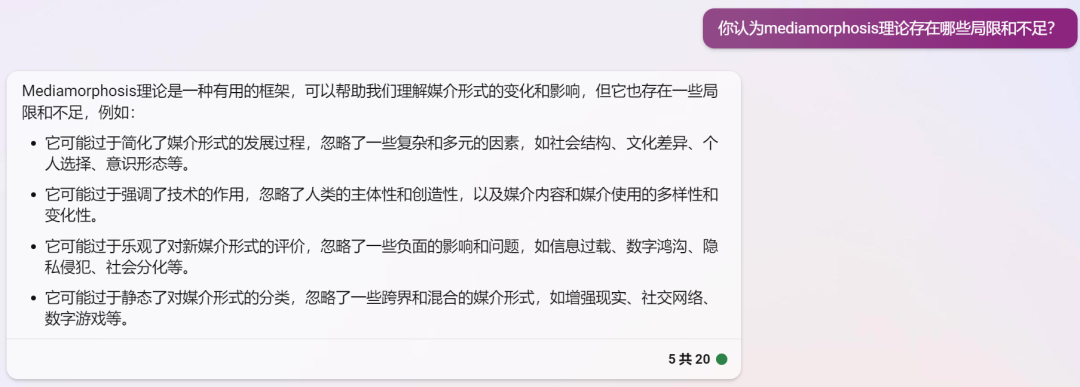
第一个想探讨的问题完全来自自身的知识背景和大模型相关应用使用体验:自从自己通过了new bing的waitlist拿到access后,粗滤统计了下自己在new bing上的使用时长是明显多于Google了,天天问问题不说,还会让他帮忙做阅读理解、举例子做类比,引申推荐相关优质文章…… 感受到GPT和new bing的强大之后,时常会不由自主的在对话中回复"thanks", "awesome",似乎把应用拟人化了 —— 不由让我回到了专业课的课堂,第一次对Media Equation理论这么深有感触。
近期市面上也诞生了不少Prompt相关的教程,分析同一个情景zero shot 和few