本期嘉宾
周艺超 腾讯QQ影像中心工程师
周艺超,腾讯QQ影像中心资深应用开发工程师。入职腾讯后负责超级QQ秀的智能捏脸相关的研发工作,2022年开始负责小世界AIGC相关的技术研发和产品落地,主要负责《异次元的我》、《魔法画室》等活动的算法开发、工具架构搭建、AI应用落地等相关工作。加入腾讯前从事虚拟人生成、人脸编辑等领域相关研究。

主持人
田超 腾讯云企业中心总经理
田超,腾讯云企业中心总经理、音视频应用平台总经理,负责腾讯云用户增长、DNSPod业务以及企业应用相关产品。同时也是资深用户增长专家,大数据技术专家,曾任应用宝增长平台总经理,摩拜单车技术副总裁。长期致力于对企业数字化相关研究。
1
田超:最近AIGC的热度居高不下,除了ChatGPT,最火的莫过于AI绘画。其实在去年年底,QQ影像中心就上线了一个AI绘画《异次元的我》,不仅在QQ小世界话题内浏览量上亿,海外热度甚至还一度超过了当今最炙手可热的Stable Diffusion,我了解到背后的AI工程师就是你。你是怎样的契机加入了QQ影像中心?为什么选择了AIGC赛道?
周艺超:我是两年前来到QQ影像中心,最初的契机是当时QQ影像中心推出的一个童话脸滤镜,这是一个基于GAN的图像生成技术落地的应用,效果非常出圈,在技术和落地应用上都做得很好,与我的个人偏好也很符合。于是我就投递了简历,后续也很幸运加入QQ影像中心团队。

QQ童话脸滤镜
但是当时由于技术限制,基于GAN技术对日漫风格的生成效果不够理想,后来随着技术发展,终于能够在我负责的《异次元的我》项目中实现非常突破次元壁的日漫风格滤镜,也可以看作是当时活动的一个延伸,对于我这个资深二次元来说可以算是圆梦了。

点击体验QQ小世界《异次元的我》,KFC官方推特亲自将肯德基老爷爷变成二次元形象
2
田超:相信大家最想知道的就是AIGC背后的技术原理。以QQ影像中心的《异次元的我》为例,你能给大家简单讲解一下AI是如何生成图片的吗?
周艺超:要知道AI如何生成图片,首先需要大致理解,目前的主流AI,本质上是在模拟现实中的数据分布,是一个非常复杂的统计模型。所以对于AI绘画来说,它需要用巨量的真实图片来训练,通过模型去模拟数据的分布规律,再用这样的规律去生成一张新的图片。
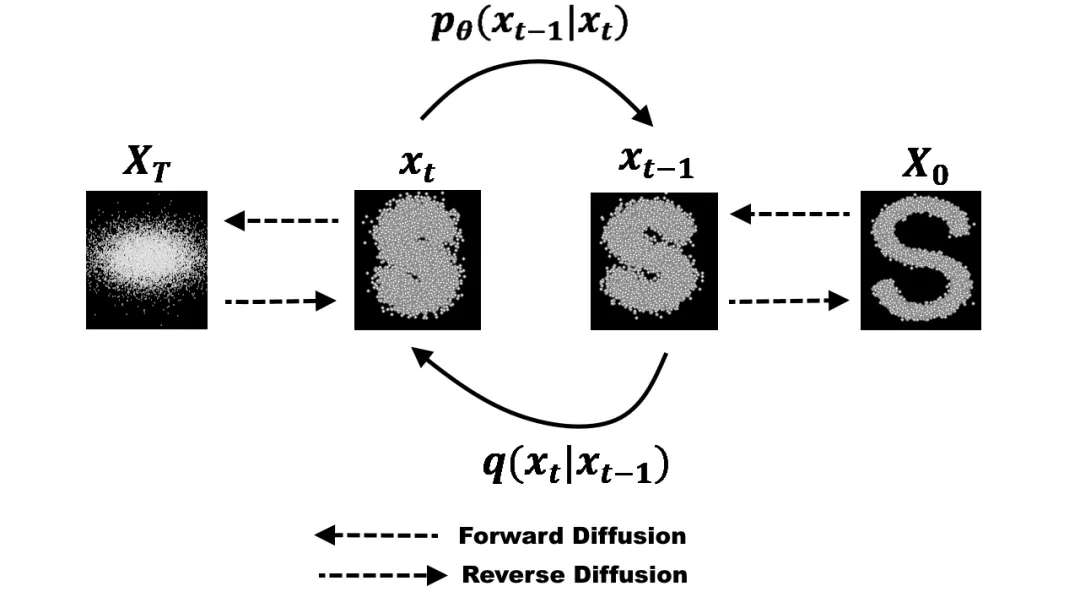
而目前的主流AI绘画模型,是基于扩散模型的。打一个比方说,我们往一块牛排上撒椒盐,撒上去以后牛排的纹路会慢慢变得看不清楚,而扩散模型可以通过这样撒上椒盐的图片去预测椒盐(也就是噪声)分布来去除椒盐,还原牛排的纹理。所以如果把每一步显示出来,就可以看到一张充满噪声的图片,变得越来越清晰。这就是目前主流AI绘画使用的模型的基本原理。
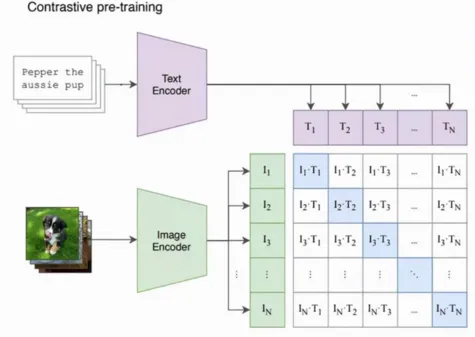
在教会模型如何学会画画(通过去除噪声还原图片的方式)之后,要如何让模型生成我们想要的效果呢?这就涉及到衡量文本和图像的相关性,这个部分使用的是CLIP模型。这个CLIP模型,其实就是用了巨量的文本+图片数据对(互联网可以爬到大量数据),把图片和文本编码后的特征计算相似性矩阵,通过最大化对角线元素同时最小化非对角线元素,来优化两个编码器,让最后的文本和图片编码器的语义可以强对应起来。
在生成图像的过程中,原本的网络只需要预测噪声,现在网络不但要预测噪声,还需要让去噪后的结果图尽可能和文本接近(也就是CLIP-loss尽量小)。这样在不断去噪的过程中,模型就会倾向于生成和文本相近的图片。

而异次元这样的漫画滤镜,则是对用户上传的原图增加几层噪声,再以这个为基础进行常规的去噪。叠加的噪声的强度越高,生成的图片和原图就差距越大,AI画画的发挥空间就越大。

拿肯德基爷爷来说,你把屏幕放远点看这两张图的色块是相近的。因为右边的图片就是基于左边叠加了厚厚的“椒盐”来作为基础生成的,大致的色块结构依然保留了,但模型也加上了自己的想象(通过文本引导)。
3
田超:其实上传图片一键变成二次元的应用也不少见,《异次元的我》上线时美图和抖音都有同步推出类似的日漫风格滤镜,那么QQ影像中心的《异次元的我》对比友商特别在哪里?
周艺超:《异次元的我》是去年11月的项目,当时AI绘画在国内突然爆火,各平台几乎是同时推出了各自的AI动漫滤镜,我们属于国内首发最早的一批。
在此之前,虽然也有一些基于GAN的动漫滤镜,但效果都不太好。GAN的优点是可编辑性强,弱点是生成图片不够灵活,所以对于日漫这种和真人人脸比例差别很大的情况,效果就不太出众。
而扩散模型技术问世后,强大的生成能力迅速取代GAN成为最具有影响力的主流生成模型,基于扩散模型点动漫风格生成也相较GAN的效果好了很多。
如果是和同期友商对比我觉得我们的效果应该是最“二次元”的,很符合我们QQ小世界用户的喜好,而且我们在内容匹配度和丰富度上也会好很多。

此外,为了降低用户的使用门槛,我们对生成流程进行简化。首先,我们对生成语义进行强化,并辅助图片内容分析提升生成内容对应性,通过识别图片信息并增加到引导词中,我们可以更准确还原原始的图片内容。我们还增加了场景识别(如单人/合照等),并针对各种场景设计了丰富且美观的风格化效果。另外,在生成速度上,我们通过超分和推理过程的加速,达到较快的生成速度。
4
田超:真正去使用AIGC的人总是会抱怨AI“听不懂人话”,图片质量靠运气和输入描述指令的水平,需要大量时间进行试错,才能让AI产出满意的成品,因此废片率较高。你如何看待很多AIGC应用都存在的“听不懂人话”的现象?QQ影像中心又是如何改进的?未来这种“念咒语”的方式还能如何优化,让小白用户也轻松上手?

Midjourney官网优秀作品,下方为生成图片的prompt引导词
周艺超:“听不懂人话”是自然语言模型的一个遗留问题。之前的语言模型大多数都需要用很复杂的引导词(prompt)去得到想要的回答,直到ChatGPT横空出世,能够以人类的对话沟通形式得到优质的回答。所以我认为AI绘画生成向更简单易用、沟通门槛更低的方向发展是一个必然的趋势。
当然,目前AI绘画模型还没有办法做到ChatGPT那种程度,但从产品包装的角度上,我们把复杂的引导词、参数等调试进行了系统优化,使其更加智能,用户使用门槛低。以《异次元的我》为例:一个是我们会智能识别图片的信息,增加到引导词中;另一个是我们会提前预设好调整得很漂亮的风格词加上去。
在模型训练的角度,我们也采用了更短的引导词去准备训练集;此外,我们还会通过补充高质量数据、对数据进行清洗、使用高质量图片的方向向量对生成结果进行引导等多种方式去提高图片生成质量,不再需要完全依赖引导词。
5
田超:早在2021年,OpenAI就发布了DALL·E,但作为初代工具,生成的图片都比较粗糙,“一看就是假的”。直到Midjourney爆火,AI图片逼真程度堪比摄影,网友创作的特朗普被警察逮捕、马斯克与炼铁工厂组合、中国男足“拿下”卡塔尔世界杯的冠军看起来与真实的新闻图片没有差别。现在的AI绘画是如何实现这种逼真感的?

小红书博主“Ai船长”用Midjourney生成国足夺冠图
周艺超:这其实就是一个AI的学习过程,具体到这些模型来说,最主要的提升应该是补充了更高质量的图片,例如很多图库收录的大量优质的摄影师的作品(Midjourney的V5能够使用相机参数如光圈等控制生成结果,可以推测出应该是喂了不少的带有相机参数信息的图片)。另外,对数据做了比较细致的清洗,使用一些美学评分估计、图片内容理解的模型来筛选出更优质、更符合需求的图片,来提高人工筛选的效率。
Midjourney本来不是开源的,它真的用了什么黑科技我们也说不好,但目前的效果我认为是可以通过提升数据集质量达到的。
当然,QQ小世界也已经有这种生成逼真感照片的能力,这是我们模型生成的“哈士奇看烟花”。

但是从产品的视角出发,QQ小世界的用户偏年轻化,更倾向于艺术化的图片,因此最终我们在落地的时候选择了更符合小世界喜好的风格,于是“哈士奇看烟花”变成了这样:

这是我们近期推出的“魔法画室”的生成结果。我们提供了多种风格的AI绘画,部分是基于我们的自研大模型,部分是基于开源社区的stable diffusion模型迭代开发,欢迎大家在手机QQ中进入小世界搜索“魔法画室”亲自体验。

6
田超:即使是做得非常成熟的Midjourney,也有AI绘画的一大通病——不会画手,一只手有7个手指头、手指不正常地扭曲,直到最近Midjourney发布的V5版本才极大地优化了这个问题。为什么AI绘画会存在不会画手的缺陷?目前我们是如何解决这个缺陷的?
周艺超:对于AI绘画来说,越是复杂精细的内容,机器越难学习,不仅是手,文字理解也是另一个比较大的缺陷,不过我们现在都可以针对性地进行优化。

AI绘画生成奇怪的手(图源:网络)
一个最简单的方法就是用很多画得很精细的手部图片打上标签去训练模型,让模型学习到这是好的手,往这个方向去生成结果。
现在还有更直接的方法,就是用ControlNet增加一层手的结构作为输入,这个效果会更好。
ControlNet是一个基于 Stable Diffusion 1.5 训练的轻型预训模型,通过添加一些额外条件来控制预先训练的扩散模型(例如Stable Diffusion),配合文字引导词,让生成的图像更加受控制,更加精准。
目前ControlNet已经上线了8个训练好的模型,其中一个模型叫Openpose可以帮我们提取出人物的姿势或者手部关键点,让生成的图片保留这些信息,不用只能通过频繁更换提示词来“开盲盒”。ControlNet的其他模型还能用来为手绘线稿着色、提取线稿生成同样构图的图片、生成同样深度结构的图等等。


ControlNet实现效果(图源:网络)
也就是说,ControlNet相当于给网络增加了一个插件功能,有网友基于ControlNet训练了各种可以控制手脚生成的模型,效果提升很明显。

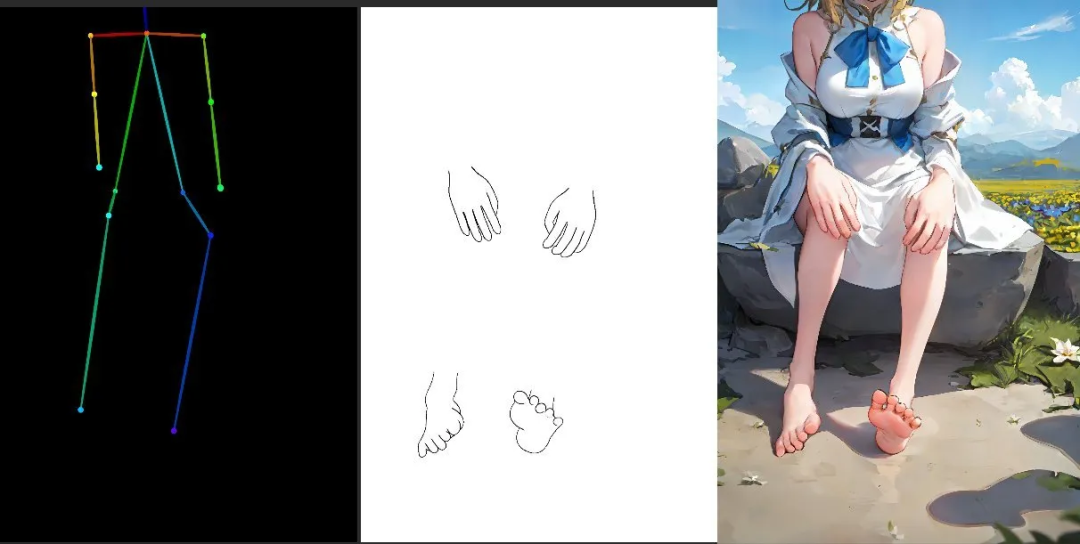
最新发布的ControlNet 1.1官方可以直接支持人脸点位、身体、手部骨骼的控制。

7
田超:AIGC背后都是用模型驱动的。目前QQ影像中心自研了diffusion模型,现在最火爆的模型有Stable Diffusion、Dall-E、Midjourney,国内也有百度的“文心大模型”(ERNIE-ViLG)等等,那么QQ影像中心的模型对比竞品来说,有什么优势?
周艺超:我们现在新出了一个活动叫“魔法画室”,欢迎大家在手机QQ进行体验,这个也是我们自研大模型的初次亮相。通过对DALLE2、Stable Diffusion等方案的对比,我们针对以下几个方向做出改进:
1、更强的文本特征提取
通过DALLE2和Stable等模型的改进方案可以看到,语言模型特征提取在图片生成过程中至关重要。包括Google的Imagen以及Nvidia的ediff等方案,都尝试在引入了更多更强大的语言模型作为文本特征提取器,并且取得效果上的显著提升。
我们改进了文本特征提取网络结构使其文本提取能力进一步加强,并且我们补充了相当多的中文训练数据,让我们的模型可以更好生成“红烧狮子头”这类有特定中文语境特色的效果。
以下是一些模型生成效果示例,在语意贴合度、美观度方面的优势还是很明显的,尤其是对于一些较为复杂的内容依然能够表达得很准确:
疯狂科学家大熊猫进行化学实验:

眼中的地球:

三明治金字塔:

2、对训练数据要求较低的技术框架
高质量text-image成对的数据要求文本能够很好地描述图片,同时图片也有足够高的质量,其收集的难度远大于收集单独的高质量图片(或文本)。我们的应对策略是将文生图任务尽量解耦,降低对数据收集的要求,让训练更容易收敛。
3、更轻量低成本的训练部署
Stable Diffusion模型作能够迅速破圈的原因在于其相对轻量的技术方案,通过减少超分等更大计算量的步骤,大大减少了训练及部署的成本。此外,我们的服务部署落地也有对生成速度、效果进行优化,从实际体验来说应该使用门槛也会更低。
这些都是我们自研大模型的生成结果:

8
田超:AI大模型近几年已经从亿级发展到了万亿级参数规模,训练大模型离不开强大的算力、算法、数据,其中算力往往是大厂才有较多的资金与资源提供支持。因此,很多观点认为AIGC赛道都由大厂“垄断”,完全没有小厂的生存空间,你认同这样的观点吗?
周艺超:我不这么觉得。大厂优势肯定是存在的,因为数据集和训练都非常“烧钱”。但是这也并不是说小厂或者个人开发者就无法生产出有价值的应用,现在的AI绘画技术开源社区非常繁荣,我们平时都要经常去开源社区学习取经。
很多小厂可以基于开源模型和数据开发出更偏落地的应用,并不是每个参与者都要从零开始训练大模型。例如有人基于Stable Diffusion做了一个专门用于设计Logo的应用,这是它设计的瑜伽logo,非常传神:

除此之外,小厂还可以参与到像ControlNet这样的技术革新,ControlNet其实也是一个21年才本科毕业,目前就读于斯坦福的计算机博士张吕敏制作的。只要你有足够好的idea,就是最值钱的。
9
田超:AI绘图训练数据模型需要用到大量图片,而这些图片的来源也存在不小的版权争议,Stable Diffusion还曾被全球最大的图库公司Getty Images告上法庭,指责其训练AI制图工具时涉及商业侵权。此外,就在上周,国家互联网信息办公室发布了关于《生成式人工智能服务管理办法(征求意见稿)》公开征求意见的通知,要求生成式人工智能提供者“承担该产品生成内容生产者的责任”,也就是各类B端客户在使用生成式人工智能对外提供服务时,也都要追溯到源头提供者的责任。有不少从业者认为这些要求不合理,甚至会阻碍AIGC的发展。作为AIGC从业者的一员,你是怎么看待这份征求意见稿?
中国互联网信息办公室关于《生成式人工智能服务管理办法(征求意见稿)》公开征求意见
周艺超:首先,我觉得版权是比较难处理的问题,约束起来非常困难。就目前而言,我们很难完全去确认开源数据具体的版权情况,比如我们用于训练模型的海量图片是没办法一张张确认其版权和使用权,Midjourney也用了大量画师的图片,ChatGPT也爬取了巨量的网上文字。可以说版权是任何AI应用都需要面对的问题,而绘画领域由于辨识度高又会把版权问题放大。
对于AI绘画来说,大家之所以非常在意版权,很大程度上是因为不想AI生成的东西与现有的作品相似度过高,这种“抄袭”并不会因为是机器生成的就不算抄袭。那么我们在使用模型时就尽量避免生成一些个人风格非常明显的图片,而是生成比较通用风格的图片;此外,我们会跟腾讯内部的一些IP合作,推出具有我们自己版权的应用,这些都是目前比较可行的处理方法。
征求意见稿里提到的生成式人工智能提供者要承担内容生产的责任,我认为这个规定是非常合理的。我们是没有办法去控制B端客户如何去运用我们的AI服务,所以我们就应该先把不合规的东西堵死,不给客户提供任何具有生成高风险图片的工具。在我们的落地应用中,我们对用户输入和AI生成的图片都会进行安全检查,不允许机器生成含危险元素或者色情的内容。
当然,在实际应用中,如果产生了不好的结果,我们应该先判断这是因为我们没有控制好生成结果,还是客户非法利用我们的生成结果,这样才能更好地去区分由谁来承担责任。
10
田超:每次AI工具的诞生总是伴随着某个职业将被替代的焦虑。现在很多讨论认为AI绘画将替代大量漫画、动画、游戏从业者,网络上也有很多关于知名游戏团队把原画外包团队砍掉的传闻。你认为AI绘画会抢走哪些人的饭碗?从业者应该如何应对?

2022年,Jason Allen 用Midjourney创作的作品《Théâtre D’opéra Spatial》(太空歌剧院)在科罗拉多州博览会的年度艺术竞赛中获得了第一名
周艺超:我觉得目前AI绘画还没有达到取代画师的程度,而是会帮他们节省一些创作时间,因为最终生成效果还是需要美术把控和调整的,并且AI绘画需要的显卡资源本身也很贵,还需要有人去跑。
根据我目前和设计合作的经验来看,有美术素养的人如果学会使用AI绘画工具,确实可以充分发挥出工具的效果,对整个行业是利好的。尤其在将创意想法可视化这方面,AI可以帮忙快速迭代,并且一旦确认好风格后很容易量产,所以相关从业人员可以尝试使用AI绘画来提升工作效率。
另一方面,AI绘画降低了创作的门槛,让更多普通人参与到绘画创作当中,将个人idea变为可展示的图片。AI绘画厂商会对用户体验进一步优化,降低使用难度,或者和ChatGPT这类更优秀的语言模型相结合,因为ChatGPT已经能够比较好地“理解人话”,可以让GPT帮我们控制绘画模型生成精准的图片,AI绘画的未来是非常值得期待的。
* 图片来源:QQ影像中心、小红书、国家互联网信息办公室、网络等
END
栏目统筹 | 赵九州
责任编辑 | 黄绮婷 庄雅捷 张洁

你看好AI绘画的发展吗?你认为AI绘画能取代人类画师吗?欢迎在评论区分享你的看法**点亮“在看”+评论区留言**,阿D将在4月27日(周四)下午15:00随机抽取1位粉丝,送出DNSPod定制马克杯









《DNSPod十问》是由腾讯云企业中心推出的一档深度谈话栏目,通过每期向嘉宾提出十个问题,带着广大读者站在产业互联网、科技领域精英的肩膀上,俯瞰各大行业发展趋势和前沿技术革新。
栏目嘉宾的领域在逐渐扩大,从最初的域名圈、站长圈到程序员圈、创业者圈、投资圈。腾讯副总裁丁珂、CSDN董事长蒋涛、Discuz!创始人戴志康、知识星球吴鲁加、腾讯安全学院副院长杨卿等技术大咖和行业领军人物都在这个栏目留下了他们的真知灼见。
《DNSPod十问》在腾讯云生态圈也极具影响力和活跃度。我们在腾讯内部平台——DNSPod公众号、腾讯中小企业服务公众号、腾讯云公众号、腾讯云主机公众号、腾讯云服务器公众号、腾讯云助手、腾讯乐问、腾讯码客圈、腾讯KM平台、腾讯云+社区、腾讯云+大学等平台累计关注度高达数十万,同时我们积极开拓与外部媒体的合作,如腾讯科技、腾讯新闻、新浪微博机构号、CSDN社区技术专栏、知乎机构号、企鹅号、搜狐号、头条号、开源中国技术社区、IT之家、InfoQ社区资讯站点、Twitter机构号、Facebook机构号等媒体阅读总量逾百万。
未来,我们希望这个栏目的影响力会覆盖更加多元的受众,把更多正确的理念对外传递出去。欢迎各位读者在评论区留下你想看到的嘉宾和想问的问题,我们邀请你共同成为《DNSPod十问》栏目的提问者与发声者。
合作联系:
qitinghuang@tencent.com
▼公众号后台获取二维码
加入DNSPod官方用户群