



作者:ronaldoliu,腾讯 IEG 后台开发工程师
trpc-go 是目前公司运用广泛的一个开发框架,支持多协议扩展,能够一键集成各种公司现有平台的功能,非常方便。那么它到底是怎么做到的呢?
trpc-go 是目前公司里非常火热的一个开发框架,集成了很多开箱即用的功能,非常方便。trpc-go 代码量不算太多,但是写得还是有点绕,直接阅读可能会比较晕。因此本文主要对 trpc-go 的模块设计进行一个分享,帮助大家构建一个整体视图,后续有需要再针对性的去阅读各模块源码即可。
做后端开发的同学肯定接触过不少的框架,就拿 Go 来说,比较常见的框架比如:gin beego echo iris martini 等等。除了 Go,Python 也有著名的 Django Tornado,PHP 中的 Laravel 以及 nodejs 的 express。这些耳熟能详的框架都有个共同的名字,叫“Web 框架”。Web 框架主要是面向 web 开发,业务处理的默认都是 HTTP 请求。而 trpc-go 则有些不同,它是一个 rpc 框架。由于客观历史原因,客户端和服务器的直接交互大多还是 http 请求,但是系统内部大量的微服务之间的交互则并不局限于 http 协议。从性能和可读性的角度来说,thrift dubbo 等协议显然是比 http 更好的选择。trpc-go 作为一个全新的开发框架,如果只锚定了 http,显然受众非常有限。因此它的设计中最重要也是最核心的一点,就是支持多种协议。trpc-go 中很大一部分数据结构抽象都是围绕着多协议支持这个目的来的,搞清楚这一点可以让你更容易地理解 trpc-go
回想一下我们的日常开发工作,我们在开发业务逻辑的时候其实并不关心底层的通信协议,一般来说业务逻辑最理想都是从如下函数开始的:
func handleLogin(req LoginReq) (LoginRsp, error) {
// your logic
}
那么站在框架设计者的角度,如果我们要给用户提供这样的开发体验,我们就必须要做以下工作:
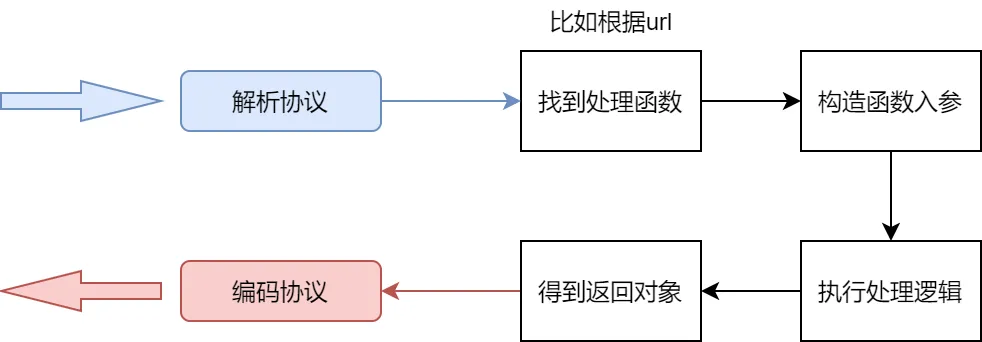
其实包括标准库在内几乎所有的 web 框架都是这个处理流程,看起来也并不是很复杂。但是如果要考虑支持多协议的话,事情就变得麻烦了。首先面临的问题就是,框架怎么从 socket 的字节流中识别出本次请求的协议类型呢?
