


注:本篇内容来自”腾讯技术工程官方号“,公众号ID:tegwzx
前言
TDW 是腾讯内部最大的离线处理平台,也是国内最大的 HADOOP 集群之一。在运营这么大集群的时候,运营面临各种各样的难题,在解决这些难题的过程中,团队提炼出来的一个运营理念,用两句话去描述。
用建模的思路去解决运营的难题
运营的问题怎么解决?你必须用一些数据建模的办法,把这个难题解析清楚,然后我们再去考虑运营平台建设。
运营平台支撑模型运作
不是为了建设运营平台而建设,而是它必须有一定的运营理念。下文写到这样的运营理念是怎么贯穿在迁移平台的建设里面的。
本文主题主要包含以下几个方面:
1、介绍一下腾讯大规模集群 TDW,以及为什么做迁移。
2、迁移模型是怎么样的。
3、迁移平台是怎么做的。
跨城迁移平台的迁移策略
刚才我们说的是模型,有一套模型指导我们做迁移这个事情,有了模型之后,需要一个平台来支撑这个模型。
关系从无到有,对最基础的关系进行聚合,形成关系链。找关系链的核心结点,把关系链拆分,将小的关系链融合成更大的关系链。迁移平台有一个模块专门负责关系链的这类操作。
另外一个模块是关系链的迁移模块,就是怎么把已经划分好的关系链从一个城市挪到另外一个城市,它涉及数据的迁移,任务的切换,普通表升级双写表,依赖任务和同步任务的处理。
此外还有一个模块是平台保障,数据校验,任务校验和跨城流量的监控。
关系链迁移模块
迁移模型解决了一件事情,就是从无到有,构造我们的关系链,然后把关系链从大拆小,拆到合适迁移一个个的规模适中的关系链。
关系链迁移是解决另外一个问题。一个关系链里包含任务和数据,在迁移过程中,它们的状态会变化。比如说数据还在写,TDW 的数据每天在不断变化。任务也可能还正在跑,没有结束。
也就是说,关系链并不是静止的状态,它是动态变化的。关系链迁移是要保障在动态变化的环境下,数据和任务的迁移是准确的。
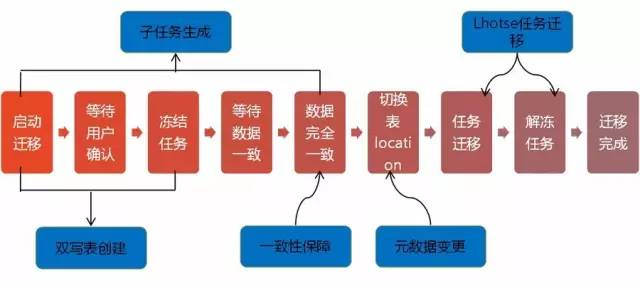
(关系链迁移模块的状态变迁)
关系链迁移时,首先会看关系链里有什么双写表,先处理双写表,之后处理其他数据的迁移。数据迁移时,先按表分区展开,按分区迁移,这可以加快迁移的速度。
迁移开始前会通知用户,用户可以不用管,但是他需要被通知到。如果遇到什么异常,用户可以分析是不是因为这个变化导致。
通知完用户,会展开所有表的分区,对展开之后的分区做迁移操作,也就是 distcp。
当 distcp 到一定进度的时候,会做冻结任务的操作。关系链里面的任务可能有状态变化,冻结操作可以将其转变成不可变的状态。
把数据的写入任务冻结,写入任务可以通过关系链找到,如果没有关系链这种冻结操作也无法实施。迁移的过程不允许任务进行写入操作,因为写入操作会导致数据很难保证一致性。
把任务冻结之后进入等待数据一致的状态,在这个状态里还会不断对比两个城市之间的数据差异。
比如新增数据,数据不一样了就会再做一次数据同步的工作,直到数据完全一致,进入一致状态的时候,数据迁移的工作就完成了。之后进行任务迁移,任务迁移后就可以解冻任务,完成整个关系链的迁移。
这里最重要的是有一个冻结任务的逻辑,保证我们在数据迁移的时候,有一个时间段不会有任务在修改数据。冻结任务的时间越短越好,这就要求数据迁移的速度越快越好。
数据仓库里的表占用空间有大有小,对于大表,直接进行表级 distcp 的时候,通常起的 map 数很少,这时候并发上不来,速度也上不来。所以对于大表,需要采用分区级的 distcp。对于小表则相反,分区级的 distcp 往往是浪费。
另外关系链的迁移需要支持并发,关系链的在迁移过程消耗的资源不一样,有时候是网络流量大有时候网络流量小。关系链并发迁移,可以规避这种情况,实现接近满负载流量的迁移。
平台保障模块
平台保障模块,包括两大块的保障:一个是基础保障,还有是监控保障。
1、基础保障
做了两件事情,一个是数据校验,迁移完成两边数据要做校验,另外一件事情是任务的抽样重跑。我们引入一个思路,在关系链里面抽出一条垂直的路径,从根节点一路下来重做任务。
