


杨豪,腾讯云研发工程师,腾讯云智聆口语评测研发骨干。目前负责腾讯云智聆口语评测整体架构优化与系统迭代,专注于降本增效与服务可靠性提升。
邓琨,腾讯云高级研发工程师,专注于微服务云原生架构探索。负责智聆口语评测自动化运维上云建设,助力业务降本增效。
背景介绍

腾讯云智聆口语评测(Smart Oral Evaluation,SOE)是腾讯云推出的中英文语音评测产品,支持从儿童到成人全年龄覆盖的语音评测,提供单词、句子、段落、自由说等多种评测模式,从发音精准度、流利度、完整度等全方位打分机制,与专家打分相似度达 95% 以上,可广泛应用于中英文口语教学场景中。
在降本增效的大环境下,业务积极寻求成本更优的解决方案,且由于已经积累了 IDC 物理机、云上虚拟机和云上 Serverless 容器服务等多套部署环境,业务架构十分臃肿,运维难度非常高,业务急需一套更加统一的方案降低系统复杂度。
问题与挑战
产品侧的降本诉求
问题
在当前降本增效大环境下,如何控制产品成本成为一个越来越重要的命题,经历了两个发展时期后,我们不得不试着上手抽丝剥茧,尝试解决这个问题。
挑战
因为业务发展历史及业务架构原因,当前资源 buffer 较多,资源利用率较低,系统成本居高不下,主要有以下两个问题:
扩容成本非常高:由于本身是 AI 评测类业务,依赖大量 GPU 资源,而 GPU 机器从资源申请到交付,再到服务部署调试与流量接入,周期通常是天级的,无法应对早晚高峰的尖峰流量,所以需要为高峰期预留大量 buffer。
资源流转效率低:同时业务侧存在中英文评测服务,AI 引擎是两套模型,而模型间的部署切换成本也比较高,这也导致我们需要预留双份的 buffer。
客户侧日渐丰富的流量模型
问题
日渐丰富的业务场景:在工作日非工作日、早晚高峰和中英文评测的多种条件组合下产生了非常多场景,通过提前备量去 cover 所有场景成本是不可行的。
无法预估的业务增量:部分客户的量受疫情影响非常大,且经常是不可预期的,客户自己也无法预估评测用量会达到什么量级,这也导致我们无法精准地提前备量。
削不掉的尖峰流量:部分客户存在非常明显的尖峰流量,用户会集中在晚高峰的某几个时间点进行评测,尖峰流量通常是平峰期的10倍以上,且客户依赖实时结果返回,无法通过异步评测的方式削峰。