协议识别
协议识别真的不是一件简单的事情,如果做好了那是可以拿出去卖钱的!!!参考 wireshark 和 fiddler……
但是你从实际应用想一个问题,真的有客户端在一个连接中一会用协议 A 发送数据一会儿用协议 B 吗?显然对于业务逻辑来说,这是个伪需求!没人会这么干。但是请求服务 A 用 A 协议,服务 B 用 B 协议是完全可能存在的。所以 trpc-go 进行了第一个抽象——service。一个 trpc-go 服务可以包含多个 service,每个 service 监听一个端口,使用一种协议!所以对于 trpc-go 来说是不需要做协议识别的,在实例化 service 时就可以确定协议类型,后续都用该协议进行编解码。
真的需要进行协议识别的是一些网关服务,因为各种协议的请求都会被转发到网关的特定端口,网关就必须进行协议识别然后进行可能的协议转换和转发。具体方法就不在本文的探讨范围内了,感兴趣可以参考 envoy 和 linkerd 以及 mosn 等开源网关。
反正协议识别这个事情,trpc-go 不需要。
协议编解码
协议解析是必不可少的一个环节。对于不同的协议,其解析方式都是完全不同的。于是在框架层可以考虑抽象出一个 interface(Codec),不同协议的编解码只要实现这个 interface 就行。有了这层抽象,用户就可以在配置文件中设置服务使用哪个协议进行编解码,然后框架初始化时为该 service 加载对应协议的编解码模块。这个设计看起来很美好,既能够封装足够多的细节,又能够提供快速扩展的能力。
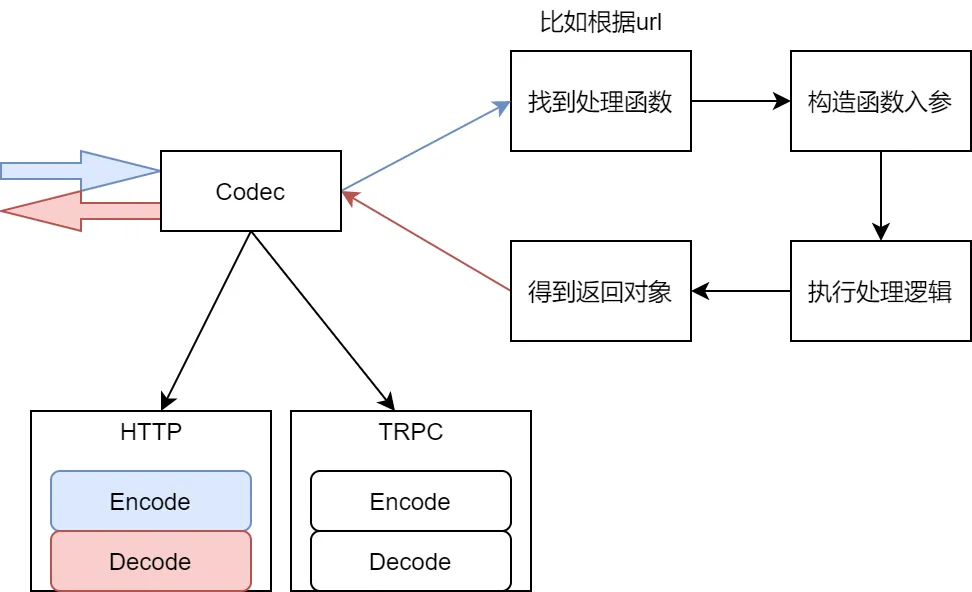
但问题的关键就是这个 Codec 接口应该怎么设计?Encode 和 Decode 的入参是什么,返回什么?举例来说,当我们在接收连接请求时:
func (svr *Service) readLoop(c net.Conn) {
for svr.NotShutDown() {
??? = svr.Codec.Decode(c) // 我们应该期望Decode方法返回什么?
// ...
}
}
我们应该期望 Decode 方法返回什么?这是一个大问题!一般来说用于 RPC 的通信协议可以大致分为 3 个部分:
- 包头(比如固定 8 个字节,前 4 个字节表示 header 长度,后 4 个字节表示 body 长度)
- header(各种协议定制的控制字段)
- body(真正的业务数据)
包头是给解码器的,通过它可以知道整个包的长度有多少个字节,哪些字节是 header 哪些是 body。因此,我们可以把 Decode 方法设计成这样:
type Decoder interface {
Decode(r io.Reader) (Header, []byte)
}
但问题是 Header 这个数据结构应该怎么定义呢?由于不同协议 header 中的字段都不一样,且 header 中有哪些字段很可能是不可枚举的。因此可以把所有协议的 header 都按 http 那样抽象成 map<string, []string>,Decode 方法直接解析出请求中的 Header 和 body。body 的类型是[]byte,因为它经常会有不同的序列化方式。比如在 HTTP 协议中,body 可能是 k1=v1&k2=v2 这样的格式,也可能是{"k1":"v1","k2":"v2"}这样的 JSON。具体使用什么序列化方式,是通过 header 中的字段来指定的。在 http 中就是 Content-Type。所以 body 直接原样解析,后续再根据 header 来进行不同的反序列化,这是很合理的设计方式。
因此我们的 Header 可以这样定义, 然后提供一系列常用方法来方便调用方读取数据,而不是直接去读 map:
type Header struct {
data map[string][]string
}
func (h *Header) GetStatus() int {
return GetInt(h.data["status"]).or(200)
}
// ... 其它Getter
Encode 同理,由于编码时需要 header 和 body,因此:
type Encoder interface {
Encode(Header, []byte) []byte
}
最后整个 Codec 就可以定义为:
type Codec interface {
Encoder
Decoder
}
有了 Codec 这个抽象,框架层面就可以对各种不同协议实现不同的编解码器,然后根据用户配置进行初始化即可,比如:
func (svr *Service) Init(cfg Config) {
protocol := cfg.Protocol // eg: http trpc thrift
svr.Codec = codec.Get(protocol)
}
看起来这是一个很合理的抽象,但却并不符合时代发展潮流。这种设计只能支持像 http1.x 这样简单的协议,换成 http2 这个抽象马上就不够用了!!