shot回答的效果差异,大家仿佛都在默认如果向GPT提问遇到了错误的回复,可能不是GPT本身有问题,而是提问者的问法出了错…… 还是以自己的经历为例,上文提到目前GPT-4还不会算24的问题,我一个晚上就尝试了半个多小时提问方式,给了各种hint看GPT是否能够给出正确答案,仿佛打游戏打boss般上瘾。
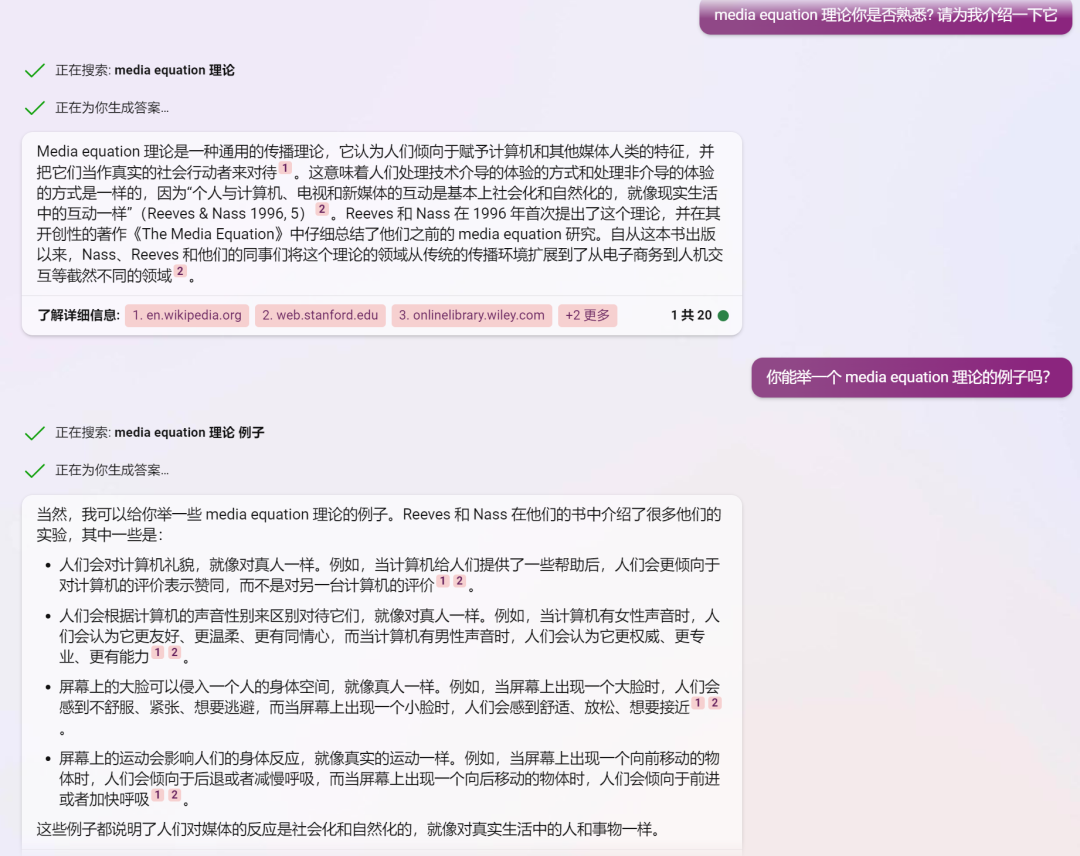
最近看到很多讨论文章会把创新扩散、S-curve等传播学相关的内容带上,如果把大模型相关的应用作为一个新的媒介形态,这里补充三个传播学相关的理论:讨论媒介形态演变的Mediamorphosis、讨论媒介拟人化的Media Equation以及与大模型语言表征密切相关的Representation,直接用new bing的对话截图来呈现,喜欢fact check的同学也可以看看new bing的回复有没有什么问题。
