




导语
Apache Pulsar 是一个多租户、高性能的服务间消息传输解决方案,支持多租户、低延时、读写分离、跨地域复制、快速扩容、灵活容错等特性。其原生支持了跨洲际级别的跨地域复制的解决方案,并结合其自身的 tenant 和 namespace 级别的抽象,可以灵活的支持不多种类,不同场景下的跨地域复制解决方案。
作者简介
范志会
腾讯数平高级运维工程师
目前腾讯公司内部业务在使用 Pulsar 的过程中,基于综合业务是否在线影响用户体检,是否产生营收影响,以及降本增效趋势下的成本考虑,会选择不同级别的容灾策略。下面从业务场景以及保障程度详解 Pulsar 以及客户端的容灾部署和策略配置。

Pulsar 多副本机制以及强一致性
在一致性方面,Pulsar 采用 Quorum 算法,通过 Write Quorum 和 Ack Quorum 来保证分布式消息队列的副本数和强一致写入的应答数(A>W/2)。在性能方面,Pulsar 采用 Pipeline 方式生产消息,通过顺序写和条带化写入降低磁盘 IO 压力,多种缓存减少网络请求加快消费效率。
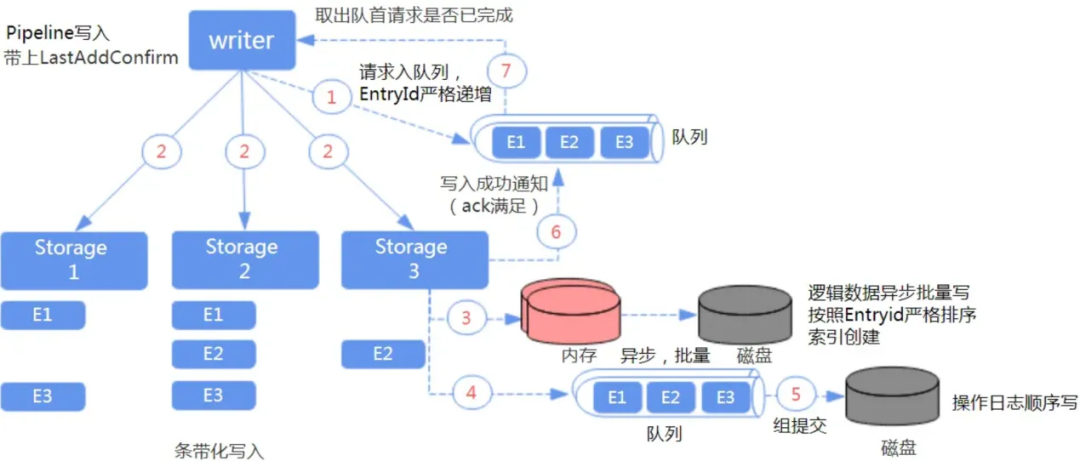
另一方面,在单个 Bookie 写入数据的时候可以配置强制刷盘写 Journal 即 Wal。
这个 Journals 文件里存储的相当于 BookKeeper 的事务 Log 或者说是写前 Log, 在任何针对 Ledger 的更新发生前,都会先将更新的描述信息持久化到 Journal 文件中。
Bookeeper 提供有单独的 Sync 线程根据当前 Journal 文件的大小来作 Journal 文件的 Rolling。
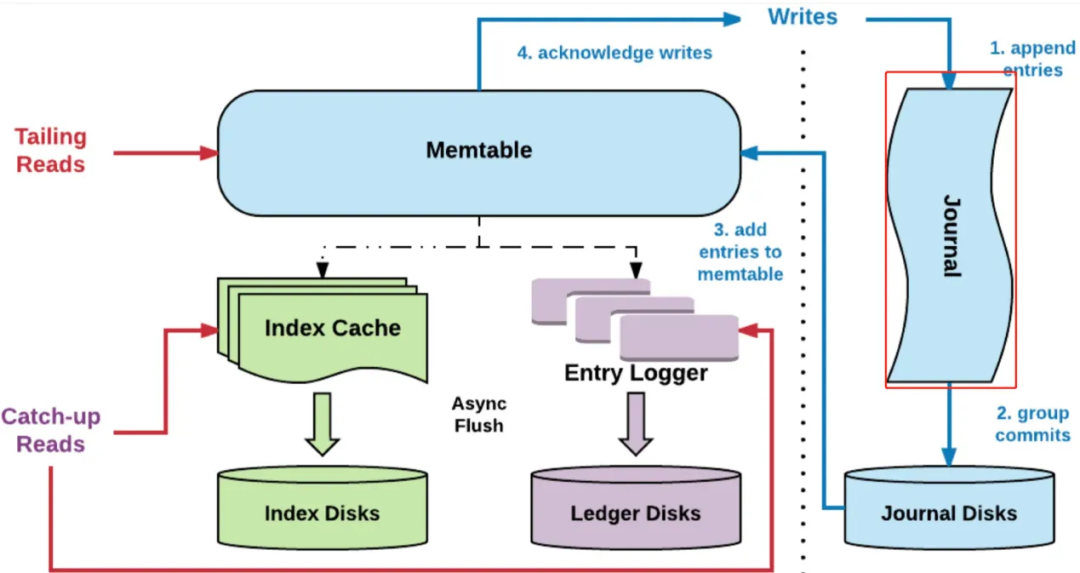