连接多路复用
为啥这套抽象对 http2 不够用?主要就是因为连接的多路复用(multiplexing),这里简单讲一下。
首先回想一下“连接池”的概念。连接池其实就是客户端维护了很多到某个服务的长连接,池里的都是空闲连接,每当要发请求就从池里取一个连接,等使用完再放回连接池。

这时你思考一个问题,为什么每次发送请求时必须要从连接池拿一个“空闲连接”?如果在“非空闲连接”上发送了请求,会造成什么问题?

如果多个线程同时用一个连接发送请求,其实客户端发是没问题的,关键是接收返回时,无法确定一个它是对哪个请求的响应。这是最大的问题,所以无奈只能让连接被互斥地使用,保证连接在收到前一个请求的返回前不会发送别的请求。其实包括 http、mysql 在内目前大部分通信协议都是这种单一的 rping-pong 模式,一个请求对一个返回,为了避免频繁 3 次握手,客户端维护多个连接的连接池。
但是最近些年有了很多新的探索,比如 HTTP2 和 HTTP3。浏览器加载一个页面可能要请求很多个图片文件、js 文件还有 html 文件,如果使用一个连接,那么只能串行地加载,速度非常慢。如果并行加载,那么就需要建立很多个连接。并且浏览器为了安全,限制了一个页面对某个域名的最大连接数(6 个?),这对于首页需要加载很多资源的应用是一个不小的挑战。然后有人就开始想办法了:用多个连接发请求,是因为单一连接一次只能发送一个请求,如果发送多个请求,服务端就会返回多个响应,这时候没办法确定哪个响应对应哪个请求。那是不是修改一下协议,每个请求附加一个 streamID,服务端返回的响应里也加上对应请求的 StreamID,就能区分了呢?
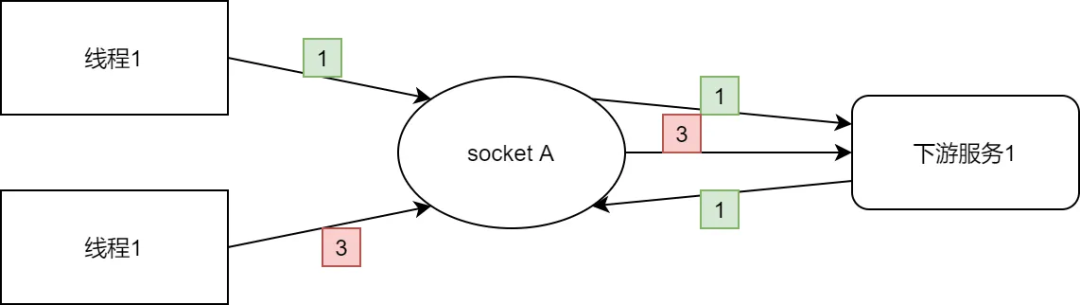
这其实就是 HTTP2 中的核心概念!所谓的连接多路复用。
如果在通信协议中增加 streamID,相当在一个物理的连接上于建立了无数虚拟的通道(用 StreamID 标识)。这样就可以利用单个连接同时发送多个请求了。然而受限于 TCP 协议的限制,如果某个请求发生丢包会进行重传,重传就会阻塞其它请求。这种一荣俱荣一损俱损的特点也算是 http2 的一个不小的瑕疵,因此又有了基于 UDP 的 HTTP3…这里就不多展开了。
以上说了这么多连接的多路复用,其实主要是为了讲明白上面定义的那个 Codec 的接口讲面临的问题。拿 http2 举例,以下是 http2 的一个数据帧:
+-----------------------------------------------+
| Length (24) |
+---------------+---------------+---------------+
| Type (8) | Flags (8) |
+-+-------------+---------------+-------------------------------+
|R| Stream Identifier (31) |
+-+-------------------------------------------------------------+
| Frame Payload (0...) ...