挑战
运维难度高:当前架构下无法支持业务侧高效地进行资源流转、更无法快速完成弹性扩容。
服务质量难保障:引擎服务故障节点剔除依赖人工操作,无法快速完成故障自愈;引擎服务部署方式多样,物理机/虚拟机/容器方案并存,无法搭建统一的可观测体系。
新架构
需求
资源利旧:业务侧绝大部分机器还在 IDC 物理机房,且物理机性价比高于虚拟机,上云过程中期望能把这部分机器利用起来,降低整体成本。
网络连通:云上云下服务网络需打通,且业务侧跨地域调度流量容灾的需求,引擎层需要能够被多集群接入层访问。同时,由于不同机型不同规格的引擎层消费能力不同,至少需要支持自定义权重的静态负载均衡策略。
拥抱云原生:升级系统架构,落地混合云方案,全面拥抱云原生。云原生生态下已经有非常多最佳实践与解决方案,业务面临的许多问题在云原生场景下都能找到很好的解法,把业务搬迁上云不是目的,上云是更高效、优雅的解决业务面临的服务扩缩容、服务故障自愈、服务可观测等问题的手段。
选型 - TKE 注册节点集群
能力介绍
TKE 注册节点(原第三方节点)是腾讯云原生团队针对混合云部署场景,全新升级的节点产品形态,允许用户将非腾讯云的主机,托管到容器服务 TKE 集群,由用户提供计算资源,容器服务 TKE 负责集群生命周期管理。业务侧可以通过注册节点的特性,将 IDC 主机资源添加到 TKE 公有云集群,确保在上云过程中存量服务器资源得到有效利用,同时支持在单集群内同时调度注册节点、云上 CVM 节点及云上超级节点,便于将云下业务拓展至云上,无需引入多集群管理。
添加了注册节点的集群,可能包含众多不同网络环境的计算节点,如 IDC 网络环境和公有云 VPC 网络环境的计算节点。为了屏蔽底层不同网络环境的差异,腾讯云原生团队推出了基于 Cilium Overlay 的混合云容器网络方案。实现在容器层面看到的是统一的网络平面,使得 Pod 无需感知其是运行在 IDC 的计算节点还是公有云的计算节点,加上云梯环境与内网环境本就是互通的,这也就奠定了智聆业务上云选型的基础。
TKE 注册节点架构
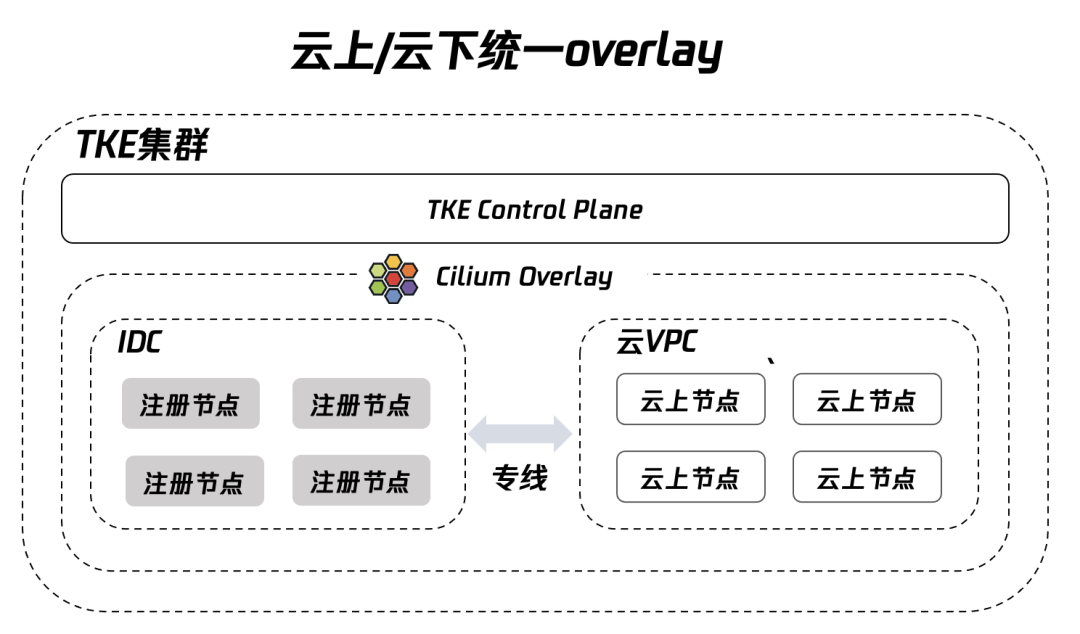
