


作者:张哲源 声网 Agora 视频算法工程师
最近看到了一句话“想讲清一件事情,拍个短视频就够了;如果不够,就来一场直播”。
视频成了最主流的“表达方式”。但这背后,离不开一项技术。可以说,如果没有它,我们甚至无法通过互联网看视频。这项技术就是视频编解码技术。
为什么我们需要视频编码呢?
因为我们需要通过编码压缩视频,节省对传输带宽和储存空间的需求。
我们都知道,视频是由图像组成的。我们就先拿一张图片来说吧。
如果想要看到一张1920*1080分辨率的高清图片,我们一共需要1920*1080*8*3个bit。1920*1080 是像素的数量,3 代表的是RGB三个值,而 8bit 则是每个像素值的大小。这样一张图片,算下来总共 47Mb。
如果我们要观看 1920*1080 的视频呢?
我们现在的视频一般都是 30fps (帧每秒)。那我们粗略的计算,一秒钟就需要30帧刚才47Mb大小的图片,这样算下来,我们大约需要1.4Gb的带宽。
不难发现,视频信号所包含的信息量巨大,显然我们现在的网络情况是远远不能满足的,所以必须进行视频压缩编码,以便于在网络上进行传送时,节省传送带宽和储存空间。
视频编码是把什么变成了什么?
视频从一端传输到另一端共分7个步骤:

接下来我们重点讨论其中的编码环节。
想了解编码的原理,就需要先了解一下编码这个过程的输入和输出都是什么。
我先说视频编码的输出,这里能够看到经过视频编码后有两个输出方向。(如下图1)
一个输出方向是应用于实时传输,比如看虎牙、斗鱼等平台的直播,或进行视频通话,或看在线视频爱奇艺、B站等。
第二个输出方向是应用于本地视频文件。由于编码器分为视频编码器和音频编码器,所以视频编码器输出 H .264格式的文件后,需要与音频编码器的输出进行封装,然后才能生成我们常见的 MP4 等格式文件。

再来讲上图中视频编码的输入。
我们都知道,视频是由图像组成的。而图像则是由一个个像素组成的。而一个像素,可以通过 R/G/B 三种颜色的值来表达,这也是我们最常见的。但是,还有一种表达方式就是 YUV 。其中,Y 是明亮度,用来表示像素的灰度值,U、V 分别是影像色彩与饱和度,用来表示像素的颜色。
在视频编码的过程中,视频不直接使用RGB而是用YUV作为输入,是因为YUV作为输入可以极大地去除冗余信息,你可以理解为YUV作为输入进行编码,才能极大地节省带宽。RGB与YUV的转换公式可以参考这部分内容(如下图2),这里我们就不展开讲了。对算法感兴趣或有需要的小伙伴,可以私下慢慢研究。