Mediamorphosis - 媒介演变理论




Media Equation 媒介等同理论
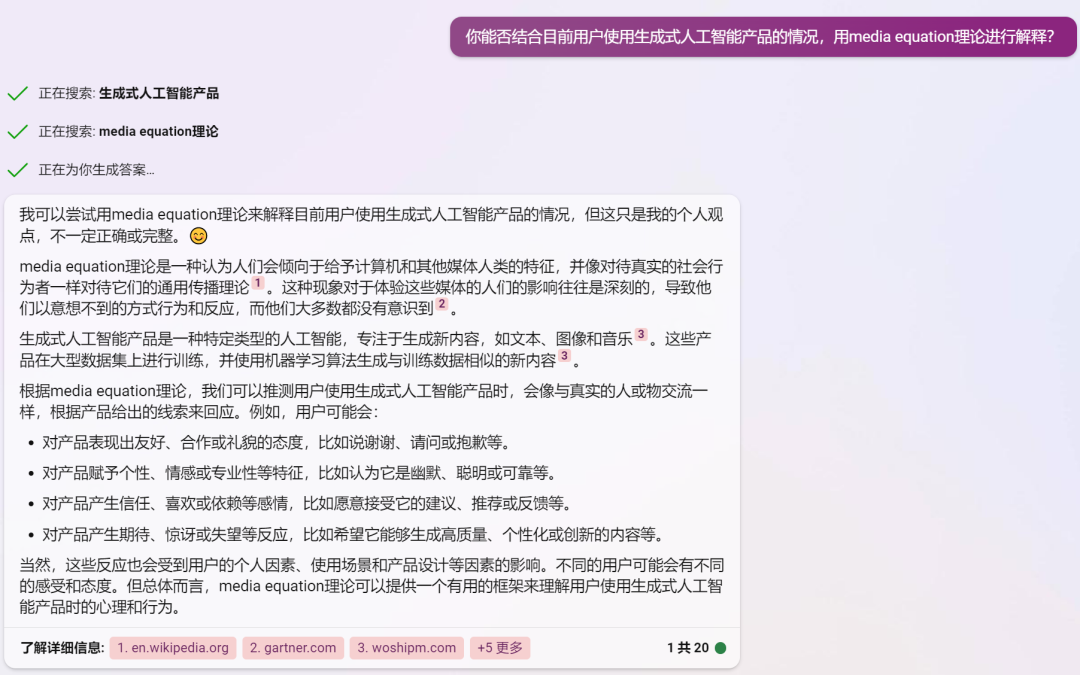
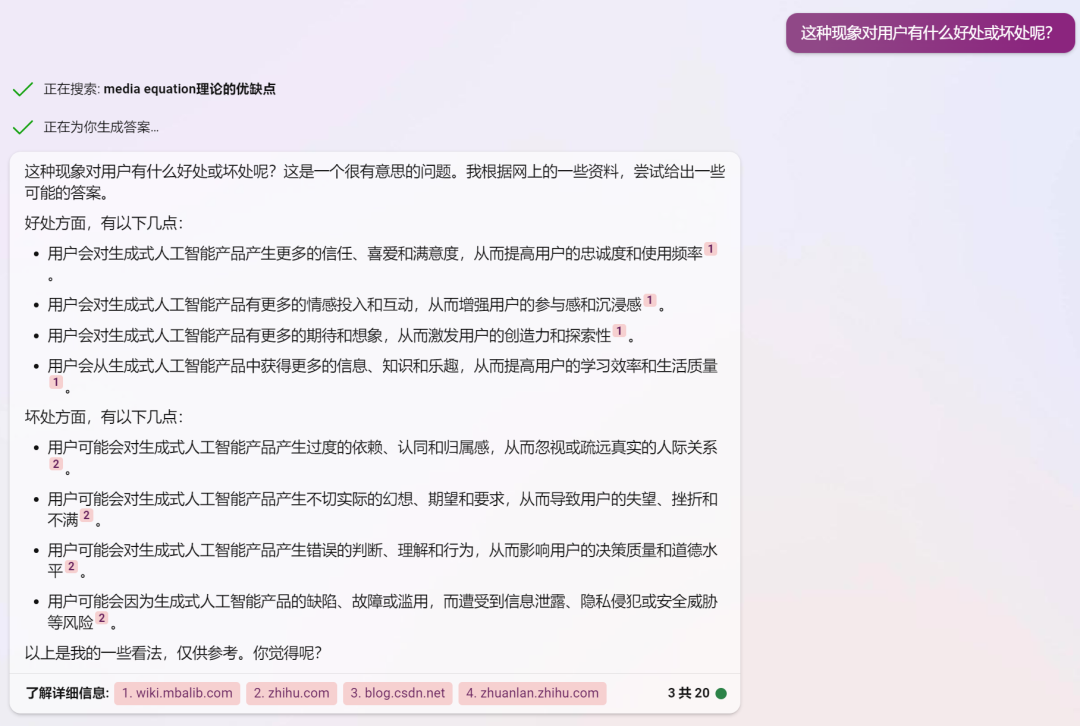
Representation 表征理论
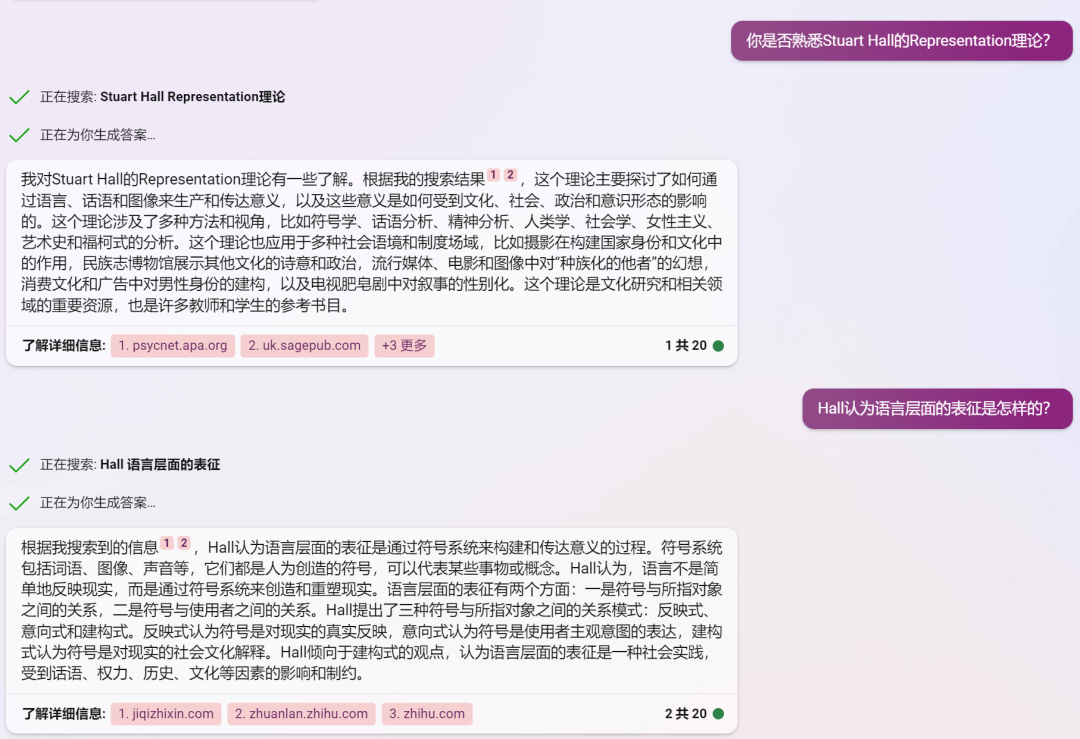
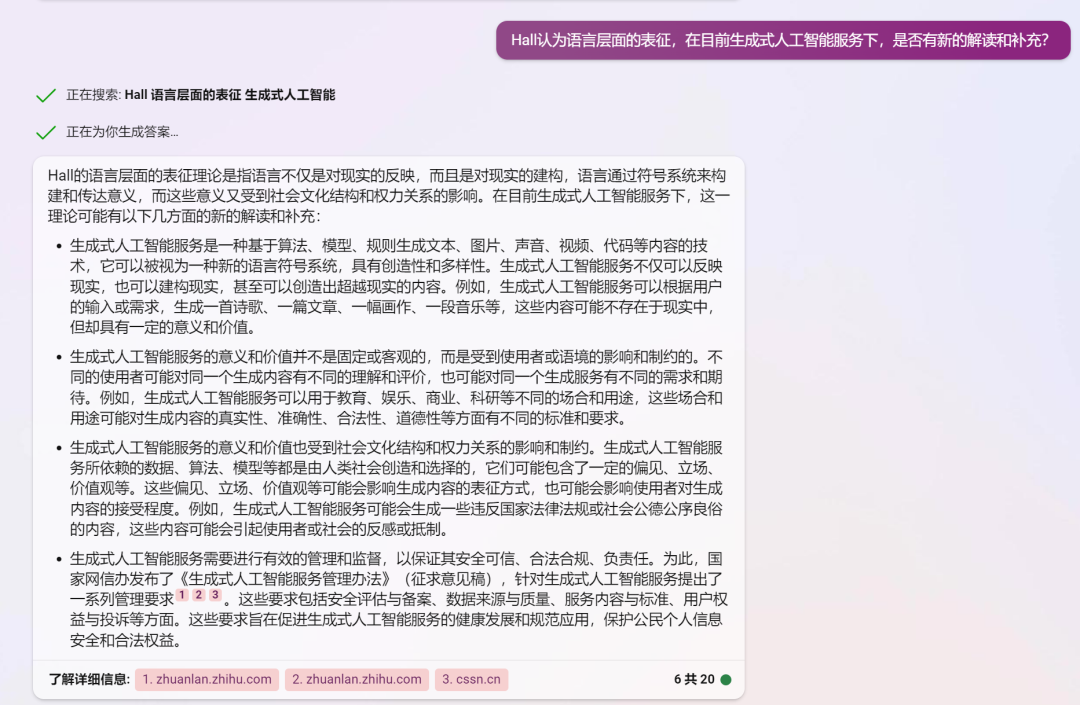
于我而言,眼前的这一切实在太过于美妙。
4.2 产品人机交互层面:GUI or LUI or something new?