+---------------------------------------------------------------+
它的包头指示了包的长度,后面还跟了 Type Flag 以及一个个 4 字节的 StreamID。在 Frame Payload 里,再划分成 HEADERs 和 DATA,分别对应 http1.x 中的 header 和 body。因此解析协议时实际上要解析出 3 个部:
- 协议头(type + StreamID)
- header
- body
除了 http2,实际上现在很多企业内部协议都支持连接多路复用,比如 trpc:
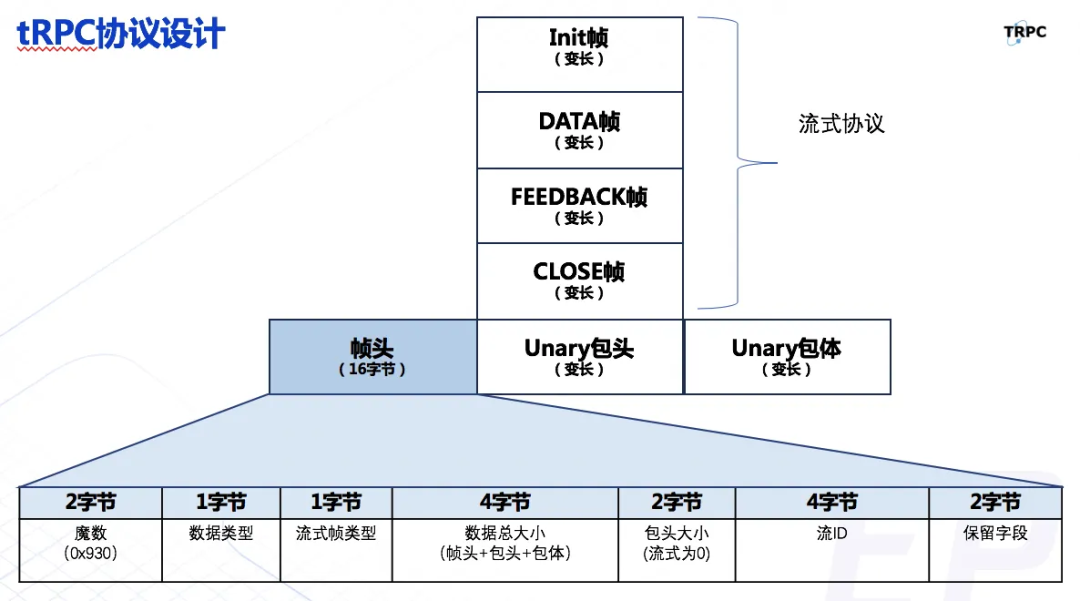
除了多路复用需要用到的 StreamID,对于 RPC 请求来说包头里面还需要包括 rpcname,指明你要调用远端的哪个服务的哪个方法。当然还可能包含很多额外的字段,比如用来做链路追踪的 traceID、caller callee 等,用来区分测试环境和线上环境的 EnvName……
如果考虑这些,那么 Header 应该怎么定义呢,还能继续沿用 map<string, []string>这个定义吗?这显然是有问题的,万一用户自己透传的 key 和控制字冲突了呢?并且这个 Header 解析出来并不只是给请求用,业务逻辑执行完返回请求给客户端时,进行序列化也需要这个 Header,因为对于多路复用的请求,至少 StreamID 得和请求的 StreamID 一样吧?只保证 StreamID 一样就行了吗?也不好说,谁知道私有协议都会干些啥呢?所以 Header 到底要怎么设计,确实是一个不小的挑战
对于这个问题,trpc-go 的办法就是把一些常见的控制字独立出来,对于其它字段,不同协议的 Codec 如果需要就放到 metadata 里,最终效果如下(为了简化代码,用 C#代替):
class Msg {
public string envName {get; set;}
public HashTable<string, []string> metadata {get; set;}
public string rpcname {get; set;}
public string caller {get; set;}
public string callee {get; set;}
// ...
