


OOM是实例使用内存超过实例规格内存上限导致进程被kill,实例存在秒级的不可用。MySQL的内存管理比较复杂,内存监控需要开启performance schema查询(默认关闭),会带来额外的内存消耗和性能损失,在不开启performance schema情况下排查内存使用情况又比较困难。本文将基于TDSQL-C(基于MySQL5.7)总结一下在线上经常出现的一些OOM的场景、排查手段及相应的优化方案。
一、MySQL线上常见OOM问题
1.1 表数量较多导致innodb数据字典内存占用多
查询命令:show engine innodb status; 如下,dictionary memory allocated 显示数据字典内存已经占用约8G了,这部分内存不包含在 Buffer Pool 总内存大小中。
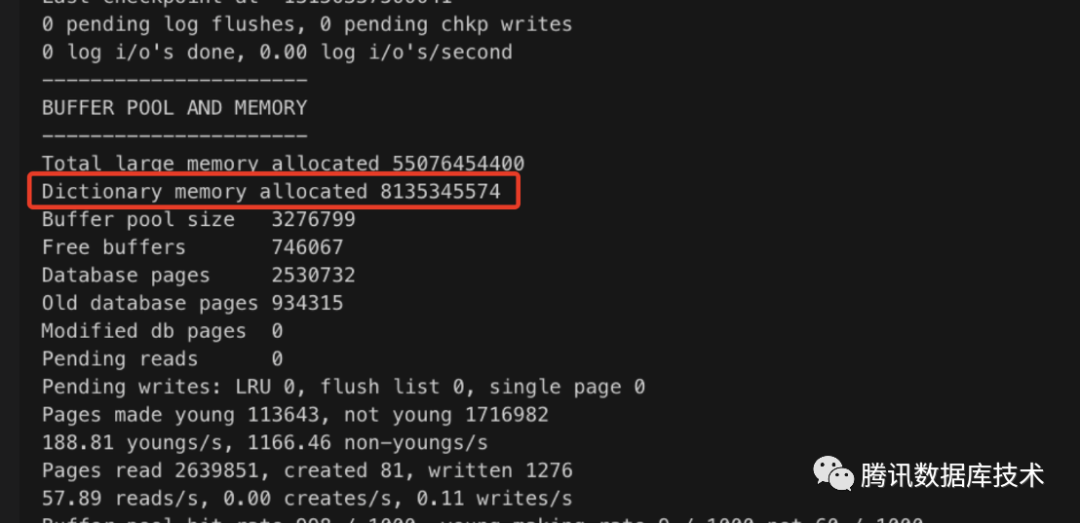
数据字典内存占用和innodb表的数量,表定义,table_open_cache,并发连接数等因素有关。
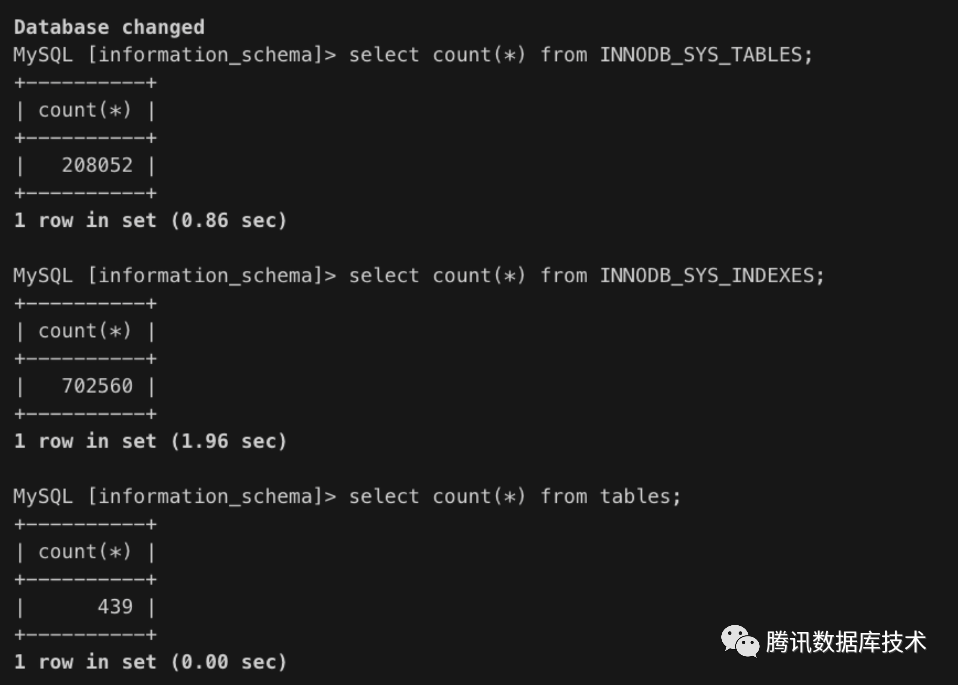
可以看到数据字典表有20w+,索引有70w+,对于这种场景要解决OOM风险,在不损失性能的前提下可以考虑升级内存规格。若能接受性能损失,可以降低innodb_buffer_pool_size或者table_open_cache来缓解内存开销。
1.2 大query带来内存上涨
若观察到实例内存抖动与业务流量增长一致,基本确定实例内存增长是用户连接内存开销导致。
- 通过performance schema来查看具体是哪一块内存占用过多:
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
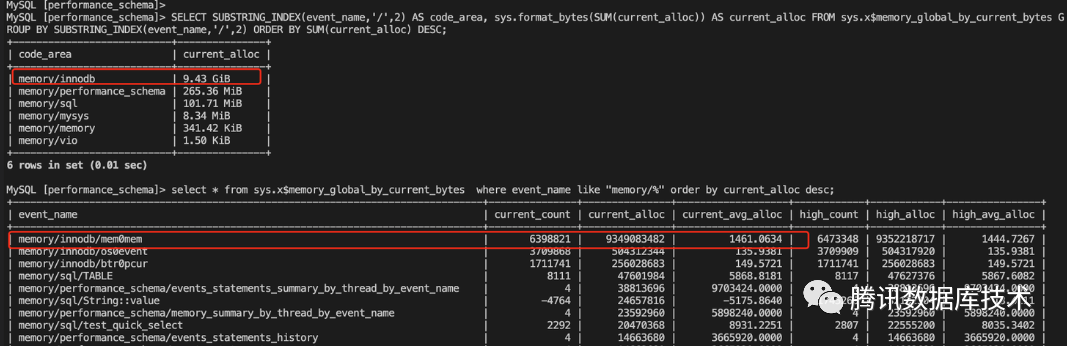