(图自[注册节点-网络模式]官网文档:https://cloud.tencent.com/document/product/457/79748)
业务架构方案
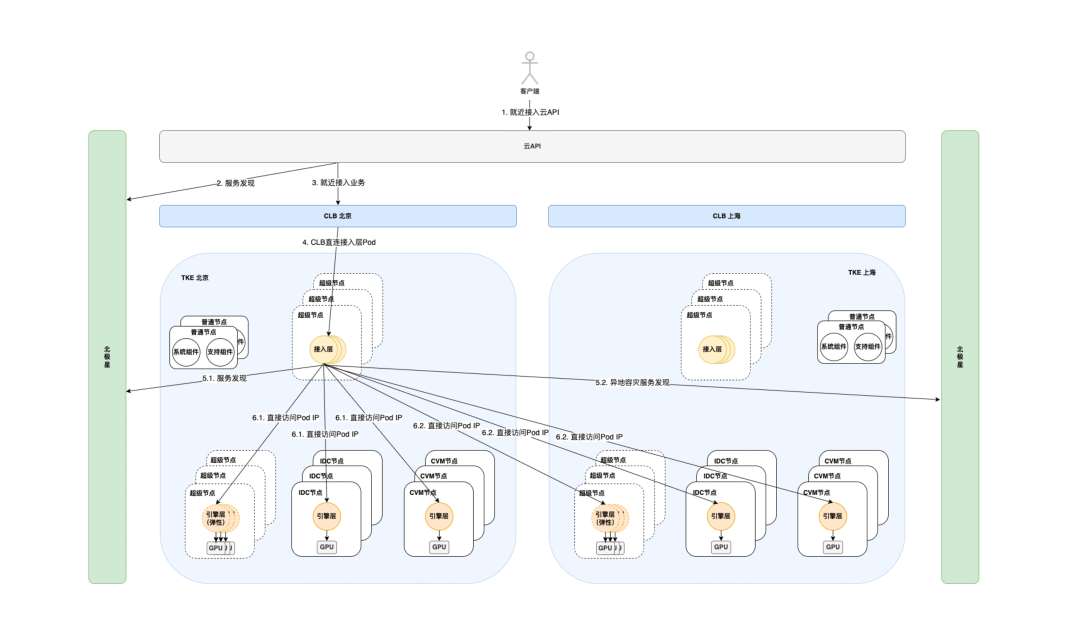
在新架构各层部署方式较平台期时期都有了较大改变:
1、接入层部署在超级节点上,充分利用资源弹性能力;
2、引擎层服务通过不同的 Deployment 部署在 IDC 节点、CVM 节点和超级节点上,均以 Pod 的形式对外服务,屏蔽掉部署环境的区别;
3、基于第二点移除了Serverless容器服务 Pod 的流量接入层,减少一次转发,优化流量调度;
流量路径
客户流量就近接入云 API 网关后,云 API 网关通过北极星名字服务进行服务发现,实现流量就近接入业务侧 CLB。业务侧 CLB 直连接入层 Pod,流量到达业务侧后,接入层服务再次根据名字服务通过北极星进行服务发现,获取 RS IP 后请求引擎层消费。新方案在接入层屏蔽了引擎部署环境和各资源池的区别,接入层仅通过配置去北极星获取对应 RS IP 后请求即可,降低了流量调度的复杂度。
服务部署
接入层
接入层通过节点亲和性调度至超级节点部署,通过 HPA 配置利用云上弹性扩缩容能力进行削峰填谷,对比部署在 CVM 节点上的方案有以下几个优势:
1、扩缩容更方便、更灵敏:若部署在 CVM 节点上需要配置 Cluster Autoscaler 使用,需要先扩容出 CVM 节点,再扩容 Pod,耗时会达到分钟级,而超级节点可以实现秒级扩容;
2、成本更优:CVM 节点加入集群后需要扣除集群管理预留的部分,且集群组件本身有超10个 DaemonSet,也会额外再占用一部分资源,实际资源使用率明显低于超级节点;
3、管理复杂度更低:不需要维护节点资源,超级节点可按需添加,根据业务情况灵活调整;
引擎层
引擎层则需要充分利用 TKE 集群注册节点能力,通过节点亲和性配置分别部署在 IDC 节点、CVM 节点和超级节点上,其中 IDC 节点为利旧资源,CVM 节点为后续常备的基础资源,超级节点为弹性伸缩资源。
既然前面接入层部署时讲了那么多超级节点的优点,那引擎层部署时为什么又需要 CVM 节点呢?
成本更优