目前的一个共识性观察:目前大模型及其应用层面技术发展的本质变革在于让自然语言为媒介的人机交互系统成为了可能,从而有机会从产品交互设计层面重构当下大量的软件逻辑,目前国内外大量的AI+具体软件的发布会包装案例也是在延续这一思路。
看到有机构回顾罗列了科技发展史上的多轮变革,每次伴随技术发展带来的最大机会,并不是技术本身的诞生,而是基于新的人机交互界面而做出的新一代应用诞生。
互联网与浏览器与网页、移动互联网与App Store与App都是如此,而GPT-4出现之后,最大的机会点或许也在于谁能准新的人机交互形式,为用户提供更好的服务。未来的AI应用究竟是GUI(图形用户界面)、LUI(语言用户界面)还是一个更新颖的界面场景,值得所有从业者去研究发现。
即便是LUI本身,ChatGPT目前的文本框问答对话形式确实易用性拉满,但一个自然语言的人机交互框应该长什么样,需要有哪些附加功能,目前也并没有最优解。

An interview with Midjourney founder David Holz
这里补充一个MidJourney创始团队的David Holz在去年八月接受的一场访谈,对于AIGC应用这样的新领域,用户在最初是不知道自己需要什么,也不知道产品/应用可以做到哪一步的,因而也只能提出一些现在看起来非常初级的需求指令。
但随着MidJourney与Discord社区联合,用户能够实时看到他人的创作,激发自己的灵感与创造力。从结果倒推,目前Midjourney在AIGC画图领域的爆火,与成功的交互策略也是分不开的。
依托Discord社区的产品交互界面,无疑是向所有新用户提供了最生动易懂的产品使用文档。交互形态的变化也给大模型时代的产品经理提出了更高level的要求,不仅需要具备传统的产品经理相关能力,理解把握需求,还需要去探索和领会大模型能力的边界,以便更好的借助技术本身来提供更好的解决方案。
4.3 产品力层面:当前C端/B端的决策路径和评价维度是否仍然适用?
在当下的产品力评价体系当中,交互往往只是用户体验视角的其中一个细分的维度。未来大模型应用层的相关产品与服务,要怎么评估从一个产品是否具有好的产品力 —— 换个角度或者说应用具备什么样的特性,更容易被目标用户所青睐?个人觉得现有的传统消费品、互联网产品/服务的评估维度都会发生变化,当前不论是C端还是B端的决策路径可能都需要重新审视。
这里需要强调的一个很主观的观点是:目前看到的很多关于应用层的用户决策、用户反馈侧的讨论,方向都不太对,都过于强调大模型应用于现有的软件/服务的比较,拿一个beta阶段的产品去比成熟期的产品…… 上文也提到了应用层“价值捕获”这一概念,从提供价值的角度,大模型、AIGC相关产品应用的使用与否,对于有特定价值需求的用户而言,只有用哪款大模型产品的问题,而不存在去和现有传统软件服务比较的问题。
以本文的封面图设计需求为例,我自己不会做设计,现在有了text to image的服务出现后,我不会去考虑是去请个设计师帮我画图 or 在网上找一张现成的图片,而是会直接选择将我想要表现的概念输入各个文生图的model,看看哪个效果更符合心中所想,直接使用。
在这个场景下,这里大模型提供的价值让我无需考虑非大模型服务的方案,或许会有人说这个场景并非是一个专业性要求程度高场景,但一方面大模型应用目前仍处于迭代进化过程中,另一方面市场上的需求场景又有多少是具有较高专业性程度的呢?