写入的 EntryLog 和 Index 都是先缓存在内存中,再根据一定的条件周期性的 Flush 到磁盘,这就造成了从内存到持久化到磁盘的时间间隔,如果在这间隔内 BookKeeper 进程崩溃,在重启后,我们需要根据 Journal 文件内容来恢复,这个 LastLogMark 就记录了从 Journal 中什么位置开始恢复。
运营实践:
所以基于以上两个特性,我们可以根据 Write Quorum 和 Ack Quorum,以及是否开启写 Journal 和是否同步异步写 Journal 在成本和容灾保障之间做一个合适的配置,目前线上在安全业务在数据量较大的情况下关闭了写 Journal,只有副本保障数据可靠性。
机架感知策略
机架感知是 Ensemble placement policy(EPP)的一种,是 Bookkeeper Client 用来选择 Ensemble 的算法,选择的依据主要是依赖网络拓扑属性。
示例2:
Region A和B 有四个 Bookie, bk1 , bk2 , bk3 and bk4 ,它们的网络位置是, Region-a/Rack-1/bk1 , /Region-a/Rack-1/bk2 , /Region-b/Rack-2/bk3 和 /Region-b/Rack-2/bk4 ,网络拓扑结构如下:
root
/ \
region-a region-b
| |
rack-1 rack-2
/ \ / \
bk1 bk2 bk3 bk4
RackawareEnsemblePlacementPolicy 会依赖 Rack 信息来从不同的 Rack 上选取 Bookie,可以保证 Write Quorum 至少包括两个 Rack,这个策略要求网络拓扑中至少包含两个Rack信息。
运营实践:
在支付和广告场景中部署会将不同网络分区的机器放在不同的 Rack 上面,例如深圳荔景、深圳深宇机器分配在Rack-1、Rack-2,然后配置副本的Write Quorum = Ack Quorum,这样当其中一个例如深圳荔景网络机房故障时,业务能继续从深圳深宇生产消费数据。
这里有两点值得注意:
- Zookeeper 也需要跨3个可用区部署,至少两个在深圳荔景、深圳深宇。
- 单个网络分区需短暂支撑两倍流量。
跨地域复制(GEO模式)
Apache Pulsar 内置了多集群跨地域复制的功能,GEO-Repliaaction 是指把分散在不同物理地域的集群通过一定的配置方式让其能在集群之间进行数据的相互复制。
当前拥有两个集群,分别部署在北京和上海,当用户在北京的集群中使用 Producer 发送数据时,首先会发送到北京机房的本地集群中(Topic1)与此同时会去创建一个 Replication Cursor,用于专门复制数据的一个游标,通过这个 Cursor 信息,你可以判断当前数据究竟复制到哪一个阶段。同时会去创建 Replication Producer,它会把数据从北京机房的 Topic1 中读取数据,然后将数据写到上海机房的 Topic1 中,上海机房的 Broker 收到 Producer 的请求之后,会写到本地相同的 Topic 中来(Topic1)。此时如果上海机房的用户开启 Consumer 去消费数据的话,会接收到由北京机房 Producer 生产的数据信息。
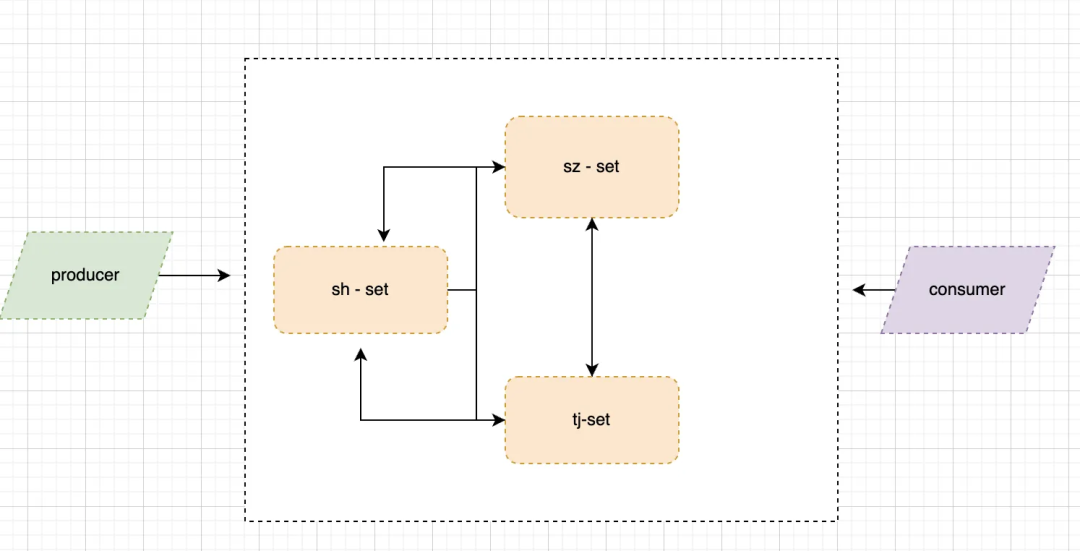
问题:
- Pulsar 只能保证单机房生产的消息顺序,在多机房的场景下没办法保证多个机房的消息全局有序。
- 由于 Cursor Snapshot 是定期进行的,在时间上精确度不会太高,多少有些偏差。
运营实践:
在广告多份场景业务部署了深圳、上海、天津三地集群,配置互相复制,业务一般从深圳写入,上海、天津业务端本地消费,部分场景加工完写回本地集群,很好的解决了多份消费的时延问题。
MQ运营过程中发现一个非常棘手的问题:如果一个业务滞后非常多,哪怕 Pulsar 是读写分离的,但是由于线程、内存等是共享的,大量的滞后读还是要导致写入时延变高,在非 Sdd 盘变现更为明显。这时候就可以用 GEO 模拟出多份数据,做到业务的隔离,让那些不关心滞后的业务放在 GEO 的一个集群,做到数据隔离。
业务双写,双消费+跨地域复制(geo模式)
在上面部分介绍了跨地域复制原理,但是在实际使用中业务有更高级别的容灾要求,由于跨地域给地的写入端还是只有一个,如果在写入过程中 Pulsar 集群故障还是会导致业务写入失败,影响在线业务展示甚至影响公司营收,所以业务会采用双写和双消费,每地部署两个集群。
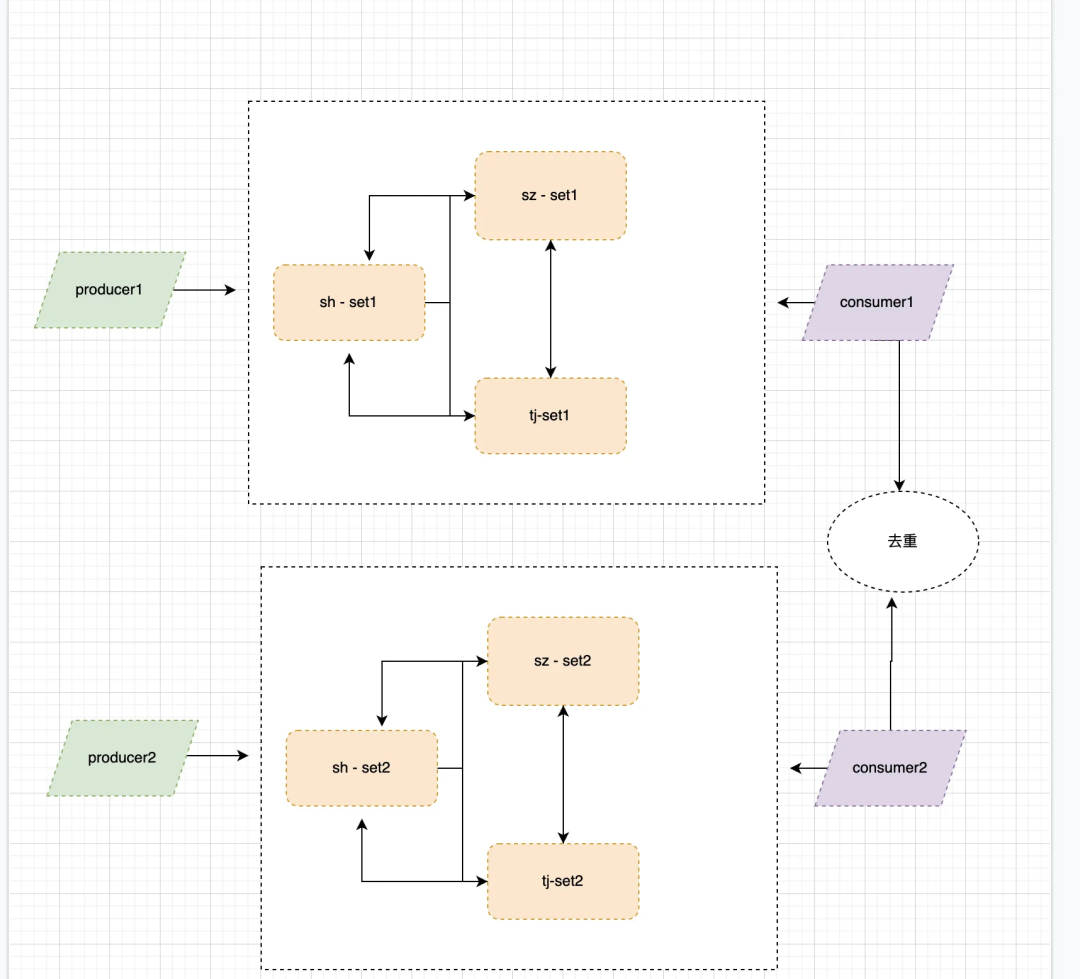
运营实践:
在广告业务中,部署了两套三地 GEO 集群,在运管过程中,一套由于机器故障,或者业务滞后导致使用不当,完成不会影响业务的使用,这个过程业务写入虽然可以失败,但是消费端却是需要去重。
计费场景的版本及部署
计费场景为什么需要单独讨论呢,因为同广告场景相比,广告计费链路业务场景的计费特性强依赖消息队列,不能跨城实时双写,避免曝光请求重复计费。而且计费业务每条消息都需要生产消费溯源,在对账对不齐时,需要找到在那个过程中的数据异常(没消费,数据丢失)情况,所以在计费版本 Pulsar 前面加入无状态的生产消费代理 Proxy,各地会部署两套以上集群,在 Proxy 前面加上公司的L5,如果某个 Pulsar 集群故障那将L5中的节点关闭。
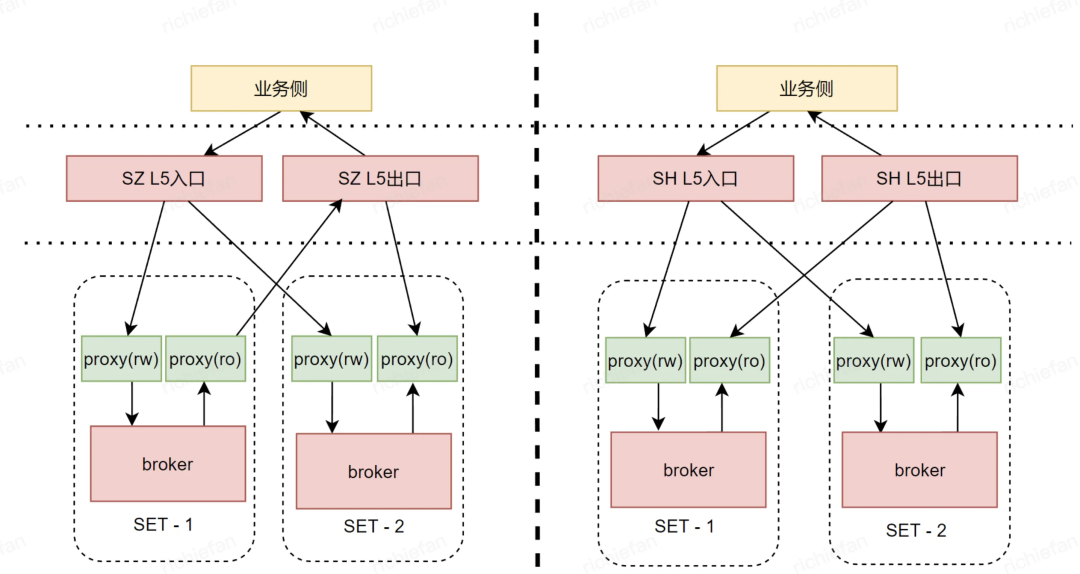
运营实践:
目前计费业务实际中如上图部署,当集群故障时,将L5中集群节点屏蔽,未消费的数据待集群恢复时补录数据,同时有 Tools 工具将数据备份到本地。