引擎服务不仅依赖于 GPU 资源,对 CPU/MEM 也有高的需求,而超级节点支持的 GPU 节点规格有限,推理型 GI3X 机型相对于Serverless容器服务弹性出来的 T4 卡规格具有更强的 CPU 和更多的 CPU/MEM 配比,对于业务侧的性价比更高。
服务发现
北极星
接入层与引擎层整体均借助北极星进行服务发现,但根据接入层与引擎层需求选取了多种暴露服务的方式。
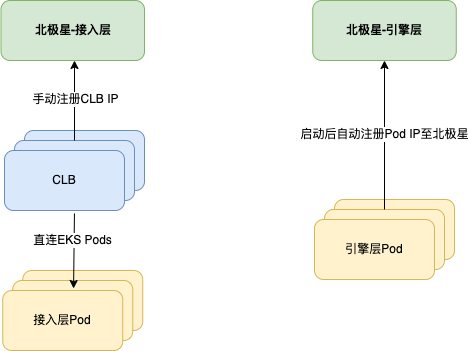
接入层
接入层通过内网 LoadBalancer 型 Service 暴露服务,北极星绑定 LB IP。业务还采用了 LB 直连 Pod 的模式减少 NodePort 转发,这里其实最开始没有采用直连的形式,也是踩了个坑,后文中会提到。
引擎层
IDC 节点与 CVM 节点上的引擎容器通过 Docker Host Network 网络模式与节点共享网络堆栈,使得容器暴露端口可直接映射到节点上,故北极星直接绑定 Pod IP(也是节点 IP)即可,而超级节点上的 Pod IP 为真实的内网 IP,也能直接在北极星上绑定 Pod IP,通过这样选型可以屏蔽掉 Pod 调度到不同节点上的差异,统一上报为容器 IP。
事实上如果要实现以上效果方案是比较多的,这里也大致对比了下,可以根据实际情况进行选择。业务侧刚好单个 IDC/CVM 节点仅运行一个引擎 Pod,且节点上也不会再运行其他服务,故不存在端口争用的问题,对比下来业务侧选择了性能更优,实施也更为简洁的 hostNetwork 方案。
| 实现方案 | hostNetwork | hostPort | NodePort Service |
|---|---|---|---|
| 备注 | - | - | 需配置添加以下配置防止流量调度至其他 Node上 .spec.externalTrafficPolicy: True |
| 优点 | 性能最优 | - | 应用广泛,也是 K8s 官方更推荐的方案不存在端口争用的问题,支持一个 Node 上运行多个 Pod 的情况 |
| 缺点 | 可能存在端口争用的问题 | 可能存在端口争用的问题;需要业务侧自行维护 Node 与 Pod 的映射关系;多一次转发,会有一定的性能损耗 | 需要业务侧自行维护 Node 与 Pod 的映射关系;多一次转发,会有一定的性能损耗 |