# 1. 使用下述语句查询各个模块的内存占用(查看当前哪个模块内存占用多)SELECT SUBSTRING_INDEX(event_name,'/',2) AS code_area, sys.format_bytes(SUM(current_alloc)) AS current_alloc FROM sys.x$memory_global_by_current_bytes GROUP BY SUBSTRING_INDEX(event_name,'/',2) ORDER BY SUM(current_alloc) DESC;
select *from sys.x$memory_global_by_current_byteswhere event_name like "memory/sql/%" order by current_alloc desc;
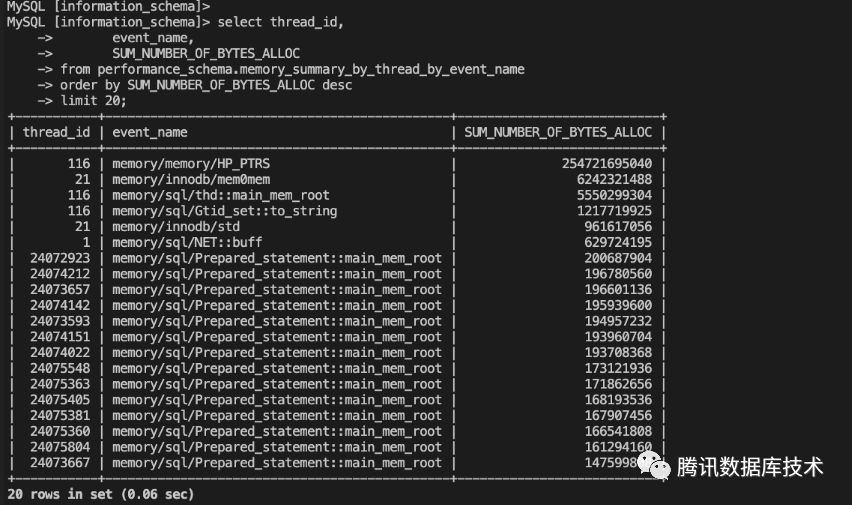
# 2. 查看具体哪个连接占用内存多select thread_id, event_name, SUM_NUMBER_OF_BYTES_ALLOC from performance_schema.memory_summary_by_thread_by_event_nameorder by SUM_NUMBER_OF_BYTES_ALLOC desc limit 20;
# 3. 查看占用内存最多的连接的详细信息select * from performance_schema.threads where THREAD_ID = xxx;
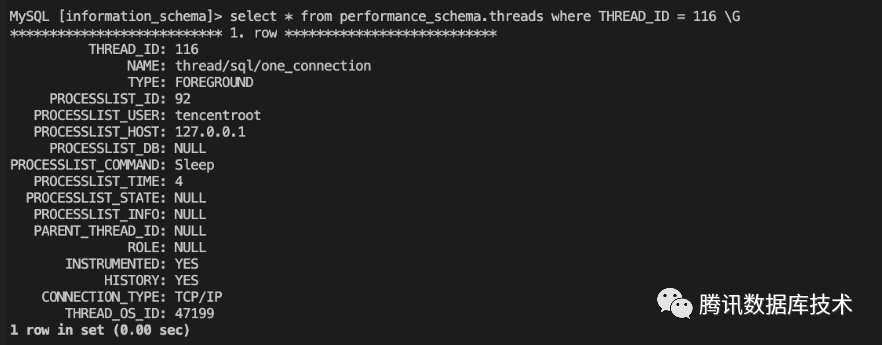
- 通过show detail processlist(TDSQL-C 自研功能)对单个连接占用内存情况进行查询:
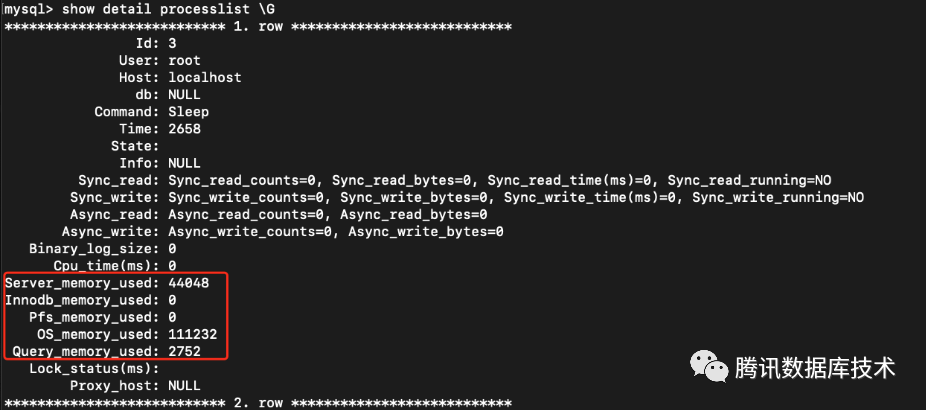
Server_memory_used: 该连接server层内存大小
Innodb_memory_used: 该连接innodb层内存大小
PFS_MEMORY_USED: 该连接performance schema内存大小
OS_MEMORY_USED: 从jemalloc层面上统计该连接内存大小