一个关系链可能有几十个结点,抽样后只有四五个结点。对抽样出来的结点进行重跑,重跑后做数据比对,看看是不是一致的。这样可以保证数据是准确的,任务也是准确的。
2、监控保障
做了几件事情,一个是数据量的监控,迁移完成后,监控数据量的波动,看看数据量跟之前的是不是有明显波动。另外会监控所有迁移过的任务,看看它们在新的城市是否运行正常。
最后,是流量的异常监控。数据和任务都验证成功,迁移也就是成功的了。数据已经从一个城市整体迁移到另外一个城市,任务也一起切换过来。最后要考虑的是,会不会有异常情况导致我们的跨城流量出现异常上涨。
我们有一个流量监控的机制,来解决一些例外情况导致的流量异常。通过加强流量的异常监控,并实现任务的自动切换。每五分钟采集正在运行的所有任务,以及它们访问的数据。
如果发现有任务在城市A的计算集群里面跑,但是它访问了城市B的数据,这种异常的情况会被监控起来。当数据穿越流量过高时,会自动把任务杀掉,同时自动进行任务切换。
跨城迁移平台的迁移策略
我们已经介绍了迁移模型和迁移平台,我们有一套模型去解决我们的运营面临跨城迁移的难点,然后我们也有一个平台支撑这个关系链迁移的逻辑。接下来我要再讲一下我们的迁移策略。
迁移集群独立部署
迁移集群需要独立部署,迁移最大的工作量是数据迁移,有很多数据要从一个地方同步到另外一个地方,数据迁移的方式就是做 distcp,distcp 是一个MR任务,MR 任务需要消耗计算资源。迁移集群最好独立开来,这样就不会影响正常的调度任务。
迁移集群最大的特点是网络流量会跑得很高,因为它只做一件事情,从源集群拉取数据,写到目标集群,观察迁移集群的网络流量的时候就会发现,它跑起来的时候,出入流量是一样的,它是网络流量高消耗的集群。
它有一个特点,它是低CPU消耗的集群。把它单独做为迁移集群,可以做到两个特性化配置,一个就是采用高网络配置的机型,比如使用万兆网卡的机型。另一个是采用低内存的任务配置以及对迁移集群的计算节点采用高并发的配置。
这样可以在尽量减少迁移集群的设备需求量的同时,大大提升迁移速度。我们采用40台机器的迁移集群就能支撑1P的迁移流量。
迁移的流量控制

迁移的流量控制,这张图很有意思的地方是,当我们做数据迁移的时候,源集群(城市A HDFS集群),迁移计算集群,目标集群(城市B HDFS集群),这三个集群的流量有很有意思的关系。
源集群是一个大集群,通常有上千台机器;迁移计算集群则少得多,可能只有几十台。迁移计算集群在网络打满的情况下,对源集群的网络消耗可以计算出来,对目标集群的网络消耗也是可以计算出来的。
举个例子,如果迁移计算集群有40台的规模,这40台设备的网络用满的时候,源集群如果只有400台,网络也会被用满,网络用满的时候会对任务一定会有影响。
还有一个比较有意思的事情,目标集群的流量要比迁移集群流量大,原因是写数据时 Hadoop 有多份拷贝,会导致目标集群的流量翻倍增加。我们在使用迁移集群的时候,可以对迁移集群进行资源池管理,限定它的资源池大小,也就是限定迁移最大的并发数,从而对迁移流量进行控制。
集群的同步任务
再说说同步任务,同步任务对流量影响会比较小,因为同步任务方向和迁移方向是反方向的,迁移方向是城市A到城市B,同步任务是逆向回来的,所以流量很小。
我们尽量降低同步任务对业务的影响,建议使用独立的同步任务资源池,这个资源池可以更大一些,让同步任务快速完成,不影响其他任务。
HDFS集群的缩容扩容策略
最后,HDFS 集群的缩容扩容策略,在集群缩容的时候,要优先考虑集群整体下线,在缩容前要先进行数据清理和小文件合并。
另外,迁移的时候设备是一批批搬迁的,比如每一轮搬迁200台机器。这200台扩容到目标集群的时候,新扩容的节点在一段时间内不参与计算。因为 Hadoop 的 balance 机制会导致新扩容机器的网络流量被打满,直接影响计算任务的速度。