进一步引申有关“价值捕获”带来的用户决策因素的变化,C端用户的强粘性可能被新产品的性能提升所打破,企业用户对数据安全性、隐私保护等维度的严格要求也可能会因为大模型产品带来的生产力优势被重新评估重要性与优先级。
而当前专家们讨论较多的有关大模型生成内容的“可预测性”以及“真实性”相关局限,这些问题似乎在目前的互联网环境下早已不是多数用户决策过程中重点关注的问题,毕竟短视频用户早已不知道自己会刷到的下一条是什么,互联网内容平台上用户天天都被各种假新闻假消息投喂,这些因素丝毫并没有影响相关产品的持续火热。
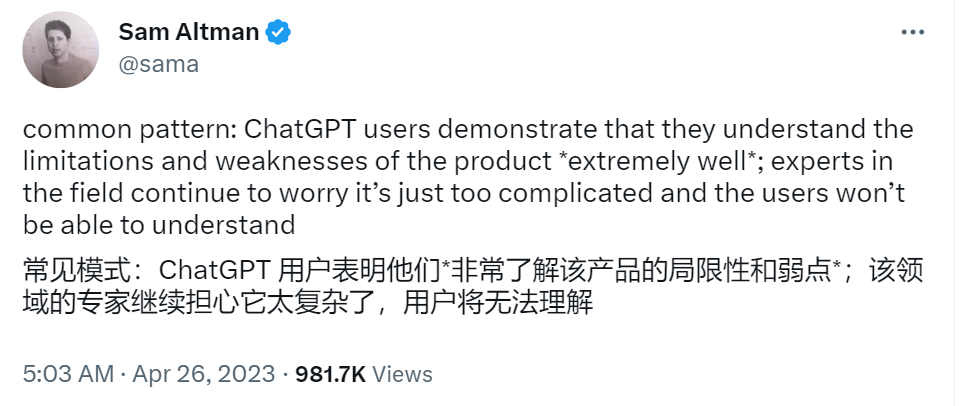
4.4 信息分发层面:大模型会给这个已经极化的世界带来什么?
虽然大模型在内容真实性层面的局限或许并不影响大众对其相关应用的持续使用,但作为一个对新闻专业主义有自我价值坚持的互联网生态观察者,我对于大模型在信息分发层面可能带来的变化非常感兴趣。
一方面,因为自然语言交互门槛低,内容消费领域的用户规模会有所增加(谁都能快速问问题,获得一个像模像样的即时回复反馈),甚至有可能出现新的用户群体(老人、儿童或许不太会操作GUI界面,没耐心刷信息流,但张嘴说话是没什么问题的);另一方面,在这个处处需要站队、强调正确性的极化世界,人类对社交媒体推荐算法的内容消费都没整明白,天天活在信息茧房里,那么依托大模型的信息分发方式会不会进一步加剧当前世界的极化现象?
2012年,Nature有篇研究讲的是社交媒体对于美国民众参与投票行为的影响,当时会觉得影响比例并不高,现在这种动不动就51%vs49%的现实环境,再小的影响都有可能引发蝴蝶效应。
如果未来依托大模型的内容分发渠道真的被多数人拥抱并接受,这里补充一个人工智能领域的有效市场悖论的讨论,对于分析成本较高的人来说,大模型提供的内容如果已经足够了,大家的观点和价值观是否能在一定程度上有所趋同?

4.5 评估体系层面:怎么科学的度量一个大模型的综合能力?
人类可以通过各种考试,针对某一个领域对群体做出筛选和评价。但对于一个通用的大语言模型,要怎么科学的评估这模型做的怎么样,对比竞品是好是坏,好在哪差在哪,目前并没有一个被广泛认可的科学评估体系,更不用说一个核心的北极星指标去粗暴评估各家的差距,对于评估体系似乎所有的团队都还处于摸索和讨论中。

微软的那篇关于GPT-4的测评paper提到了他们在评估大模型能力时基于1994年国际共识智力定义,选择了一些维度来进行评估与实验,但并没有给出具体的measurement方法。
目前市面上也有不少用于测评的公开数据集,目前的这类测评方式一方面过于局限于NLP的领域,并不能很好的评估大模型在连续对话、思维链和复杂问题推理等方面的能力;公开的测试数据集是否会出现抄答案的作弊行为也是测评公正性的风险隐忧;此外大模型的回答是碰巧正确还是多次测试均能正确回答,同一类问题的正确比例目前也没有被多数测评重视。
Vicuna团队的思路是用一个高级的大模型(GPT-4)当裁判来测评两个不那么高级的模型(Vicuna和ChatGPT),从测评的客观性上似乎提供了一个可行的思路,但数据集本身还是需要由人来准备,他们自己也在发布的文章里写到“According to a fun and non-scientific evaluation with GPT-4. Further rigorous evaluation is needed.”