服务运维
灰度发布
接入层
前文中提到使用 Service 来暴露接入层服务,而 Service 通过 Label Selector 来选取 Pod,我们可以通过两个 Deployments 来管理这组 Pod,然后通过调整 Pods 数量来调整流量比例,从而实现灰度发布的功能。
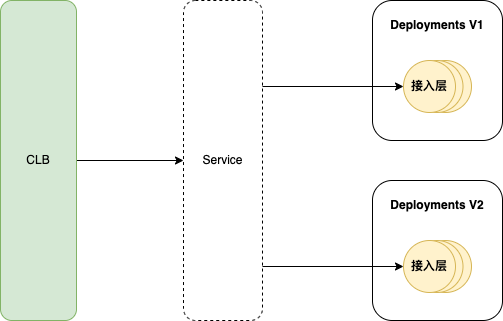
需要关注的是我们采用 LB 直连 Pod 的方案,这种方案下默认仅在 Pod 被删除后才会从 LB RS 中移除,为实现服务优雅停机需新增两条配置,这样在 Pod 处于 terminating 状态时就会把 CLB RS 的权重调0,防止流量持续接入。
kind: Service
apiVersion: v1
metadata:
annotations:
service.cloud.tencent.com/direct-access: "true" ## 开启直连 Pod 模式
service.cloud.tencent.com/enable-grace-shutdown: "true" # 表示使用优雅停机
name: my-service
spec:
selector:
app: MyApp
引擎层
引擎层的实现更为简单,前文中也提到引擎服务的注册与反注册是由服务自身完成的,我们只需要与接入层一样调整两组 Deployment 的数量就能实现灰度比例控制。
服务可观测
日志
日志方案统一使用 CLS 采集,并且通过 CLS 跨地域采集的功能采集至同一个日志 topic 中进行检索分析,简化现网日志检索复杂度。
监控
监控方案统一为云监控方案,通过云 Prometheus 采集基础指标及业务指标进行展示分析,减少多套监控体系学习与维护成本。
基础监控 - 云 Prometheus 接入集群监控后自带多个面板,基本符合需求,业务侧只需要完成 GPU 数据的采集上报即可。
业务监控 - 业务侧引入 Prometheus SDK 暴露并配置 job 进行采集即可。
告警
告警方案也统一为云监控告警,借助云监控的能力覆盖邮件、企微微信、电话等多种渠道,减少告警渠道维护成本与多套告警规则配置学习成本。
异常节点剔除