走进视频编码器内部,它是怎么工作的?
(高能预警:这部分会涉及算法原理,如果你只想了解其原理,可直接跳到结尾看总结)
前面我们了解了视频编码的输入和输出,也计算过,如果传输没有压缩的视频数据,一秒钟需要1.4Gb的带宽,这是一个非常恐怖的数据量,不可能应用于现在的网络。
但是,因为有视频编码的存在,巨幅减少了视频流所需要的比特,让咱们现有的网络可以无压力地播放,甚至在某些低码率的情况下,我们依然可以看到高清的视频。
那现在就让我们来看看视频编码内部过程的怎样的。
视频编码实现的标准有很多,现在最主流的还是H.264,所以我今天的分享就以H.264标准的各个模块,作为视频编码的内容。将视频编码分为五个模块(如下图),帧类型分析、帧内/帧间预测、变换+量化、滤波、熵编码。接下来我逐个展开讲一下。
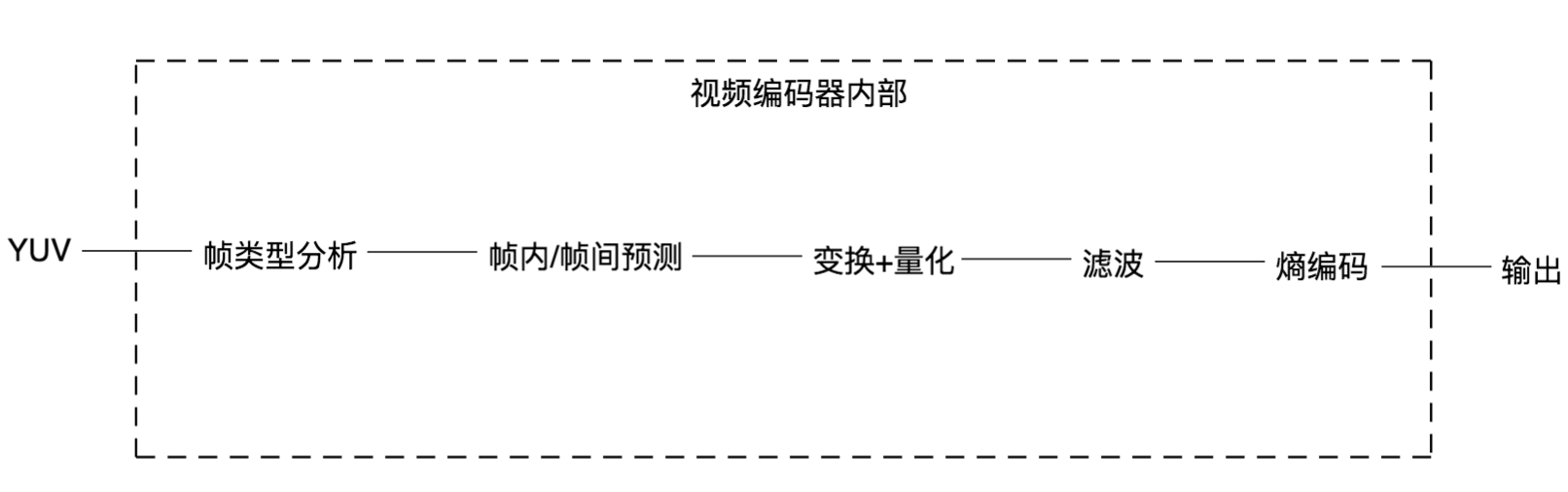
第一步:帧类型分析
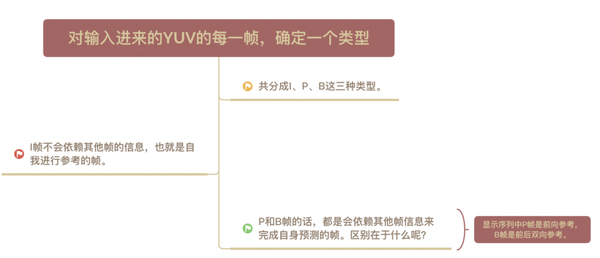
我们要对输入进来的YUV的每一帧确定一个类型,共分成I、P、B这三种类型。I是内部编码帧,P是前向预测帧,B是双向内插帧。I帧不会依赖其他帧的信息,也就是自我进行参考的帧。P和B帧的话,都是会依赖其他帧信息来完成自身预测的帧,区别在于显示序列中P帧是前向参考,B帧是前后双向参考。
你可以把 I 帧理解为电影中的一个完整画面,里面包含了所有的图像信息,而P帧和B帧记录的是相对于I帧的变化。
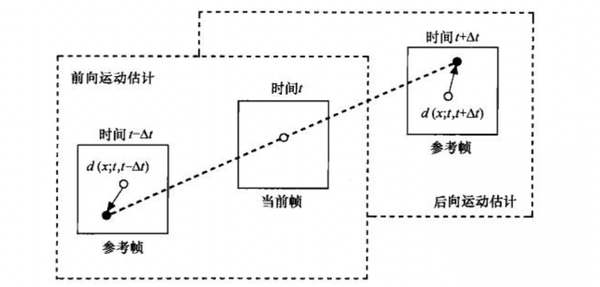
可以想象现在有一段视频,一个人从画面左边走到右边,刚打开这个视频的时候,显示的第一帧图像肯定是要自我重建的,因为没有图像可以参考,这样的帧就是I帧。后面的再显示第二张图像发现除了画面中除了人运动的一点点位置发生了变化,剩下静止不动的地方都和前一帧一样。这样的话,就可以把前一帧静止的数据直接复制过来,当前帧只需要把和前一帧的不同点(也就是运动位移矢量)保存下来就行,这样的帧就是P/B帧,B帧因为还有后向参考,也就是说,它比P帧参考搜索的范围更大,所以B帧的压缩率相对更高。这时候镜头突然一转,给了这个人的脸一张特写。那么这时候就会需要重建一个新的画面,就是一个新的 I 帧。(如下图4)