未来能不能有一个在大模型评估维度的全面性、泛用性方面均在水准以上的测评体系,能够对普通的用户做到评估易用、结果呈现直观,是所有LLM研究团队需要攻克的难题。
这里需要给目前看到真格基金做的Z-Bench中文测试集点赞:Z-Bench 1.0 by 真格基金 - 麻瓜的大语言模型中文测试集;虽然自称是麻瓜测试集,但从中文测试角度给出了非常有趣的测评视角和实际案例。(制作人员名单里还看到了PeakJi的名字,作为当年还在团队内推荐过Magi的早期使用者,不知道他看到目前Google的新产品名称作何感想……)
五、长期视角下有关大模型的一些预测
5.1 大模型相关研究还有大量待推进工作
第一个预测先引用一篇调查性论文——《Eight Things to Know about Large Language Models》,作者Sam Bowman教授work for NYU和Anthropic,用一篇文献综述性质的paper梳理了目前有关大模型的研究和发展情况,目标受众群体并不局限在大模型领域的研究者,而是希望普通读者也能理解文中的内容。文中的八条结论都有cite他人论证的详细出处,具体内容如下图所示:

此外作者也基于现有的研究内容,提出了一些个人观点预测:

如果有基本的英文阅读能力,非常推荐大家去读原文,找自己感兴趣的部分去看进一步的相关文献。比如尝试去理解文章中提到的“人类在某项任务表现并不是大模型的上限”、“大模型并不一定会表现开发者或训练文本中的价值观”、“大模型的开发人员对于其开发的内容影响是有限的”等观点,比看国内营销号的一惊一乍有意义多了。
简言之,现如今我们对于大模型的了解还非常有限(看到专家都不懂,普通人是不是不那么沮丧和焦虑了……),还有很多工作有待推进和解决,开始学习相关领域还不算晚,或许不久的将来我们能看到更多研究层的突破性进展。
5.2 平行世界下大模型发展不如预期的三点可能原因
虽然文章以AGI近未来为题,个人也非常相信大模型在两年内会进一步普及、创造更多的价值和变革,但如果大模型应用并没有如理想情况下发展,reliability层面的问题或许会是最主要的原因。
现如今的大模型在思维链的引导下推理的效果是令人欣喜的,但复杂任务的每一步推理都是有一定概率发生误差的,一旦出现多步误差,最终的结果可能就会有指数级的偏差。最近大热的AutoGPT在复杂任务处理上也放大了这个问题,Ilya Sutskever在最近采访里也提到了自己对于大模型的信度层面担忧:
If I had to pick one and you were telling me — hey, why didn't things work out? It would be reliability. That you still have to look over the answers and double-check everything. That just really puts a damper on the economic value that can be produced by those systems.
除了信度问题外,安全层面的问题似乎也可能成为大模型的发展拦路虎,大到网络安全、博弈攻防,小到所有模型使用者的数据安全问题,都可能会成为服务无法普及的重要因素,本身对于网络安全更重视的企业和团队在大模型的开发、应用进度上也会处于更领先位置。
另外一个现如今被众多大模型开发者和early adopters容易忽略的方面是应用层的易用性问题。贾扬清最近在Podcast提到Tensorflow和PyTorch的比较,提到了用户体验侧的反思,什么服务才能真的被大多数小白用户认可。
AI架构尚且如此,大模型的应用层面,易用性问题会被放大更多,ChatGPT自身已经给所有人提供了现实教育 —— 好用的应用才能带来大量用户和关注。去Google Trends比较下GPT-4发布以来,有关AI Agents的讨论或AI framework 的声量,目前仍处于“自嗨”的阶段,这些自嗨虽是必要的,但仅有自嗨是无法crossing the chasm把技术推广到大众的。
5.3 互联网内容的平均水准会有所提升,精英主义的自留地会被挤压
随着ChatGPT和相关镜像在国内外的普及,社交媒体上内容的平均质量会随着AIGC的广泛应用而有所提升,从整体趋势上看,目前大量的“废话文学”、“营销号洗稿”的内容生产将会快速被GPT生产的内容替换,质量底线上能够得到一定保障,从而提升互联网整体的平均水平。
针对文字内容侧的AIGC,目前看到的讨论大多都集中在市场营销、运营消费类相关,强调AIGC的背景下生产力如何获得了提高,给这些原有工作岗位上的一线从业者带来了多大的冲击。但个人认为在内容生产层面,真正的冲击远不止于一些岗位的员工丢了工作那么简单(虽然从目前趋势看下来,这是必然会发生的事情);而是对于优质内容的评价“鄙视链”被打乱了,精英主义者们不再能够以俯视视角指点江山,数落当前内容生态下的种种问题……
AIGC的广告内容、营销文案就算写得再好,对大众的影响也是有限的,毕竟一个人每天去看广告、营销的时间不会太长。可AIGC生成的信息流内容、文字作品等系列消费类内容创作,随着生产力的提高充斥在互联网各大媒体渠道当中,当下对于优质内容、创新内容的评价标准可能都要被重新思考和定义。
初中的课本里就会写“生产力提高可以促进社会经济的发展,满足人们日益增长的物质和文化需要,推动科技和文化的进步”,当AIGC使得内容创作者(暂且不讨论利用AIGC生产内容的人能不能称得上“内容创作者”)们可以花费更少的时间产出更多的内容后,单位时间内可以生产的内容注定会变得更多,按照大模型现在的内容创作水平,即便只有1%的内容是符合当下评判标准的优质内容,这也是足以让精英主义者们感到恐慌的事情。