}
最终 trpc-go 的 Codec 定义如下:
// Codec 业务协议打解包接口, 业务协议分成包头head和包体body
// 这里只解析出二进制body,具体业务body结构体通过serializer来处理,
// 一般body都是 pb json jce等,特殊情况可由业务自己注册serializer
type Codec interface {
Encode(message Msg, body []byte) (buffer []byte, err error)
Decode(message Msg, buffer []byte) (body []byte, err error)
}
这里的 Msg 是一个巨大的 interface,一共有 69 个方法。然而越大的 interface 它的抽象能力实际上就越弱,这里使用 interface 其实和用 struct 已经没什么区别了。interface 本质是为了动态分发,但是面对需要实现 69 个方法的 interface,几乎没有调用方能够再实现一个……针对多协议扩展的抽象,我更倾向于蚂蚁开源mosn的设计。但话说回来,trpc-go 这种设计实际证明是可用的,Maybe that's enough
基于这种 Codec 的设计,为不同协议实现编解码功能就相对容易很多了。解析时,如果恰好 Msg 定义了相关字段,就可以直接设置 Msg,如果没有定义,就扔到 Msg 的通用结构里,后续需要在进行 type cast。
Transport
Codec 只是负责对协议进行编解码,除此之外还有个 Transport 的概念也很重要。之前我提到过,即使 http2 相对于 http1.x 是一个巨大的进步,但是它依然有它的不足。因此有了后来的 http3(QUIC)。由于其出色的性能特别适合高实时的场景,这个协议已经被多个短视频厂商运用到生产环境了。但是问题是,http3 并不是基于 TCP 的协议,而是基于 UDP 的。由于 trpc-go 要能够适配各种协议,那么基于 UDP 的也需要考虑。
一般的 TCP 服务都有一个 AcceptLoop,比如:
func ListenAndServe(addr) {
fd, _ := net.Listen("tcp", addr)
for {
conn, err := fd.Accept()
setting(conn)
go serveConn(conn)
}
}
在 TCP 服务中,由于有“连接的概念”,所以我们每次需要在监听句柄上获取新的连接。于是有了上面的 AcceptLoop。但是 UDP 没有连接的概念,监听之后直接读数据,因此它是没有 AceeptLoop 的。因此 trpc-go 引入了 transport 的抽象,不同协议(udp tcp)有一个自己的 transport,各自实现自己的 ListenAndServe:
// ServerTransport server通讯层接口
type ServerTransport interface {
ListenAndServe(ctx context.Context, opts ...ListenServeOption) error
}
通过 Transport 和 Codec 这两层抽象,trpc-go 就基本可以做到适配各种不同的网络通信协议,不论是 UDP 还是 TCP,是否 multiplexing,这些都能支持。业务在开发时就完全不需要关心底层的协议编解码功能,Great!
考虑到 Codec.Decode 也是一个比较耗时的过程,因此 trpc-go 在 transport 额外增加了一个 Framer 抽象:
// FramerBuilder 通常每个连接Build一个Framer