理想情况下,一个视频流,从一个I帧开始后面轻微运动都是 P/B,直到遇到场景切换就再插一个I,如此往复。一般来说,P/B 参考范围不会越过I帧。但也有特例,我们可以强行指定 P/B 参考不允许越过 I 帧,这样的I帧我们叫它 IDR 帧,每个 IDR 帧(Instantaneous Decoding Refresh)的间隔我们称作一个 GOP(Group of Pictures)。
而实际上,在编码器中实现帧类型分析,通常会先将 YUV 一帧的数据做降采样处理,然后用降采样后的数据先进行帧内/帧间预测,估算出最能节省码流的方式,来确定当前帧的帧类型。
除此之外,也会有专门判断场景切换阈值的算法,或者固定GOP大小下每个GOP的开始强行指定IDR、每个GOP结尾强行指定P帧的操作。
第二步:帧内/帧间预测
大量统计表明,源 YUV 中两个相邻像素值相等、相似或者缓变概率极大,发生突变的几率是极小。(简单解释下,缓变图像:细量化,粗采样;突变图像:粗量化,细采样,处理细节丰富的图像)
通常,编码器会通过算法将图像划分为一块一块的,然后逐块进行后续的压缩处理。
假设当前的块不在图像边缘,我们可以用上方相邻块边界邻近值作为基础值,也就是上面一行中的每一个值,都垂直向下做拷贝,构建出和源 YUV 块一样大小的预测块,这种构建预测块的方式,我们叫做垂直预测模式,属于帧内预测模式的一种。与它相似的,还有水平预测模式、均值预测模式(也就是4x4的均值填充整个 4x4)等。
紧接着,用源YUV的数据和预测YUV的数据做差值,得到残差块,这样我们在码流中,就直接传输残差的数据和当前4x4块的预测模式的标志位就行,这极大地节省了码流。
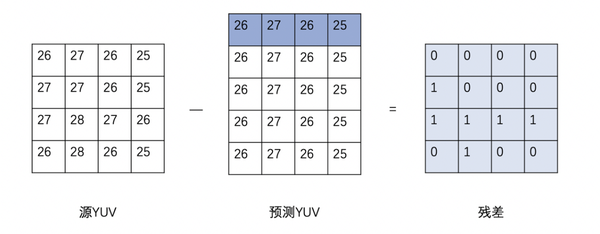
如果是帧间预测的话,编码器会以当前块空域相邻的位置,在时域参考帧上的同为块,作为起始点进行规则搜索,直到搜索完找到能够节省码流最大的块作为帧间预测块,当前块到预测块的位移称为运动矢量,这样我们在码流中传输运动矢量、帧间预测模式标志位、残差就可以。
H.264 中我们把 16x16 大小的块称作宏块,宏块也是 H.264 中最大的块,做帧内/帧间预测的时候可以分成8x8、4*4 这样的子块,都是要把它们最能节省码流的预测模式都算出来,然后比较出最优秀的划分模式进行传输。
第三步:变换+量化
大量统计表明,把经过预测后得到的残差经过DCT空频变换,直流和低频(相对平坦,图像或块中大部分占比)能量集中在左上,高频(细节,图像或块中少部分占比)能量集中在右下,DCT本身虽然没有压缩作用,却为以后压缩时的取舍,奠定了必不可少的基础。
变换后直流分量DC都集中在左上角,是整块像素的求和的均值。由于人眼对高频信号不敏感,我们可以定义这样一个变量QP=5,将变换块中所有的值都除以QP,这样做进一步节省传输码流位宽,同时主要去掉了高频分量的值,在解码端只需要将变换块中所有的值在乘QP就可以基本还原低频分量。
我们将QP运算的过程称为量化,可见量化值越大,丢掉的高频信息就越多,再加上编码器中都是用整形变量代表像素值,所以量化值最大还原的低频信息也会越不准确,即造成的失真就越大,块效应也会越大,视频编码的质量损失主要来源于此。