当 Pod 异常时应该及时切断流量,保证流量不会持续进到异常pod内导致现网服务受损,提供两种方案,经调研业务侧选择方案二:
方案一:Liveness Probe
配置存活探针,业务健康检查异常时直接杀死 Pod,而后进入上文提到的 Pod 优雅退出流程,阻断流量进入异常 Pod。
方案二(推荐):Readiness Probe + Readiness Gate
配置就绪探针,业务健康检查异常时将 Pod 状态置为 Not Ready,配合 ReadinessGate 机制,当检测到 Pod 状态为 Not Ready 时将相应 LB RS 权重调0,阻断流量进入异常 Pod。
该方案的好处是能够保留事故现场用于 debug,便于快速定位问题,配合云监控告警即可实现快速感知。
调度方案
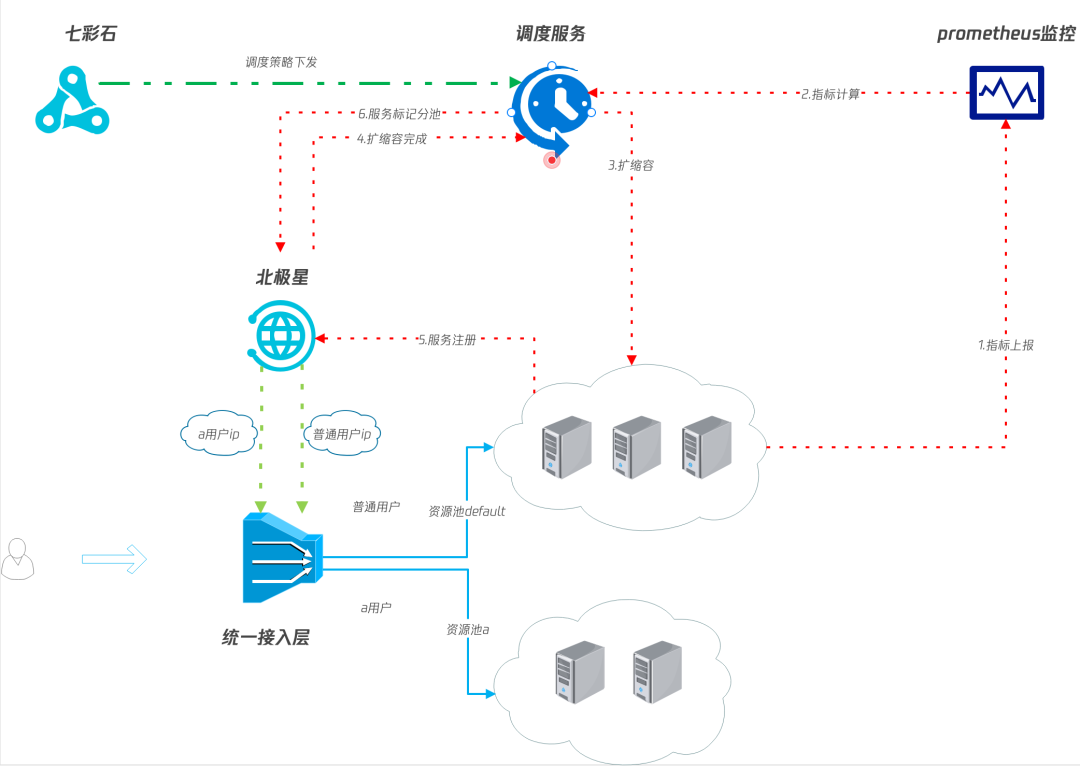
服务调度-动态扩缩容能力
业务侧之所以选择自研 scheduler 服务是因为业务侧有灵活的扩缩容诉求,除了常规的 HPA&HPC 的能力,scheduler 服务还有以下功能:
1、HPA&HPC 规则均作用于资源池级别,原生 HPA&HPC 仅支持 Deployment/StatefulSet 级别;
2、业务侧有资源流转的需求,如北京地域早高峰中文评测的量很高,而英文早高峰相对较低,需要支持通过调整中英文引擎 Pod 数量的方式提高资源整体利用率;
3、业务侧有保障扩容成功率的需求,由于业务侧需要的 GPU 资源数量较多,故需要通过切换规格和切换地域等方式提高扩容成功率;
流量调度-资源隔离
引擎层资源隔离借助北极星动态路由的能力实现,服务(大池子)、别名(公共池/各大客户专有池)和别名路由(池子划分规则)需要提前创建好。自研 scheduler 服务根据配置为引擎 Pod 打标并注入别名列表,接入层在拿到对应别名后向北极星获取 RS IP 请求即可,不需要感知流量路由到哪个池子。
前置工作
1、创建统一的北极星服务;
2、创建各资源池北极星别名;
3、在北极星服务下创建各别名路由规则,选取对应 label 的 RS。
引擎启动注册流程
1、引擎服务启动后自行注册至统一的北极星名字服务下;