type FramerBuilder interface {
New(io.Reader) Framer
}
// Framer 读写数据桢
type Framer interface {
ReadFrame() ([]byte, error)
}
它用于从网络中切割出一个完整的请求包,但不做进一步解析。这样可以快速地读出请求的整个包,然后主循环可以继续读下一个包,而让耗时的 Codec.Decode 可以在新的 goroutine 中进行,并行化!如果没有 framer,那就必须等 codec.Decode 完成了,才能继续处理下一个包。这算是一个小优化吧!
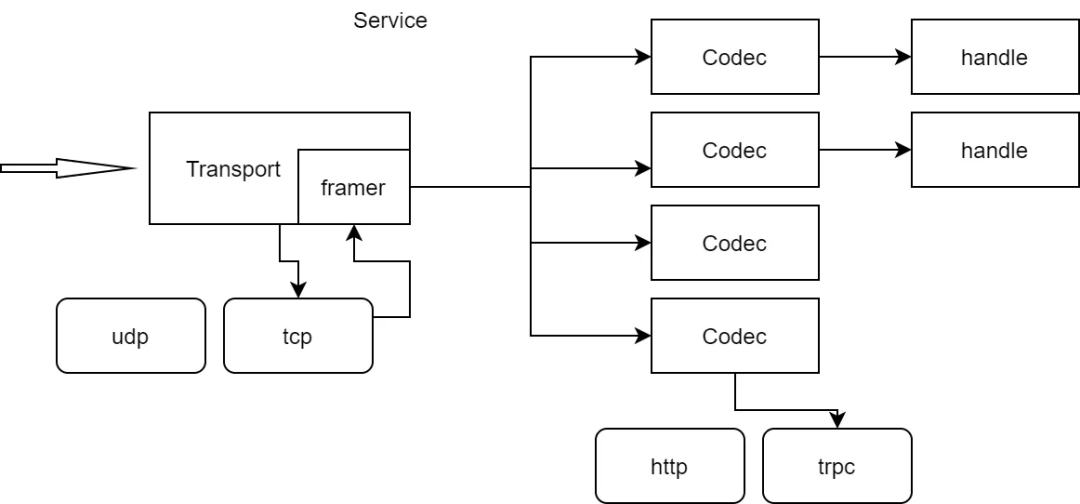
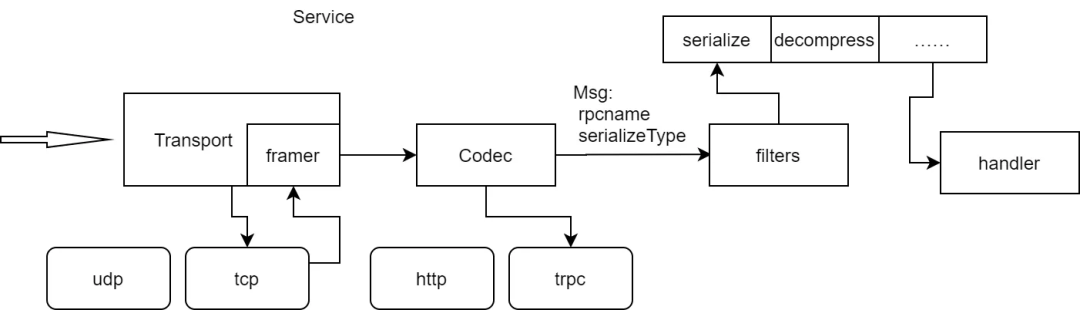
以上基本就是 trpc-go 提供的协议层抽象。通过这层抽象,后续的业务代码就不需要关心底层通信协议的细节。
Serializer
通信协议主要是为了更好地传输数据,但是具体的数据是啥呢?目前为止我们都是用[]byte 这么一个字节流来保存。实际上业务数据的编码方式是各种各样,仅在 http 协议中,常见的编码方式就有:
- multipart/form-data
- application/x-www-form-urlencoded
- application/json
除了 http 的这几种序列化方式,我们常用的还包括:
- protobuf
- thrift
- jce
- …
Serializer 的作用就是把[]byte 反序列化成一个特定的结构体对象,方便业务处理。而协议的 payload 具体使用什么方式进行序列化和反序列化,一般都是在请求帧的头部指定。因此 Codec 需要在解析请求时设置 Msg 的 SerializeType,后续处理通过 SerializeType 找到对应的序列化工具,进行真正的序列化。
流程图
启动流程:
- init: 各模块注册
- transport
- codec
- filter
- framer
- plugin
- 读取配置文件(trpc.yaml)
- 根据配置文件加载插件:
- log
- tracing
- registry
- selector
- metrics
- ...
- 启动 Admin 服务
- 根据配置实例化每个 Service
- 实例化 filters
- 设置 protocol trasnport codec
- 设置 TLS
- 设置超时等各种配置……
- 设置 handler(重要:transport 对每个请求都会调用这个 handler,由这个 handler 来执行 codec 等各种操作)
- 注册通过 pb 生成的业务 service(其实就是注册不同的请求该最后调用哪个函数)
- ListenAndServe
- 监听配置的端口
- acceptLoop
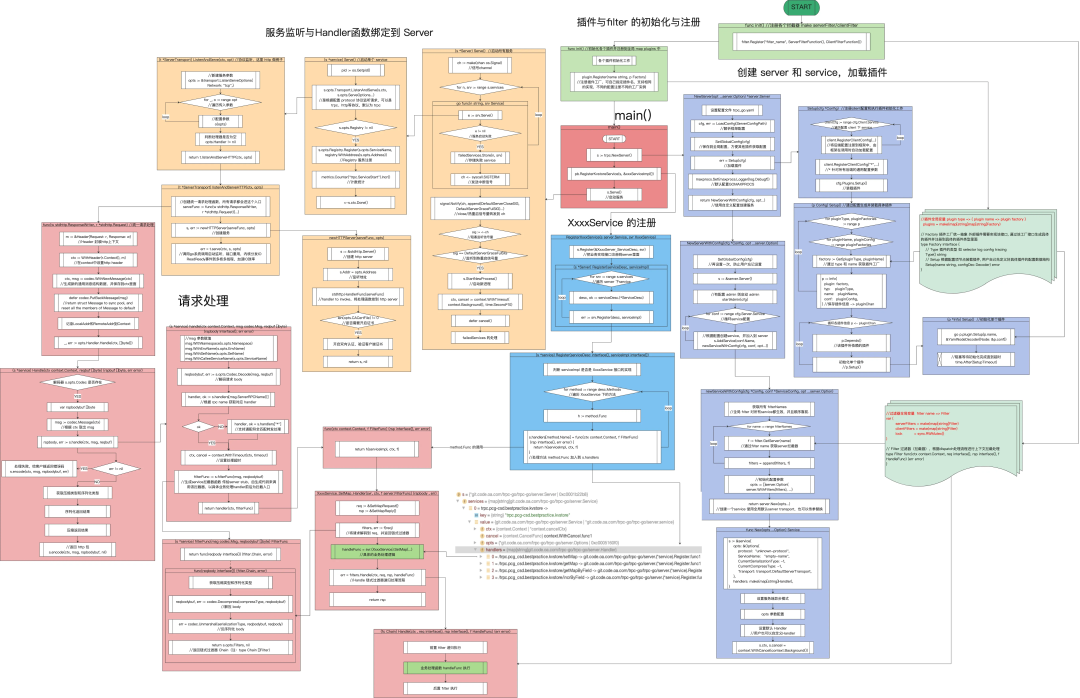
请求处理流程(trpc 为例)
- getFrame 读取请求帧
- 调用 Service 的 handler(multiplexing 场景下可以通过配置设置为并发)
- 创建空的 Msg
- 调用 Codec.Decode(msg, req)
- 根据 Msg.ServerRPCName 找到业务注册的 handler(由 pb 生成的)
- 根据 Msg 生成 filters
- 递归调用 filters(最后一步是真正的 handler)→ 得到 rsp
- Serialize 编码
- Compress
- Codec
- 写回给客户端
这儿有一个 KM 上同事总结的非常详细的流程图(by: @smallhowcao):
Filters