第四步:滤波
我们可以把滤波理解为一个在量化值波动特别大的时候的一个提升主观质量的操作。如果量化值波动特别大,有可能造成本不应该是真实边界的区域内有很明显的块效应。我们暂称为块效应边界。
真实边缘就比如说我们人脸和身后的背景,中间的这一条线。那假边界就是图中人脸区域的一个一个小块当中的这样的一个线。
为了优化这种情况我们需要对块效应边界两边的值进行补偿操作,让块效应边界两边的值差异不要过大,从而降低块效应,提升质量。
具体的操作,我们分三步。我会细致给大家梳理下。这部分很重要,有需要或者感兴趣的同学可以参考:
1、初步估算块效应边界强度。
我们首先需要粗略的估计块效应边界像素的差距,我们称这个像素差距为边界强度。一共有0到4这五种强度,其中0代表最弱的强度,是估算两边像素相差不大,不需要进行滤波。4代表最强的强度,也就是估算两边像素相差可能巨大。
初步估算块效应边界强度:
- 4:边界两边块是帧内预测且块边缘是所在宏块边缘
- 3:边界两边块是帧内预测且块边缘
- 2:边界两边块的残差变换系数包含非零系数
- 1:边界两边块的残差变换系数不包含非零系数,且两快的参考帧或运动向量不同
- 0:边界两边块的残差变换系数不包含非零系数,且两快的参考帧或运动向量相同
2、区分真假边界。
我们应该进行滤波操作的边界是块效应边界,这样的边界我们称为假边界,而真实的物体边界我们是不应该做滤波的。
标准H.264中设定了两个阈值,块与块之间的边界阈值和块内部边界的阈值,用这两个阈值对边界周围一共四个像素做三次条件判断,三个条件同时满足我们才认定他是虚假边界需要做滤波。我们可以看到在决定阈值的过程中还有一个滤波强度的偏移量,我们可以手动调节其大小来更精细的判定当前块到底是需要保存细节,还是存在块效应应该被优化。
a. 初步估算边界强度:
- 4:边界两边块是帧内预测且块边缘是所在宏块边缘
- 3:边界两边块是帧内预测且块边缘
- 2:边界两边块的残差变换系数包含非零系数
- 1:边界两边块的残差变换系数不包含非零系数,且两块的参考帧或运动向量不同
- 0:边界两边块的残差变换系数不包含非零系数,且两块的参考帧或运动向量相同
b. 区分真假边界(假设p0和q0直线的边界是判断边界,三个都满足就是虚假边界是需要滤波的):