QUERY_MEMORY_USED: 从jemalloc层面上统计当前query的内存大小
单个连接占用内存过多,可以采用开启线程池限制并发连接数,或者升级内存规格。对于insert多value占用过多内存可以在业务侧进行sql拆分。
1.3 业务sql使用了prepare statement缓存
prepare statement cache用来缓存语句解析后的执行计划,缓存的语句越多,每个session所占用的内存也就越多。以sysbench为例,sysbench 1.1 默认打开了ps,导致prepare_statement缓存占用内存过大触发OOM。
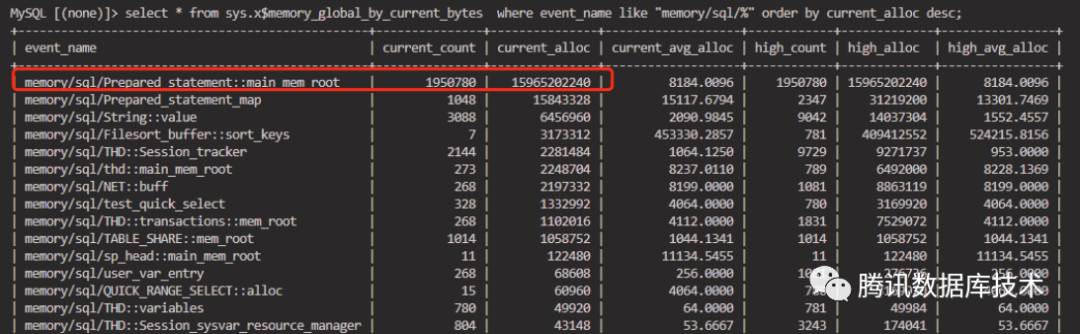
升级内存规格可以缓解OOM,若能接受少量性能损失可以不使用ps缓存(例如sysbench--db-ps-mode=disable关闭ps),或者限制max_prepared_stmt_count大小。
1.4 业务连接数过多
小内存规格的实例出现过万的连接数,连接占用过多内存导致频繁OOM,可以通过开启线程池进行限制。
1.5 net buffer过大导致实例频繁OOM
如下有个实例的内存增长随负载的变化呈螺旋上升趋势:
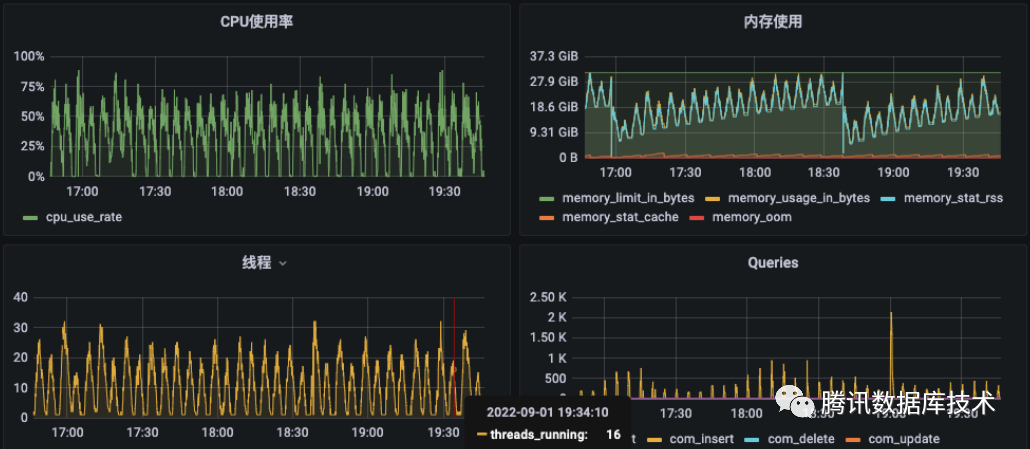
开启performance schema后观察到是net::buffer的内存在持续上涨。

通过以下SQL查询具体哪些连接占用了net::buffer的内存:
-
-
-
-
-
-
-
select THREAD_ID,EVENT_NAME,COUNT_ALLOC,COUNT_FREE,CURRENT_NUMBER_OF_BYTES_USED,SUM_NUMBER_OF_BYTES_ALLOC,SUM_NUMBER_OF_BYTES_FREE from performance_schema.memory_summary_by_thread_by_event_name where EVENT_NAME like "memory/sql/NET::buff" order by CURRENT_NUMBER_OF_BYTES_USED desc;