5.4 未来一段时间会出现非常多有关形而上的话题讨论
“AI 一开始是理科生的问题,后来还会变成文科生的问题。甚至可能会经历一段文科生都不够用的时期。当然,最后还是理科生的问题。”
引用TK教主在微博上写下的一段内容,深以为然。“文科生问题”在不同的时代有自己的价值使命,伴随这一次的技术发展变革,我越来越觉得一些形而上的讨论是必要且有意义的:在“GPT会不会取代我的工作”、“人工智能会不会毁灭人类”等问题被反复炒作的时代,高质量的形而上话题讨论会起到开导、启发的作用,帮助个体疏解、缓冲技术变革带来的社会伦理、价值体系的冲击。

从技术层面,Sam Altman早在去年2月就在推上有回应过关于GPT是否具有意识的讨论,从形而上的角度进一步衍生这个话题讨论 —— 人工智能所产生的内容属于是物质还是意识,我尝试问了GPT4和Claude+,他们分别给了我这样的有趣答案:


See? 如果不局限在一个现有的哲学世界观视角,把思路打开会有很多新的思路。
5.5 传统上升通道会越来越窄,能力模型会向学习和思辨能力倾斜
扯完形而上,再来看一个对个体的具体影响问题。今年3月,沃顿商学院和OpenAI合作发布的有关大模型对于美国劳工市场影响的论文GPTs are GPTs。这篇paper的核心发现到现在还时不时被国内各种媒体引用和讨论,虽然大部分人并没有认真去读里面的研究方法和论证过程。
作为一个部分工作内容是论文里提到的可以被GPT完全exposure的Survey Researcher,如果要安慰同行,完全可以说这篇论文的绝对数据参考意义有限,毕竟论文里基于工作任务的框架只是对具体职业的简易刻画,职业并不等于把多个工作任务粗暴相加;论文里对于GPT能否期待人类完成某项技能的数据也是少人工、多机器标注的数据,往往脱离了职业具体场景,数据质量有限(写作技能为例,写小说、写报告和写营销号文案,task一样,工作要求和评价标准差异是巨大的)。
虽然这篇paper是存在问题,但这不代表GPT就不会取代人类的工作岗位了,大模型的能力足以让它在很多工作任务场景上达到相对能用、甚至优秀的水准。很认可推上用户fin把AI“取代”人类职业的话题引入“容错率”概念的思路,而不是单纯的从人类的能力视角(教育年限、技能/创造力、从业经验等)去分析,毕竟AI的取代过程并不会按人的能力决定。
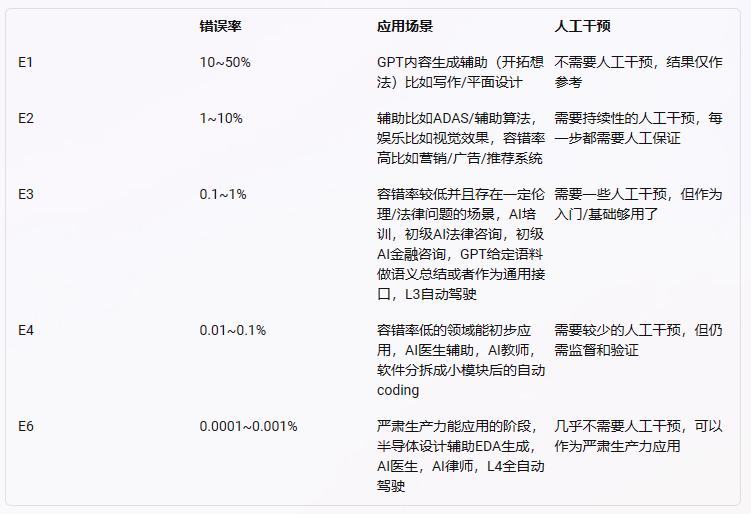
目前GPT-4的错误率处于E1~E2这个水平之间,因此相关的应用场景还是需要一些人工的干预和校验,确保交付结果的稳定性。即便如此,目前的错误率水平,也能够让很多企业乃至整个社会传统的上升通道越来越窄,过往10个人的活现在只需要5-8个人就能做完并不是什么暴论,对于还坚守在岗的个体,能力模型的要求也一定会发生变化,这里或许也会有一些新的机会点平等的给到每一个接触到大模型的人。
老实讲我也不知道未来会变成什么样,但比起一批从业多年,工作方式和思维方式相对固化的人来说,下一代generation对于大模型应用的使用有无限可能。这个月有机会和南科大的学生做了一场交流,聊到ChatGPT相关的内容时,在场所有人都表示目前已经用起来相关的服务,还被同学问到大模型这么强大,现在还有没有必要学basic skills。
我当时的回答是先去学着理解本专业的基础,理解了才有可能形成自己的思维判断。在这样一个技术发展的时代下,对于个体而言,快速学习和思辨的能力优先级会变得极高:一个新问题来了,要能够快速消化各种工具带来的新信息,即便这些信息不是你之前就掌握的知识内容;一堆新信息摆在面前时,要能够快速分辨真伪,思考判断出哪些内容是对自己最有帮助的。
5.6 国内会跟进大模型,也会遇到阻力
各种渠道看到的一个业界共识是:国内一定会做自己的大模型。毕竟这不止是科技发展/竞争层面的议题,也是国家安全层面的核心议题,一个变革性的新技术能否自主可控可以影响太多社会经济层面的问题。
但国内要真的做出能比肩GPT4 or 3.5的大模型,来自内外的阻力会非常多,上文提到的来自算力和工程化能力挑战暂且不多赘述,在新时代的背景下大模型的研发会面临自上而下和自下而上的各种质疑和挑战,想在不出事的情况下稳妥的开发,做出一个国内市场做出一个用户规模现象级的大模型应用,能想象到的黑天鹅事件不要太多……
明确了方向总比无头苍蝇乱撞要好,我个人是抱着一个短期不乐观、长期不悲观的心态去看待国内的大模型发展,但这个发展过程中一定会出现很多民科神棍、黑作坊和诈骗集团们,警惕不要被唬住,要学会分辨PPT和productive work的区别。GPT系列产品就像一面用户友好的照妖镜,只要你有access,就能够自己用自己的方法体会差距,做出评价。
写在最后
今年四月份,OpenAI 内部的大管家Greg Brockman在TED上说了这么一段话:
“I think this is something we should all reflect on and think about as we consider how to integrate these systems into our world. And one thing I believe really deeply is that getting AI right is going to require participation from everyone.”