- |p0 - q0| < 块与块之间的边界阈值 = Clip3( 0, 51, ( QPp+QPq+1) / 2+ 滤波强度偏移量)
- |p1 - p0| < 块内部边界的阈值 = Clip3( 0, 51, ( QPp+QPq+1) / 2+ 滤波强度偏移量)
- |q1 - q0| < 块内部边界的阈值 = Clip3( 0, 51, ( QPp+QPq+1) / 2+ 滤波强度偏移量)
增加滤波强度时,用正偏移量,可以去除由次优运动估计、编码模式选择不当引起的块效应,改善图像主观质量;减少滤波强度时,用负偏移量,可以保护图像细节不被滤波器的平滑作用模糊掉。
3、计算差值。
对边界两边的值进行补偿,边界强度1到3对应弱滤波器,首先将p0、q0两个像素点进行补偿,接着用内部边界的阈值判断是否需要调整p1和q1,边界强度4对应强滤波器,强滤波器对(p0、p1、p2、q0、q1、q2)一共6个像素点进行补偿。
计算:(强滤波器,弱滤波器):得到差值(限制查标准)
Δ = ( p2 + ((p0+q0+1)>>1) − (p1<<1)) >> 1
对边界两边的点对这个差值做对应的加或减
第五步:熵编码
我们在真实网络传输的过程中肯定都是二进制码,所以我们需要将当前的像素值进一步压缩成二进制流。在编码中一共有两种熵编码方式。
较为简单的Cavlc,一共有6步。举个例子,假设有一个4*4的数据块,我们对它进行Cavlc操作。先沿着划线部分,将它从一个二维数组变成一个一维数组,这种扫描方式,称为ZigZag(之字形)扫描。

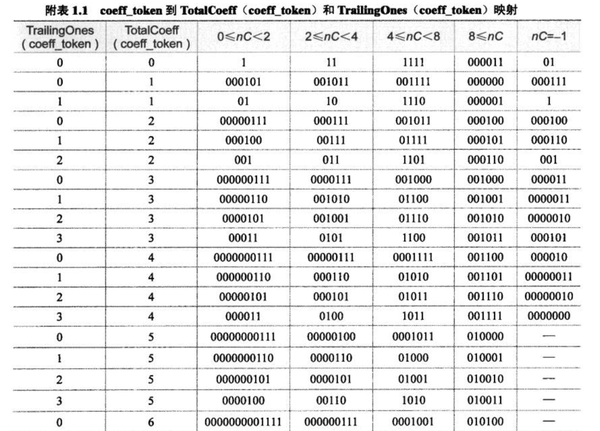
接着,计算出非零系数的数目(TotalCoeffs) = 5,拖尾系数的数目(TrailingOnes)= 3,然后在确定上下文相关性nc = 1(nc计算详细可以看毕厚杰书里P120表6.10),然后根据计算出的非零系数数目、拖尾系数数目、nc来查标准(BS ISO/IEC 14496-10:2003)中的Table 9-5。
查表(如下)得出编码头coeff_token = 0000 100 ,这里我们用Code = 0000 100来记录当前编码总信息。
在这些基础上,编码拖尾系数。这里我们需要先了解一下拖尾系数,拖尾系数,它指的是值为+1/-1的系数,最大数目为3。
如果超过3个,那么只有最后三个被视为拖尾系数。知道拖尾系数后,我们沿着逆序zig-zag进行编码,一共编码三个,每1bit编码一个拖尾系数符号,0代表+,1代表-,即三个拖尾系数的符号依次是+(0),-(1),-(1);加入编码总信息Code = 0000 1000 11。
剩下的三步,编码除了拖尾系数的非0系数、编码最后一个非0系数前0的个数、编码每个非零系数前零的个数,这三步统计和查表的方式与上面类似,每执行一步之后都会加入编码总信息Code,最后编码结束的总信息是Code = 0000 1000 1110 0101 1110 1101。有兴趣可以去标准中详细看,自己来计算一下。
Cavlc上下文自适应变长编码
1. 正序zig-zag排列,算非0系数、拖尾系数(最大后三个+1/-1的数)、算上下文相关性nc(左边块非零系数+上边块非零系数)/2 再四舍五入
2. 根据这三个来查标准得出编码头coeff_token(nc小选较短的码)
3. Zig-zag逆序编码,每1bit编码一个拖尾系数符号0是+ 1是-
4. 编码除了拖尾系数的非0系数
5. 编码最后一个非0系数前0的个数
6. 编码每个非零系数前零的个数
说完Cavlc,还有一种压缩率更高但运算更复杂的Cabac,一共分3步。
就像前面Cavlc例子的zigzag扫描后的结果,是一块的像素值残差,我们首先
第一步要二值化,就是说要将每一个像素值映射成二进制,变成一个二进制流,我们能看到有几种方式来做这个映射,复杂度高的哈夫曼编码、定长编码、一元码编码、指数哥伦布编码、截断莱斯编码。(具体原理如下)