说完了整体流程,其实对 trpc-go 整体已经理解得差不多了,剩下一个比较重要也是比较难以理解的就是 Filter。Filter 本来不复杂,其实就是各种 Web 框架中的 middleware 模式。但是 trpc-go 在设计时要考虑 pb 生成的 service handler 函数签名的不确定性,就使得整个 middleware 链条看起来稍微有些别扭。
middleware 模式就像一个洋葱一样:
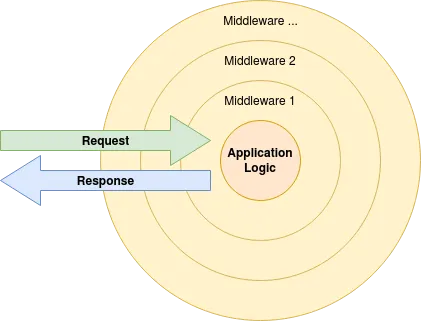
请求先被第一个 filter(middleware)处理,然后依次交给后续的 filter,最后交给业务逻辑处理。处理完之后又从内层的 filter 一层一层向外层返回,最后返回给客户端。这种模式其实就是 trpc-go 文档中说的支持在业务逻辑前和后进行 hook,看这个图就能理解,请求先一层一层地进入洋葱,再一层一层地出来,这两个地方都可以写逻辑,也就是所谓的 hook。
trpc-go 给 filter 定义的签名如下:
type Filter func(ctx context.Context, req interface{}, rsp interface{}, f HandleFunc) (err error)
// HandleFunc 过滤器(拦截器)函数接口
type HandleFunc func(ctx context.Context, req interface{}, rsp interface{}) (err error)
框架在初始化时,把用户配置的 filter 都按顺序保存成了一个数组:
// WithFilters 添加服务端拦截器,支持在 业务handler处理函数前后 拦截处理
func WithFilters(fs []filter.Filter) Option {
return func(o *Options) {
o.Filters = append(o.Filters, fs...)
}
}
对于 filter 的函数签名,其实 ctx req rsp 都好理解,关键最后这个 f 是什么?其实 f 就表示 filter 链中的下一个 filter,也就是图里洋葱的下一层。比如我们写个最简单的 filter:
func CostFilter(ctx context.Context, req interface{}, rsp interface{}, f HandleFunc) (err error) {
start:= time.Now()
err = f(ctx, req, rsp)
cost := time.Sub(start)
fmt.Println("请求耗时为: %d毫秒", cost.Milliseconds())
return err
}
这个 filter 记录一个开始时间,然后直接执行后面的 filter。后续的 filter 又会调用它下一层,层层递归,直到业务 handler……最后再一层一层向上返回。等 f 执行完,相当于后续所有 filter 和业务逻辑都执行完了,这时候计算一下时间差,这就是本次请求处理耗时。
这个 f 感觉有点神奇,它可以把整个 filter 链一环一环串起来,到底怎么实现的呢?一般来说 onion 模式的 middleware 有两种实现方式,trpc-go 采用的是自顶向下的方式:
// Chain 链式过滤器
type Chain []Filter
// Handle 链式过滤器递归处理流程
func (fc Chain) Handle(ctx context.Context, req interface{}, rsp interface{}, f HandleFunc) (err error) {
n := len(fc)