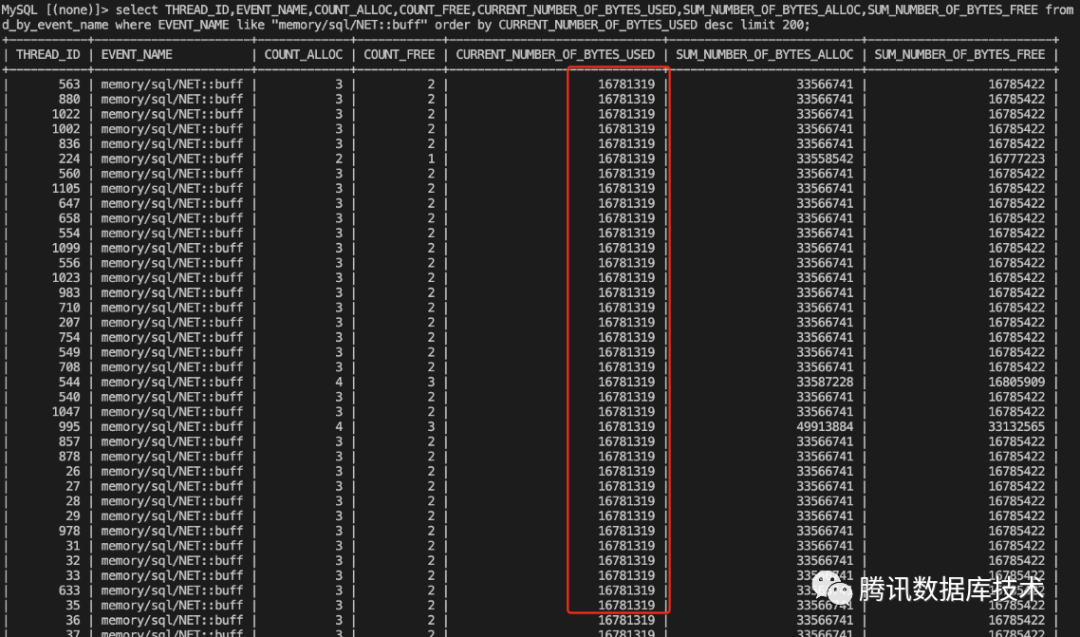
大量连接使用了16MB大小的net buffer内存,这里的具体原因是用户的sql比较大(大于MAX_PACKET_LENGTH,16MB),对于长连接来说执行完query这16MB缓存不会立即释放,用作下一次query的connection buffer,用户使用了大量的长连接导致这部分内存增长很快。
升级实例内存规格、业务侧减小每个sql的大小或者降低连接数可以解决。
1.6 内核bug导致内存泄露引起OOM
使用valgrind查看是否有内存泄漏:
- 下载valgrind
- 安装valgrind:1 ./configure 2 make 3 make install 4 valgrind -h
- 使用valgrind拉起mysqld
-
/valgrind --tool=memcheck --leak-check=full --log-file=valgrind_log --show-reachable=yes --trace-children=yes /data1/mysql_root/base_phony/20152/bin/mysqld --defaults-file=/data1/mysql_root/data/20152/my.cnf --basedir=/data1/mysql_root/base_phony/20152 --datadir=/data1/mysql_root/data/20152 --plugin-dir=/data1/mysql_root/base_phony/20152/lib/plugin --user=mysql20152 --core-file --disable-partition-engine-check
-
给实例加负载
-
shutdown实例,内存检查结果输出到valgrind_log中
-
valgrind_log最后会打印内存泄漏的总体情况,再去找各堆栈的情况
- "definitely lost":确认丢失。程序中存在内存泄露,应尽快修复。当程序结束时如果一块动态分配的内存没有被释放且通过程序内的指针变量均无法访问这块内存则会报这个错误。
- "indirectly lost":间接丢失。当使用了含有指针成员的类或结构时可能会报这个错误。这类错误无需直接修复,他们总是与"definitely lost"一起出现,只要修复"definitely lost"即可。
- "possibly lost":可能丢失。大多数情况下应视为与"definitely lost"一样需要尽快修复,除非你的程序让一个指针指向一块动态分配的内存(但不是这块内存起始地址),然后通过运算得到这块内存起始地址,再释放它。
二、TDSQL-C简介
随着互联网的发展,各种业务数据快速膨胀,用户对数据库计算和存储能力的需求日益增长。在应对业务需求持续增长时,传统数据库的迭代和优化已经变得举步维艰,而分布式架构的优势则愈发明显。借助计算存储分离的架构,新硬件优势,物理复制特点,分布式系统优势,TDSQL-C对比传统MySQL具有高性能,低成本,大存储,主从复制延迟低,秒级扩缩容,极速回档,serverless化等优势。
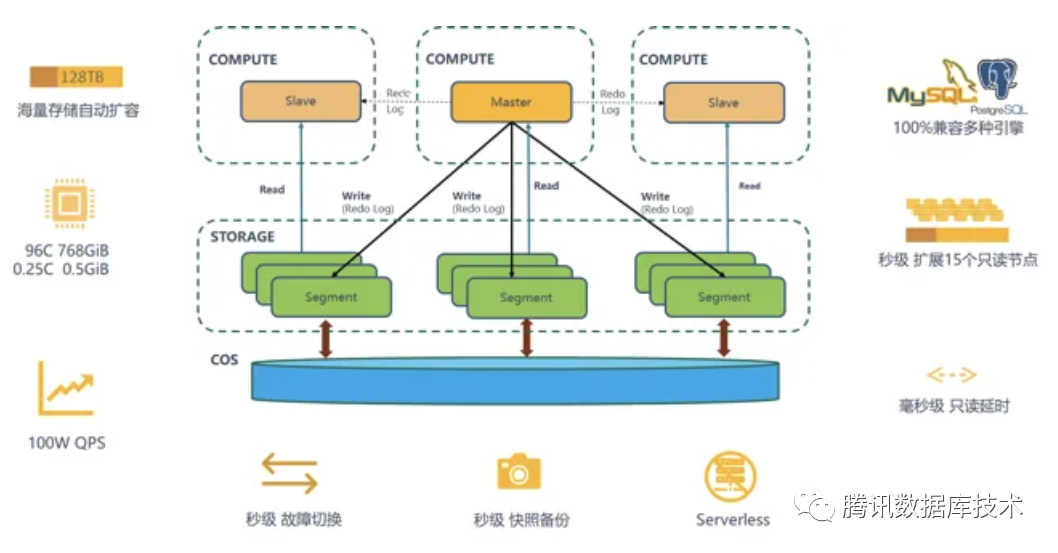
前面讲了TDSQL-C相对传统数据库的优势,接下来介绍TDSQL-C在内存使用方面相对传统MySQL在内存使用方面存在哪些弊端。
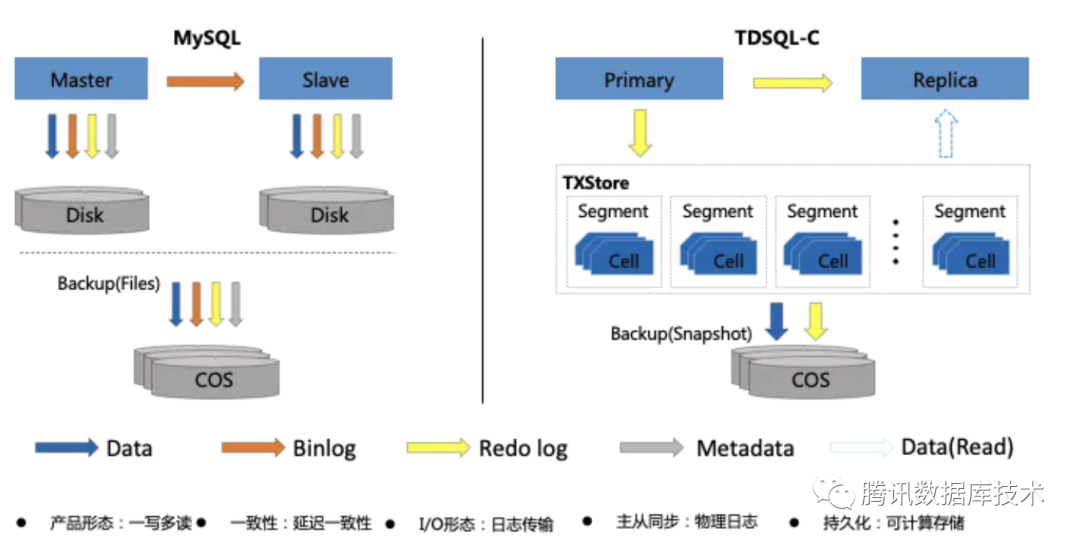
从下面的对比图可以看出,传统MySQL的数据,逻辑日志,物理日志,元数据都是存在本地盘,主从管理各自的数据,通过逻辑日志进行主从同步。
TDSQL-C分为计算层和存储层,本地不再存储任何数据,共享存储层数据,主从通过物理日志进行同步,存储层通过接受主库发送的物理日志进行回放生成数据及元数据,不再需要逻辑日志。架构的巨大改变带来了以下问题:
-
TDSQL-C卸载了本地io, 不再保留redo log file,而是在内存中增加了一个可以覆盖写的日志发送缓存区,相对传统MySQL会带来额外的内存开销。
-
TDSQL-C增加了主备之间、计算节点和存储节点之间的通信节点管理,计算节点远程page io任务队列维护,相关监控信息采集,备机物理日志回放等也会带来相应的内存开销。
三、TDSQL-C OOM 优化
3.1 TDSQL-C Server端参数优化
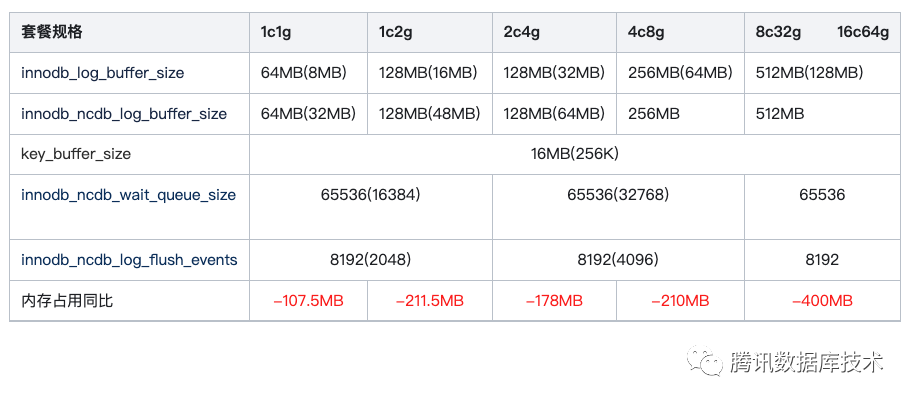
我们在不影响数据库性能的前提下修改实例默认配置来降低内存占用(括号内为优化后的默认值),主要包括以下参数的调整:
- innodb_log_buffer_size: 用来设置缓存还未提交的事务的缓冲区的大小
- innodb_ncdb_log_buffer_size:该参数对主库来说相当于innodb_log_file_size,对于备机来说相当于日志接受缓冲buffer
- key_buffer_size:key_buffer主要用于缓存MyISAM index block,TDSQL-C不支持MyISAM存储引擎
- innodb_ncdb_wait_queue_size:开启异步组提交后,innodb_ncdb_wait_queue_size表明最少可以同时容纳的事务异步提交数量,超过后需要同步等待
- innodb_ncdb_log_flush_events:唤醒等待log flush的event的个数
实验验证性能是否下降以及内存占用是否减少:
实例规格:2c4g 一主一从
测试场景:分别用1G和100G的数据量对应cpu bound和io bound场景进行sysbench读写性能测试
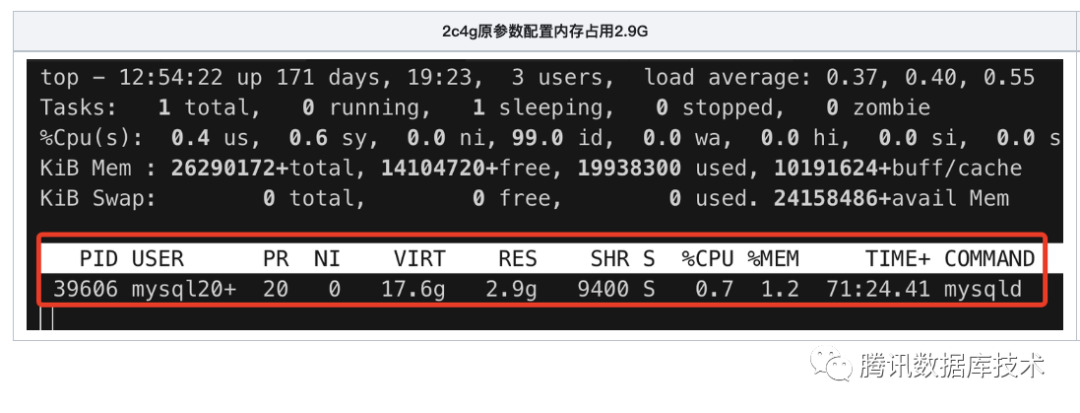
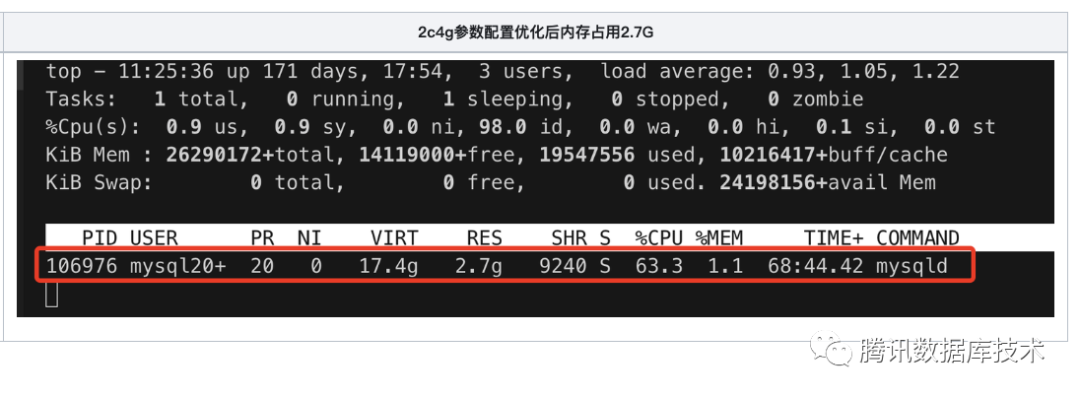
测试结论:在性能无显著变化的情况下,2c4g规格的实例实际内存占用减少了约200MB。