2、scheduler 服务监听到存在未打 label 的 RS 则根据规则及各资源池当前负载情况进行打标,用于标记是哪个资源池;
3、scheduler 服务根据规则判断当前资源池是否生效,若生效则注入接入层访问引擎层的别名列表。
用户请求流程
1、接入层获取别名;
2、接入层通过别名向北极星获取 RS IP;
3、接入层请求 RS IP;
取得效果
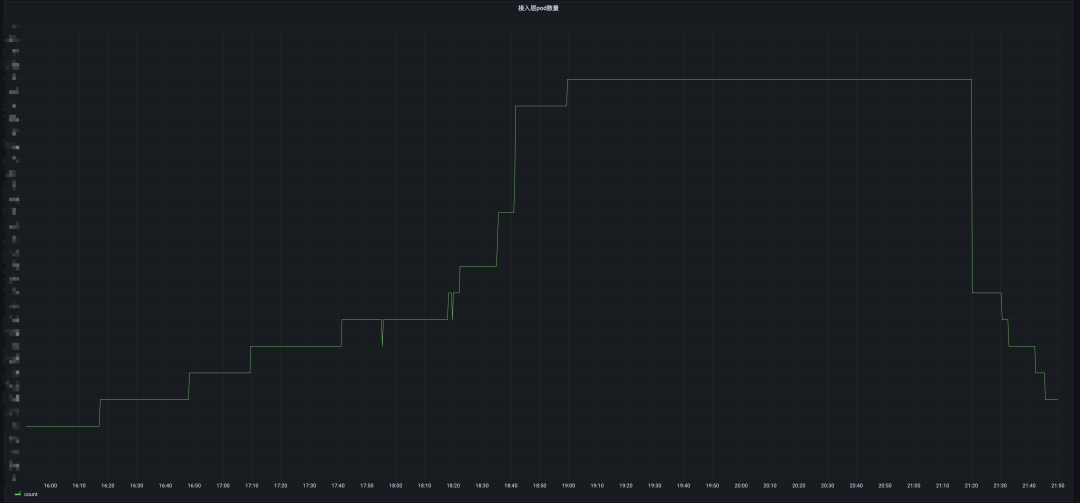
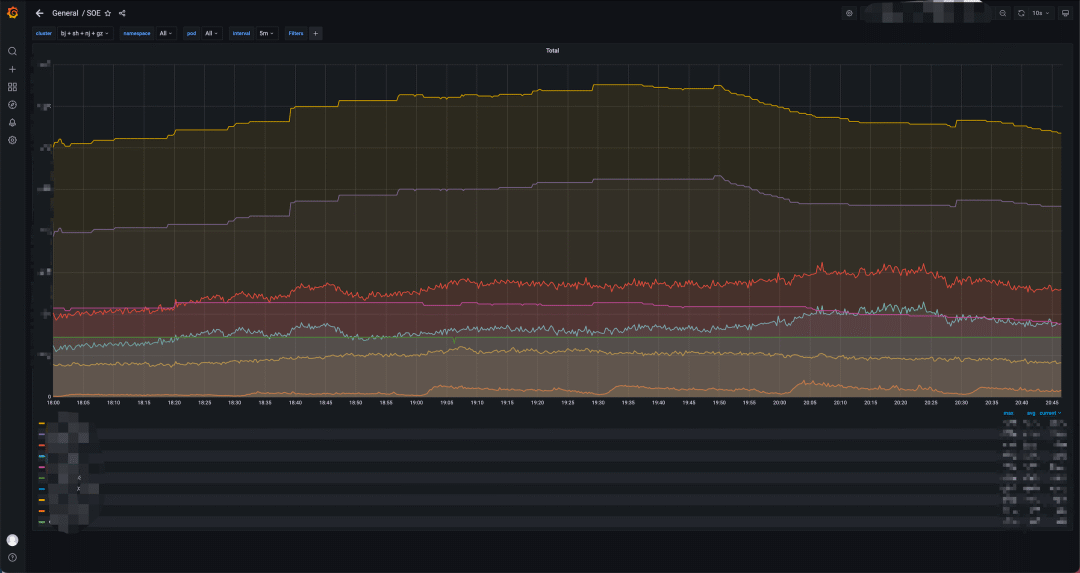
降本增效
服务扩容到流量接入耗时优化至分钟级,自研 scheduler 服务结合 Serverless 容器服务弹性扩容能力进行削峰填谷,降低超30%系统成本,节约2个运维人力。
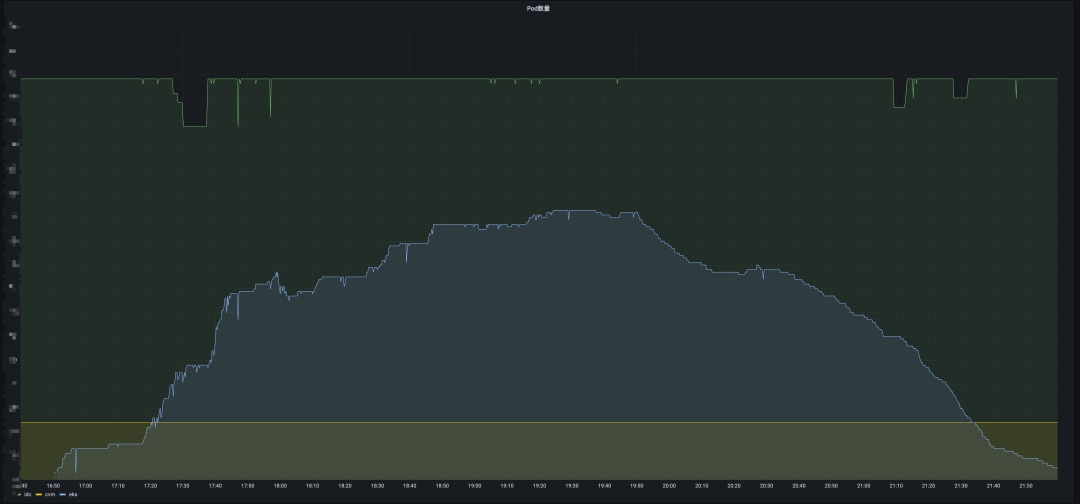
自研 scheduler 服务进行资源流转,早高峰期将闲置的英文节点资源转换为中文节点资源,减少北京地域近90%早高峰扩容需求。
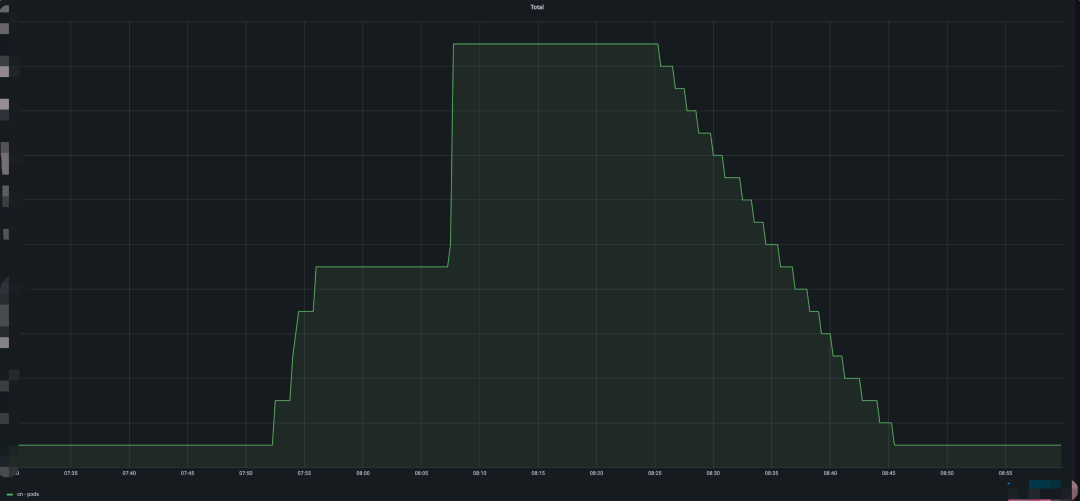
资源流转-优化前
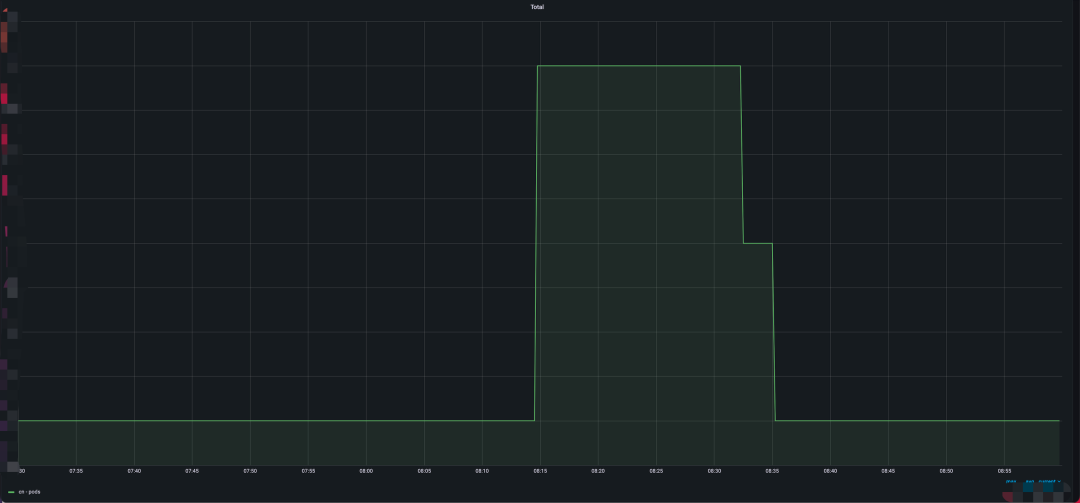
资源流转-优化后
(上图是优化前效果,早高峰需要扩容大量中文节点,下图是优化后效果,早高峰仅扩容少量资源。)
服务质量提升
接入层异常节点剔除
接入层通过业务侧配置的 Readiness Probe 探测服务存活,当心跳失败时配合 ReadinessGate 机制将 CLB 中对应 RS 的流量路由权重置0,以此实现异常节点自动剔除,保障现网服务质量。
引擎层异常流量剔除
引擎层通过北极星心跳上报的形式探测服务存活,当心跳失败时北极星自动将对应 RS 状态置为异常,以此实现异常节点自动剔除,保障现网服务质量。

过程遇到的问题
大集群方案未能实现
期望
最初设想是由一个 TKE 集群纳管所有节点(IDC 节点、云上 CVM 节点、云上超级节点),以此来简化整体服务部署,提高集群间资源流转效率,进一步降低整体方案复杂度。
问题
当前集群暂不支持绑定多地域 CLB,也暂不支持加入多地域超级节点,导致无法实现服务就近接入和弹性多地资源。
妥协方案
当前单地域大集群的方案,各地域均部署一个集群。