curI := -1
// 多个Filter,递归执行
var chainFunc HandleFunc
chainFunc = func(ctx context.Context, req interface{}, rsp interface{}) error {
if curI == n-1 {
return f(ctx, req, rsp)
}
curI++
return fc[curI](ctx, req, rsp, chainFunc)
}
return chainFunc(ctx, req, rsp)
}
Handle 的 f 其实就是洋葱的中心——业务逻辑,这个在调用 Handle 时由框架设置好。然后 Handle 内部是一个递归调用的闭包,如果所有 filter 都执行完了,就执行 f,如果后面还有 filter 就执行 filter,并且把自己设置为待执行 filter 的 f 函数……
这里实现看起来比较绕,主要原因是 Filter 的函数签名和 HandleFunc 的函数签名不一致,因此需要 chainFunc 来包一下。在其它很多框架中,filter 和 handler 签名是一致的,这时就有一个更好理解的实现,可以参见:chi
Plugin
trpc-go 中另一个比较重要的概念就是 Plugin,正是通过各种 plugin,我们的 trpc-go 服务才能无缝地和公司的各种系统对接,才能实现需要什么功能只需要一个 "_ import pkg"即可。
其实 Plugin 和 trpc-go 是比较松耦合,或者可以说,“基本没啥关系”。但是,一个很重要的问题是,大部分插件都需要进行配置才能使用,比如 log metrics 007 等等。如果 plugin 和 trpc-go 完全隔离,那么为了实例化那些插件,我们的项目里就可能存在 N 个不同的配置文件。为了让配置好管理,用户就不得不造一些轮子让这些配置能融合到一个文件中方便管理。这其实就是 trpc-go 框架和 plugin 的关系。
trpc-go 约定了一种配置格式,插件的配置都按那种格式配置到 trpc.yaml 中,然后 trpc-go 根据插件名找到对应插件,然后把该插件的配置分离出来,用这部分小配置去实例化插件。这样对插件唯一的约束就是插件必须要支持通过 yaml 格式进行配置,至于 yaml 配置的格式完全可以自定义。
具体来说,plugin 配置在 trpc-go 保存为 type Config map[string]map[string]yaml.Node
实际配置如下:
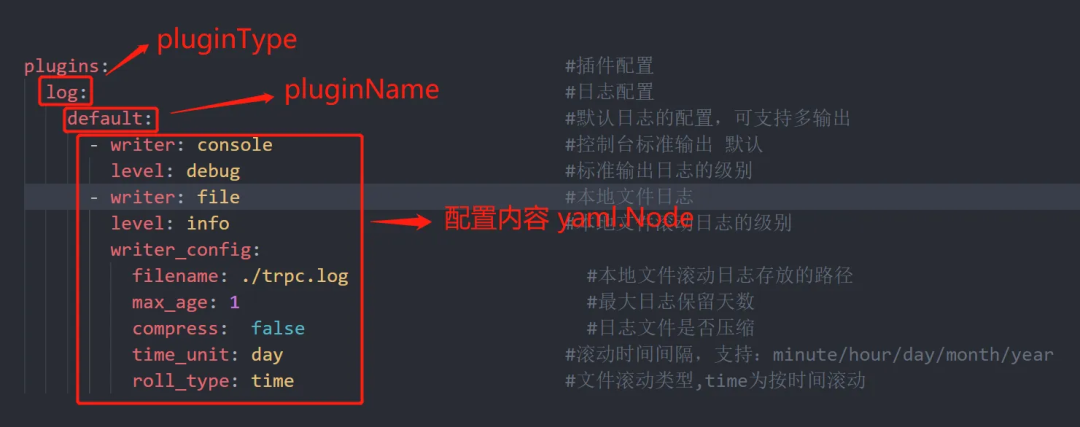
trpc-go 框架在初始化插件的过程中就会遍历这个 Config 配置,然后去查是否有通过 init 注册过 Type 为 pluginType,name 为 pluginName 的插件,如果有调用插件构造函数的 Setup 方法,把下面对应的一坨 yaml 配置扔给它,它自己去处理。这样插件在实现的时候也非常容易,因为它接收到的配置都是自己可控的。
并且所有的配置都统一放到 trpc.yaml 文件中,非常便于管理。另一个好处是,针对这个 trpc.yaml 文件,可以给容器预设一些系统变量,比如 {port], ...,然后部署平台根据容器环境去替换这些变量。
最后
在以前的工作中我也接触过很多框架开发的工作,但我觉得 trpc-go 真正是一个设计优秀的框架(虽然部分代码实现还不够好,但是都是小问题,可以慢慢改)。它的扩展性非常强,并且生态非常强大,能够非常容易地和各种监控、日志、发布系统进行结合,配合 123 平台的能力,为业务开发提供了很大的助力!
本文只是我个人对 trpc-go 的一些理解,如果有误欢迎大家指正。