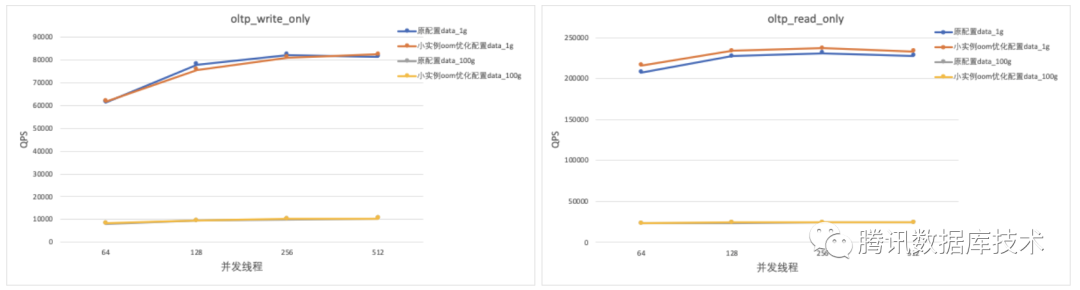
压测后观察实例的实际内存占用情况:
3.2 支持information_schema.detail_processlist快捷查询各连接数内存使用
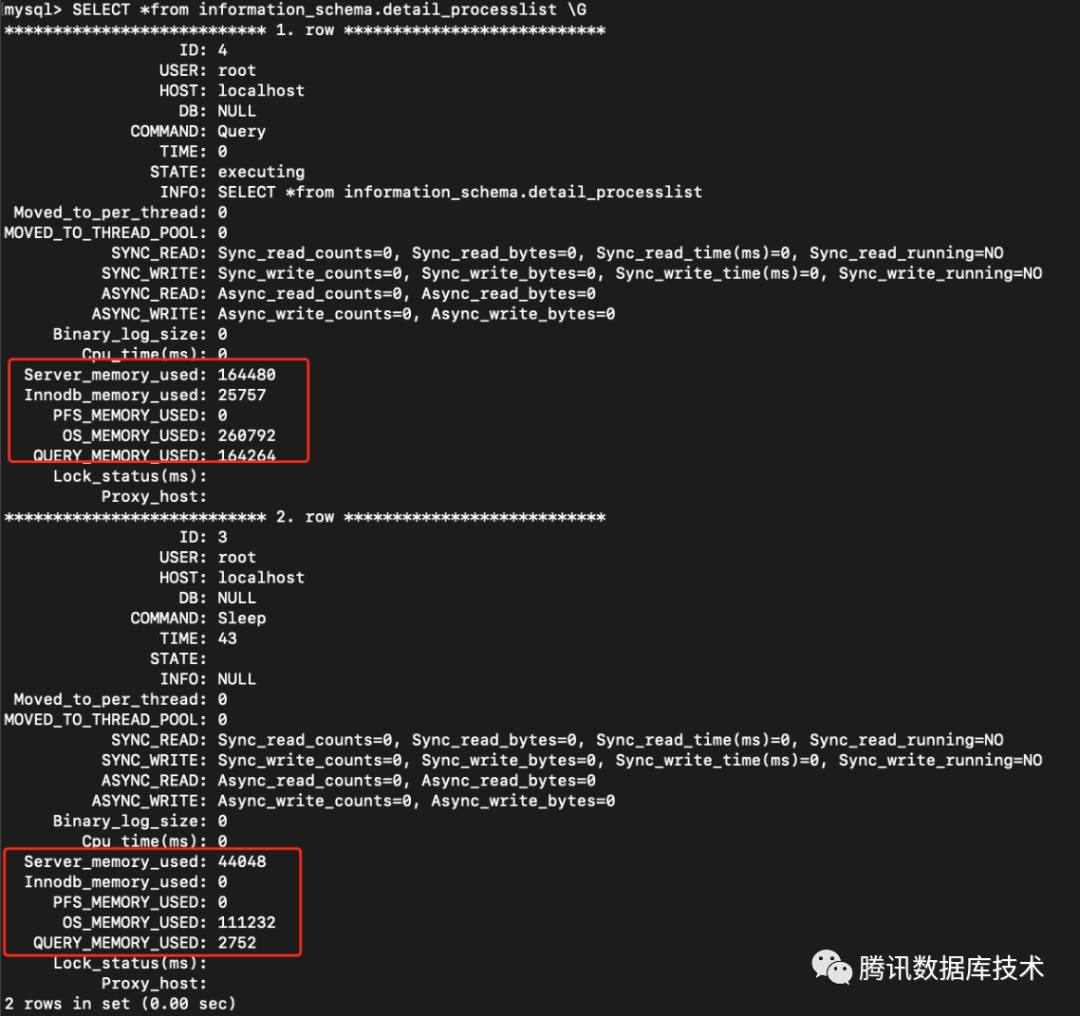
进一步支持将show detail processlist的结果存储到information_schema.detail_processlist,便于以下查询:
- 按内存使用量排序查询出使用量Top n的链接;
- 计算所有连接内存使用量的总大小;
- 其他查询类似聚合或者top类的字段;
3.3 支持innodb buffer pool冷热page数量查询,为用户推荐合理的innodb_buffer_pool
统计在一段时间内没被访问的page的数量,反映出来用户真正需要多大的buffer pool,便于自动缩容到用户需要用的 bp 上。
内核新增参数:innodb_hot_page_time,单位秒,表示一定时间内访问过的page都是热page。
新增命令:show coldpage status,表明在buffer pool中,在innodb_hot_page_time时间内没有被访问过的page数量。

用户可以根据业务情况设置innodb_hot_page_time计算出准确的热数据量,根据热数据设置合理的buffer pool size。
3.4 限制innodb_buffer_pool的最大使用率,降低OOM的风险
实例启动后,innodb buffer pool随着使用率的增长,内存分配也逐渐增加,假如innodb buffer pool使用率未达到100%,但是实例存在OOM的风险,通过设置
innodb_max_lru_pages_pct限制innodb buffer pool的实际使用率,避免innodb buffer pool内存进一步增加导致OOM。
3.5 resize innodb buffer pool 性能优化,减小动态设置innodb buffer pool对业务的影响
对于有OOM风险的实例可以通过动态调整innodb buffer pool大小进行规避。但是对大实例进行调整innodb buffer pool往往会造成性能抖动。
如下图所示分别是动态增大和减小innodb buffer pool的过程。增大buffer pool size的过程比较简单,对并发负载没有太大影响。减小buffer pool size的过程需要将回收区的page转移到非回收区,这个过程需要长时间持有buffer pool mutex,阻塞其他线程无法访问buffer pool。
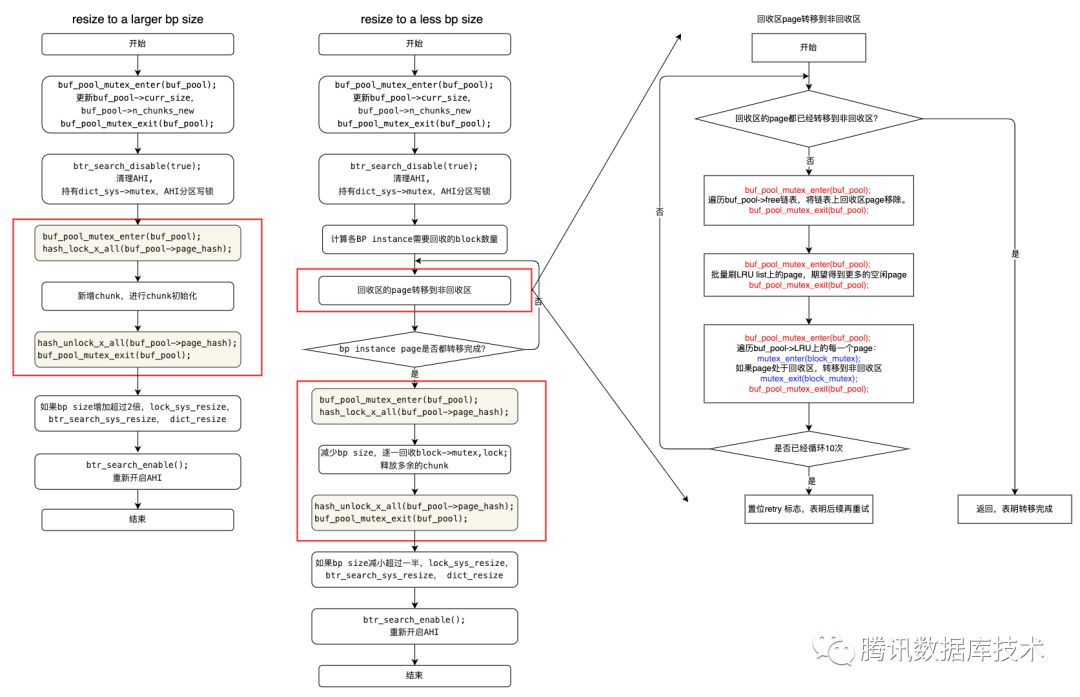
TDSQL-C对resize buffer pool回收page过程进行了性能优化,优化后仅需对回收区的page持有buffer pool mutex。
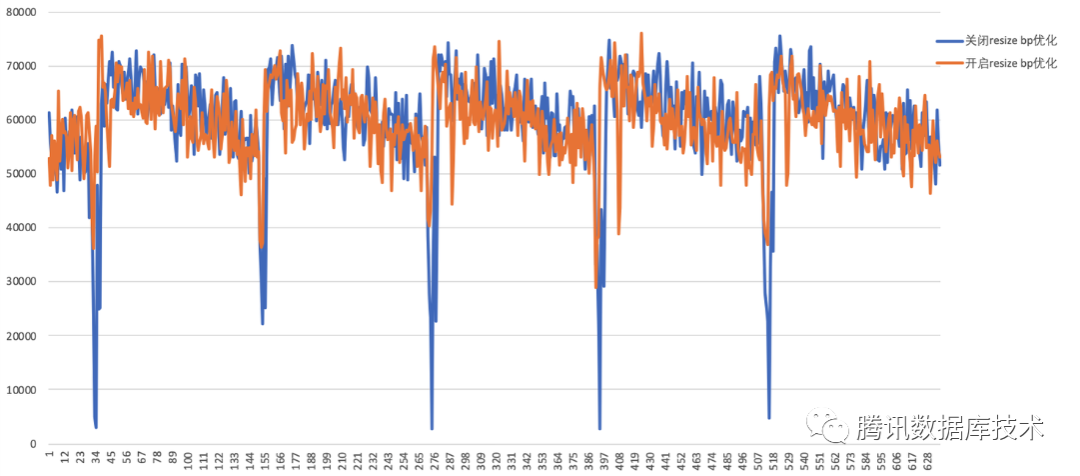
以下是BP在33g和22g之间每隔60s resize 一次,同时利用sysbench进行读写压测,持续观察QPS变化情况。
根据结果可以看到优化后的性能抖动减小,性能下降维持时间缩短。大大减小了动态设置innodb buffer pool对业务的影响。
四、总结
内存溢出一直是软件开发的“老大难”问题,更何况数据库环境更加复杂,SQL语法、数据类型、数据大小、并发数、MySQL参数配置等这些因素都与内存有关。TDSQL-C内核团队在TDSQL-C的内存管理上进行一系列的优化,包括优化server端参数配置降低内存占用、丰富内存监控、增加buffer pool冷热page数查询方便用户设置更合理的buffer pool大小、在即将面临oom风险时限制innodb_buffer_pool的最大使用率避免内存用尽触发oom、优化动态调整buffer pool大小对并发业务的影响。后续我们也会持续进行优化,不断提升TDSQL-C的稳定性和可用性,为用户带来更好的产品体验。