CVM转发性能瓶颈
问题表现
高峰期出现 connection reset by peer 的报错,报错比例低于0.01%,经排查均来自某个 CLB IP。
问题成因
查看 CLB、Pod 的监控均正常,在 Pod 内部署抓包也没发现异常的握手请求,而且业务侧 LB 是内网四层 LB,当前流量应该远没有达到 LB 的性能瓶颈。
正在一筹莫展之际开始重头排查整条链路,发现业务虽然选择的是 LB 型 Service,且 Pod 部署在超级节点上,但是 LB RS 却是 CVM 节点,流量还是通过 NodePort 的形式进入集群,再由 K8s 内部网络转发至对应服务 Pod,接入层 Pod 能够借助超级节点的能力弹性扩缩容,但是 CVM 节点数量却是固定的,就成为了系统的性能瓶颈。
知道有这么条链路之后再登录 CVM 节点验证,发现确实是 CVM 节点的连接数被打满了,导致部分连接被拒绝。
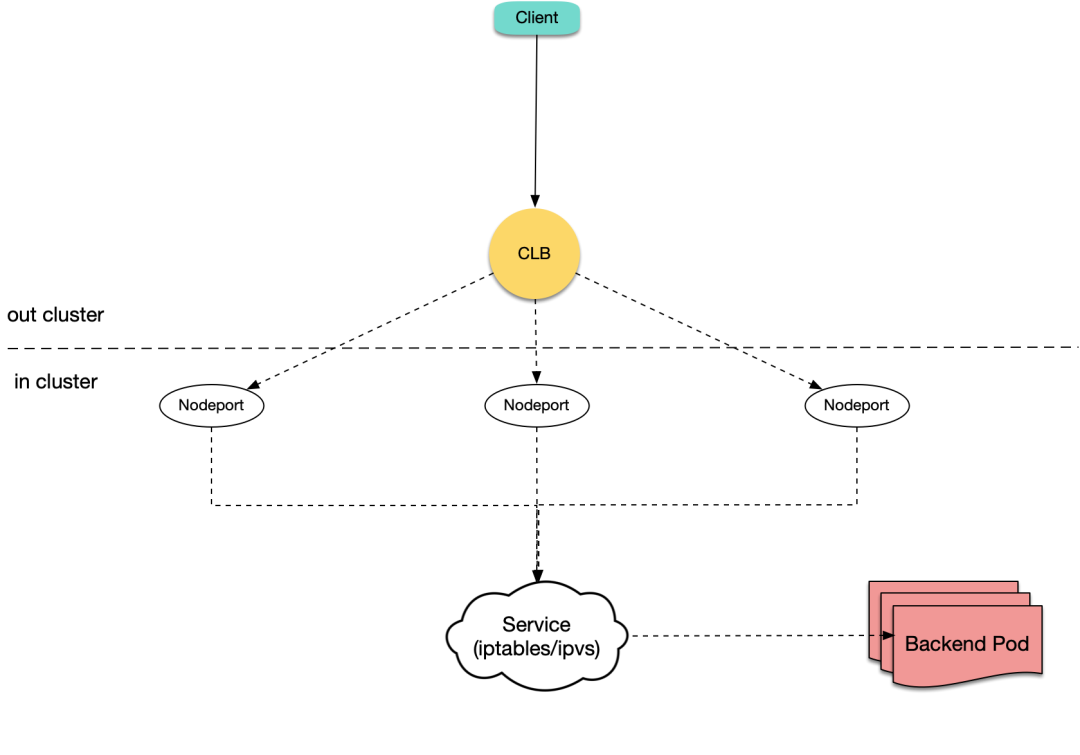
(图自容器服务官网文档)
解决方案
到这儿解决方案也非常清晰了,借助 TKE 提供的 CLB 直连 Serverless 容器服务 Pod 的能力去掉 NodePort 转发,流量均匀的打到 Serverless容器服务 Pod 上,Serverless 容器服务 Pod 又可以弹性扩缩容,以此就解决了性能瓶颈的问题。
(图自容器服务官网文档:https://cloud.tencent.com/document/product/457/48793)
总结
在不同的业务发展阶段需要选择合适的架构,没有完美的方案,需要随着技术迭代不断调整,固步自封只会让研发成为业务的短板。业务上云最终导向都应该是业务成功,服务于降本增效、提高服务质量等目标,上云后业务能够背靠腾讯云,借助各云产品强大的能力快速实现业务需求,降低技术使用门槛。
互动问答
本期问题:
接入层服务是通过 K8s Service 的形式暴露的,为什么引擎层服务要直接暴露 POD IP+端口,不能通过 K8s Service 的形式暴露?
参与方式:
点击下方留言回答问题,即有机会获得腾讯视频月卡(1月9日上午11点,由作者选出回答最佳的3位读者,送腾讯视频月卡一张。)