未来规划
从上面 业务双写,双消费+跨地域复制(GEO模式) 部分我们可以看到,目前通过业务双写双消费解决故障的过程中,集群使用会带来两个问题:
- 业务需要保障事务,下游需要去重;
- 双写双消费业务客户端成本加倍。
平台侧优化:
能不能所有容灾都让 Pulsar 承担,业务只是使用方完全不需要理会容灾等,这是未来平台侧一个巨大的挑战。
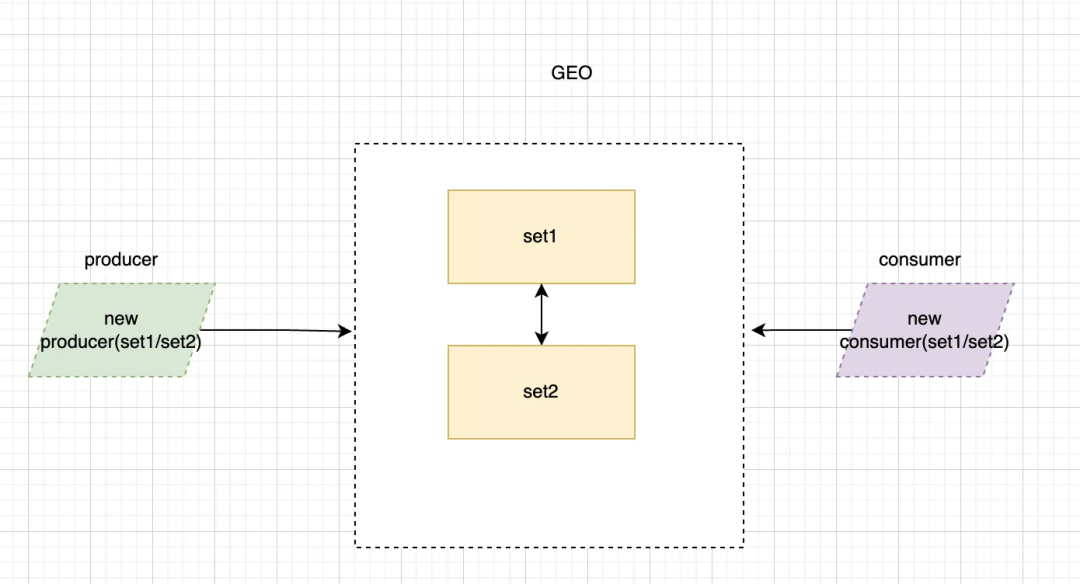
目前的一个比较清晰的方案大致是服务端侧通过 GEO 将数据和消费 Cursor 在两个集群同步,同时 SDK 需要支持多个 Pulsar 集群地址的切换,目前在 2.10版本已经支持生产端 SDK 多集群配置,但是消费端还不支持,而且 GEO 的数据同步和消费位点 Cursor 同步的失效性也有待加强,这些将都在新版本中实现。
往期
推荐
《微服务架构下路由、多活、灰度、限流的探索与挑战》
《TSF微服务治理实战系列(四)——服务安全》
《高并发场景下如何保证系统稳定性》
《微服务上云快速入门指引》
《Apache Pulsar 在微信大流量实时推荐场景下的实践》
《好未来基于北极星的注册中心最佳实践》
《百万级 Topic,Apache Pulsar 在腾讯云的稳定性优化实践》
《预告|ArchSummit 全球架构师峰会杭州站即将盛大开幕》
《千亿级、大规模:腾讯超大 Apache Pulsar 集群性能调优实践》
《云原生时代的Java应用优化实践》
《SpringBoot应用优雅接入北极星PolarisMesh》

扫描下方二维码关注本公众号,
了解更多微服务、消息队列的相关信息!
解锁超多鹅厂周边!

戳原文,查看更多消息队列 Pulsar
的信息!

点个在看你最好看