最后,向所有读到这里的人做一个呼吁: 先去体验。把大模型相关的产品、服务用起来,感受它在生活和工作学习中带来的变化,然后在自己所在的领域尝试贡献一些属于自己的反馈与讨论,AGI的近未来需要每一个人的参与。
目前AI领域的事情发展的太快,本文所有的预测/观点性内容可能都是错的,需要自己去判断、证伪,提高阅读和信息收集能力,没有合理的逻辑推演和事实证据的前提下,谁都别信。
戳
获取更多优质免费的研究资源库
Reference:
从OpenAI的愿景和技术选择推演大模型生态
https://www.notion.so/OpenAI-b1ccaaeecd77433cbdf4f10855878146#d9be3637e59546229398c7af0acb6bb1
深入理解语言模型的突现能力
https://yaofu.notion.site/514f4e63918749398a1a8a4c660e0d5b
拆解追溯 GPT-3.5 各项能力的起源
https://www.notion.so/GPT-3-5-360081d91ec245f29029d37b54573756
AI Platforms, Markets, & Open Source
https://blog.eladgil.com/p/ai-platforms-markets-and-open-source
探讨关于ChatGPT的五个最核心问题
https://docs.qq.com/doc/DQ0plY0JDbXFKUmtU
AI Safety: Technology vs Species Threats
https://blog.eladgil.com/p/ai-safety-technology-vs-species-threats
GPT-4 System Card | OpenAI
https://cdn.openai.com/papers/gpt-4-system-card.pdf
Who Owns the Generative AI Platform?
https://a16z.com/2023/01/19/who-owns-the-generative-ai-platform/
The Latest Trends and Opportunities after ChatGPT
https://atomcapital.xyz/f/atom-capital-the-latest-entrepreneurial-trends-opportunities-an
Prompt Engineering
https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/
Eight Things to Know about Large Language Models
https://arxiv.org/abs/2304.00612
大白话聊 ChatGPT 直播逐字稿
AI狂飙的时代,人还有价值吗?
https://mp.weixin.qq.com/s/7H1FrwbQvsh0HD9z90L0wg
GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models
https://arxiv.org/abs/2303.10130
Sparks of Artificial General Intelligence: Early experiments with GPT-4
https://arxiv.org/abs/2303.12712
Machine learning & cybersecurity: how is ML used in cybersecurity
https://www.crowdstrike.com/cybersecurity-101/machine-learning-cybersecurity/
为什么所有人都应关注ChatGPT
https://www.bilibili.com/video/BV1MY4y1R7EN
贾扬清:三个基础假设
https://mp.weixin.qq.com/s/jC-_B_arDpm1dsEmJLZYIw
The Age of AI:拾象大模型及OpenAI投资思考
https://mp.weixin.qq.com/s/AxX-Q7njegNTAxMkYFwsfA
LangChain:Model as a Service粘合剂,被ChatGPT插件干掉了吗?
https://mp.weixin.qq.com/s/3coFhAdzr40tozn8f9Dc-w
The inside story of ChatGPT's astonishing potential | Greg Brockman - TED talk
https://steno.ai/ted-talks-daily/the-inside-story-of-chatgpts-astonishing-potential-greg-brockman
Ilya Sutskever - Building AGI, Alignment, Future Models, Spies, Microsoft, & Enlightenment
https://www.dwarkeshpatel.com/p/ilya-sutskever#details
An interview with Midjourney founder David Holz
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
https://arxiv.org/abs/2304.13712
# 腾讯技术直播 #
腾讯工程师分享技术干货:

扫码预约,get开播提醒
往期回顾:





