


导语
这个国庆假期互联网最大的新闻就是某不存在的公司 Facebook 全线业务宕机了 7 个小时,这其中有一个不起眼但是很关键的原因是其权威 DNS 节点在检测到部分网络异常(可以理解为控制面异常)后进行自我剔除操作,所有 DNS 节点“集体自杀”,从而导致 Facebook 自身及其他使用其权威 DNS 服务的业务全线异常。这里会简单聊聊腾讯云 DNSPod权威 DNS 的控制面异常时是如何处理的,包括曾经的思考与当前的实践经验,如何保障在出现类似问题的情况下尽量保障 DNS 服务的连续性,最终方案其实很简单,一点都不高大上,但好在简单实用。
权威 DNS 的控制面最主要的工作是同步用户记录的修改,不管是通过私有协议还是域传送,一旦控制面异常,边缘的 DNS 节点在故障期间无法同步用户最新的记录修改数据,终端用户就可能解析到旧的 IP 上,对业务造成一定影响,所以控制面故障时主要要解决的问题就是如何防止故障节点继续响应过期记录。
当前权威 DNS 大多使用多个 IP 同时提供服务,可能是 Anycast 集群,或者单地域集群,或者混合部署,都可以提供一定的容灾和负载均衡能力。而递归 DNS 对多个不同的权威 DNS 服务 IP 一般是通过 SRTT 方式来选择使用哪一个 IP 进行请求,可以自动剔除(减少请求)故障的权威 IP,一般只要权威的 IP 列表中有可用的 IP 且容量足够就可以正常进行递归解析。
所以最简单的处理方式就是直接踢掉控制面异常的权威 DNS 节点,即可保证递归不会解析到过期的数据,但是就是这最简单的踢掉故障节点的操作,其实也会涉及到很多的思考和实践经验,下面从头开始介绍。
控制面故障影响范围分类
按照影响 DNS 节点范围和处理方式来区分控制面故障的类型,主要就是两种类型,部分节点受影响和全部节点受影响。
01.部分节点受影响
这里可能有多种原因,最常见的如 DNS 节点与控制中心之间的网络异常,或者部分控制中心从节点故障,只影响少部分边缘的 DNS 节点的控制面数据同步,那么这时候故障 DNS 节点自救做自我剔除,将自己从服务集群中摘除貌似完全没有影响,然后自动/手动切换到其他正常的控制节点或者等待故障的控制节点恢复,再恢复 DNS 节点的对外服务即可。
当然这里没有影响是有一个前提的,那就是剩余节点必须有足够的服务能力,而故障节点本身因为控制面故障形成了一个孤岛节点,是没有足够的信息进行相关判断的,可见即使只有部分节点受影响,故障节点也是不能轻易进行自我剔除操作的。
延伸阅读:
DNSPod 2018.11 免费套餐的 DNS 故障时并不是免费平台的全部节点服务器故障,依然还有部分集群能够对外提供服务,但受限于该部分集群容量不足,全部容量跑满导致大规模的解析失败。
02.全部节点受影响
这里最大的可能原因是控制中心节点故障,如控制中心主节点宕机,或者网络故障导致所有从节点数据同步落后,此时如果故障 DNS 节点还进行自我剔除,所有 DNS 节点“集体自杀”了,后果严重,就是这次 Facebook 事件中 DNS 节点服务器的操作了。
延伸阅读:
2009 的 “5.19” 南方断网故障,DNSPod 只有免费服务,且多台服务器位于同一机房,因受攻击被机房拔线导致所有服务器下线,所有使用 DNSPod 进行解析的域名无法解析,暴风影音客户端解析失败重试量太大导致运营商 LocalDNS 服务器受冲击雪崩,进而影响所有用户的 DNS 解析。
如何解决
从上面的分析可以得出一个结论:权威 DNS 节点在控制面故障时一定不能做自我剔除的操作,因为孤岛节点是没有足够的信息,无法得出正确的结论,是否应该进行自我剔除,下面是前两年时讨论这个问题的一个截图,当然这个结论在很多年前其实就已经分析得出了。
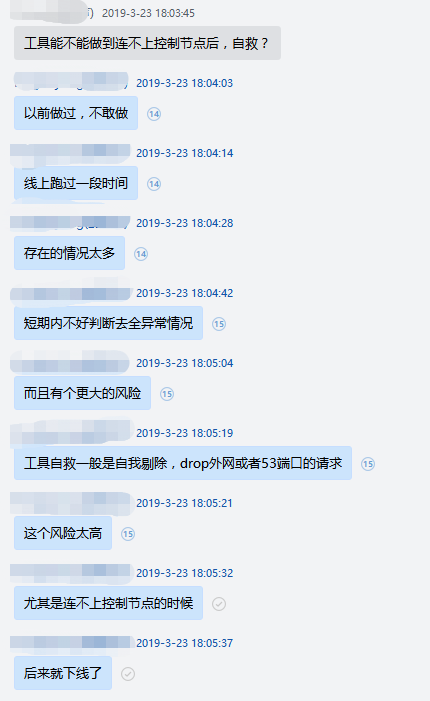
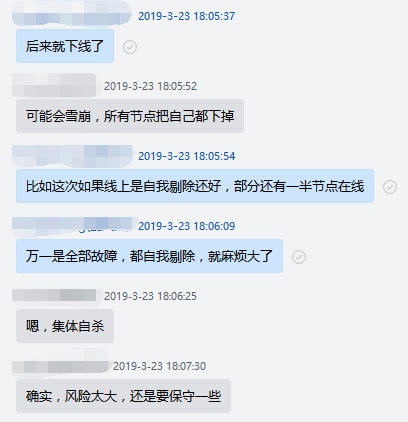
故障 DNS 节点能做的是告警、尝试切换寻找正常的控制节点等操作,很多时候故障节点已经可以自动恢复,比如单独某个控制从节点故障自动切换即可恢复。但是也有时候无法自动恢复,如 DNS 节点本身内网故障的时候,而且这时候节点本身的告警也是无法正常发出来的_。
那就只能通过权威 DNS 节点及控制面之外的外围监控来进行处理,目前 DNSPod 的实践经验是这样的:
控制面故障监控:
-
在多个地区多个运营商部署了监控节点,对所有的权威 DNS 的 LB VIP 以及 RS 的物理 IP 持续进行拨测;
-
每一轮拨测前通过 API 对拨测域名添加一条 TXT 记录,记录值为当前拨测点当前时间戳;
-
正常情况下 DNSPod 所有的权威 DNS 节点的数据同步都是秒级的,所以一旦拨测结果与最新设置的记录值不一致,则可以判断该节点数据同步落后,并可以计算出落后的时长,汇总统计所有数据同步落后节点后发出告警,实现对 DNS 节点控制面是否正常的监控;
-
该监控可以同时对 DNS 节点的数据面是否能够正常解析进行监控告警。
控制面故障处理:
接下来就需要对控制面故障的 DNS 节点进行处理,此处可以有多种处理方式,自动或手动,DNSPod 目前主要还是手动处理,主要由以下几个原因:
-
目前外部的监控节点对 DNS 服务器做的是完全黑盒拨测,很难自动判断 DNS 节点控制面故障的真实原因,从而无法确定处理方式;
-
监控节点无法直接控制 DNS 服务器的行为,而通过控制中心处理的话,但是此时控制面已经异常了,可能会陷入死锁无法处理,还是比如故障节点内网中断的这个场景;
-
大部分异常节点已经可以自动恢复,无法自动恢复的告警发生频率很低。
不同场景处理方式:
本节列出几个常见的控制面故障场景,以及对应的处理方式
节点本身内网故障:
此时故障节点处于一个网络孤岛,内网中断,外网因为安全原因禁止登陆,根据不同情况可以由以下几种处理方式:
-
如果只是 LB + RS 集群中单独某台 RS 故障,优先通过 LB 剔除;
-
如果LB异常或没有LB(如直接的 OSPF 集群),有带外,可以通过带外方式登陆服务器,将该服务器剔除,剔除方式优先选择停止 OSPF,如果没有 OSPF,则可以考虑封禁数据面 53 端口的请求以及停止服务程序等方式;
-
没有带外或者带外故障,如果该故障节点是 Anycast 节点,可以选择在交换机等处取消 BGP 广播下掉整个节点,需要能够快速联系到网络交换机相关负责人,且不会影响其他业务;
-
直接通过防护系统(宙斯盾)或运营商防护接口在某地域或全地域封禁该IP,此时虽然对应节点的 IP 不可用,但是 LocalDNS 可以通过文章开头提到的 SRTT 机制去其他正常节点请求,不影响总体解析;
-
前面的处理方式都有一个前提,就是其他节点容量足够,但是如果剩余节点容量不足怎么办,此时处理方案是不对 DNS 节点进行下线处理,虽然可能导致部分 DNS 请求会解析到过时的记录,但是有变化的记录毕竟是少数,需要优先保证整个大盘的解析正常。此场景在某些极端情况下有一定的出现的可能,比如整个平台遭受持续超大量的 DDoS 攻击时,同时这台服务器出现了控制面故障,根据具体情况评估影响后可能采取此不处理下线的方式;
-
在权威解析控制台及注册局(商)出删除该 IP,因为 TTL 很长,一般不考虑。
控制中心完全故障导致所有节点控制面故障:
类似此次的 Facebook 的最初始故障,如判断确实是控制中心就是无法连接,无法同步数据,那么也只能降级服务,不对 DNS 节点进行下线处理,等待控制中心恢复。
(本文作者:姜凤波,F-Stack发起人、DNSPod首席架构师,人称凤梨叔)
SMB
腾讯云中小企业产品中心
腾讯云中小企业产品中心(简称SMB),作为腾讯云体系中唯一专业服务于8000万中小企业的业务线,致力于为中小微企业提供全面完善贴心的数字化解决方案。产品线覆盖了企业客户从创业起步期、规范治理期、规模化增长期、战略升级期等全生命周期,针对性的解决企业的信息化、数字化、智能化的生产力升级需求。本中心还拥有两大独立腾讯子品牌:DNSPod与Discuz!,在过去15年间,为超过500万企业级客户提供了强大、优质、稳定的IT服务。
SMB团队成员大多都有过创业经历,有获得过知名VC数千万投资的,有被一线互联网巨头以数千万全资收购的,也有开设数十家分公司后技术转型而失败倒闭的,我们成功过,也失败过,我们深知创办企业的难处与痛点,深刻的理解中小企业该如何敏捷起步、规范治理、规模化增长与数字化升级发展,我们会用自己踩坑的经验给出最适合你的答案。
腾讯云中小企业产品中心,助力中小企业数字化升级的好伙伴。