第二步上下文建模得到概率模型,也就是二进制流每进来一位0或1,都会通过查标准和公式更新0和1的概率,谁出现的次数多概率就大。当还没有码流被编码会先通过QP相关公式计算出概率模型初始值。 (具体计算过程如下)

第三步是二进制算术编码,采用得到的概率模型,比如一开始0和1初始化的概率各自占比1/2,0是从0到0.5的区间,1是从0.5到1的区间,现在进来一位1,那么编码区间就选择0.5到1,选择完这个区间之后要更新概率模型,也就是要增大1的概率,有可能变成1占比4/5,0占比1/5,更新概率模型后。
再进来一个0,上面1的时候编码区间已经变成0.5到1,我们就从这个区间分出0和1的占比,比如0是从0.5到0.6,1是0.6-1,那这个时候编码区间就选择0.5-0.6,如此往复,知道码流编码结束,在最后的编码区间内任意取一个值就可以代表当前码流。

到这里,走完一整个编码流程,生成的数据就是压缩后的结果,我们也可将它送到适应我们的网络中去。
我们来总结一下

先是我们计算过没有经过编码压缩的视频需要极大的带宽,所以我们必须进行编码。后来又说道编码的各个过程,输入的原始YUV进来,采用帧类型分析得到IDR、I、P、B类型,然后采用帧内/帧间预测+块划分得到残差,再采用变换+量化进行进一步压缩,接着采用滤波去除方块效应,然后采用熵编码将像素值转换为二进制流进一步压缩,输出压缩后可传输的码流。
最后和音频编码出来的码流一起封装成我们常见的mp4等格式。
编码的未来
视频编码的基本原理就是这样了。经过视频编码处理,我们才可以通过网络看到高清的视频。现在,各编解码标准组织正通过机器学习来进一步优化视频编解码技术,提升编码效率,降低码率。
例如,我们声网Agora SDK 就已经通过融合多种编码技术,包括 移动端超分辨率、PVC、PRIM 等,可以有效降低码率,从而降低视频传输所需带宽。
可能有些朋友还不了解 PVC(感知编码),我们简单来讲一下。传统视频编码的目标是尽量逼近原始图像质量,通常会采用 PSNR 指标来衡量图像画质,但 PSNR 是一种评价图像的客观标准,并不能很好地反映出人眼系统的体验。所以我们移动设备端上引入了 PVC,它利用人眼视觉系统特性,结合人眼对时间频率、空间频率、边缘信息等感知能力,过滤人眼不敏感的信息,而过滤掉了这些不敏感信息,可以为我们节省码率,但又不会影响画质。
我们可以根据下面两张图看出 PVC 处理效果。左边是原图,右边是处理后的。原图经过PVC处理前后人眼主观感受并无明显差别,但右图PSNR只有不到37dB*,可以明显降低处理后的图像在编码时的所需码率。(PSNR 越大,图像质量越高)。

同时,我们还应用了 RPIM。PRIM 可在软件编码器上开启,编码期间为高参考帧权重多分配码率,减少低参考帧权重码率,可实现在低复杂度场景下码率节省能力的总体提升。
而以上这些能力都已集成到声网 Agora SDK中,开发者无需自己再趟一遍算法的“坑”,可以通过调用几个 API,直接将其应用到自己的互动直播、视频互动场景应用中。而且声网 Agora SDK 每月会为开发者提供 10000 分钟免费额度。

