


小张
现在
OK👌,排期1天搞定。
小张交付了,鉴于小张的工作口碑,我相信他的结果,但后来发现他给的结果和数据工程师小王做的报表数据对不上😭,只能说小张、小王的工作也不完美。
小张、小王的优势是,在和我的沟通过程中,充分共识了数据分析的上下文,我知道他们知道我想知道的。
小张、小王的不足是,没有统一的上下文,导致了同样的数据指标,结果对不上。
我需要的Data Agent:
- 不是只给我一个数,也不是给我展示一段让我头皮发麻的SQL,我还得找数据工程师小张看看SQL对不对
- 知之为知之,不知为不知,是知也。
- 无论何时、无论是谁,都能得到一致的结果
- 针对取数结果做一些同环比、增长率的分析,再加点个人见解,虽然很不错,但那活儿现在元宝、豆包都能干,我还要能真正帮我发现我负责的这个业务,哪些指标、维度我分析的时候可能没有考虑到,也能给我也查出来。
怎么做?
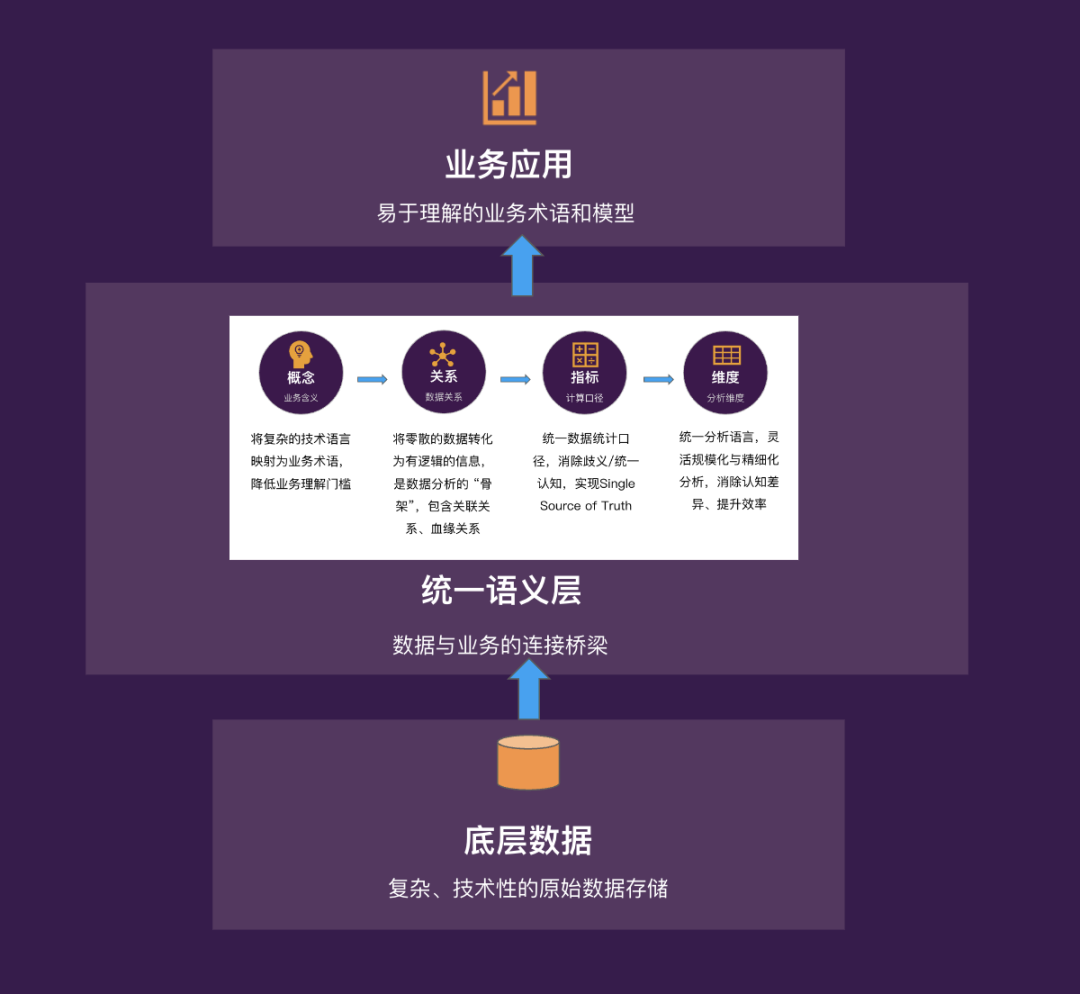
一个简单而又朴素的想法,那就是提供一个平台让数据人定义一致的上下文吧!在WeData,我们叫Unity Semantics,目标是帮助建立一个人与机器都能理解的统一语义层。
2
Data Agent的
语义上下文是什么样的?
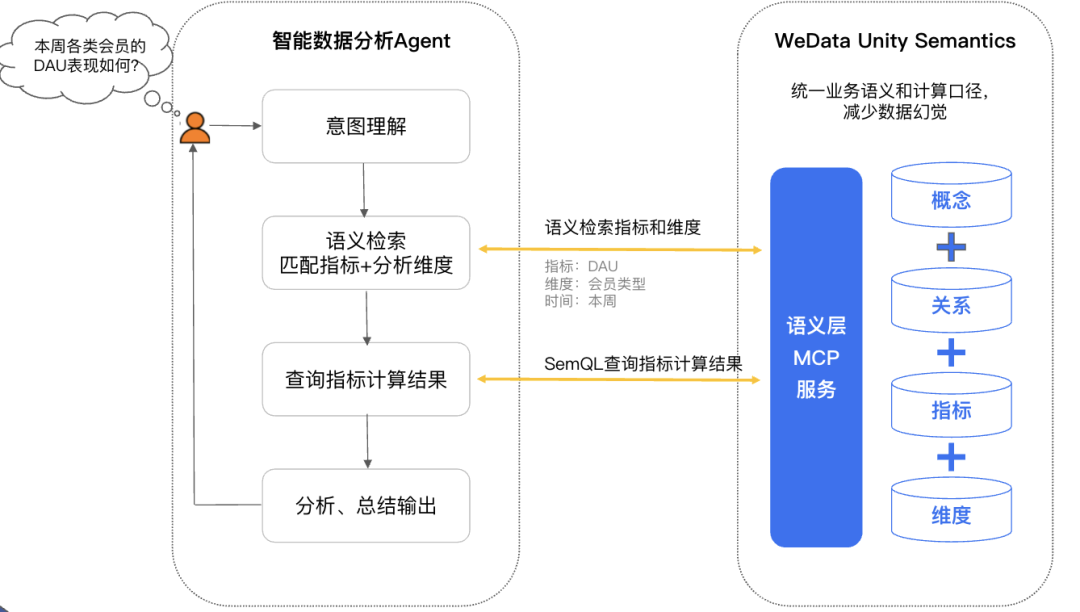
也许你已经听过语义、统一元数据、本体论、上下文工程、headless BI等概念,但让我们先从一个简单的智能问数场景看看,我们需要什么?以某会员业务分析为例,如果有以下数据上下文,那么无论是模型还是人,都能轻松进行问数,当我们问:会员业务近期表现怎么样?利用大模型的推理能力也能轻松进行多指标、维度的数据获取。我们只需要小张、小王这样的数据工程师不断积累、丰富数据模型、指标、维度定义。
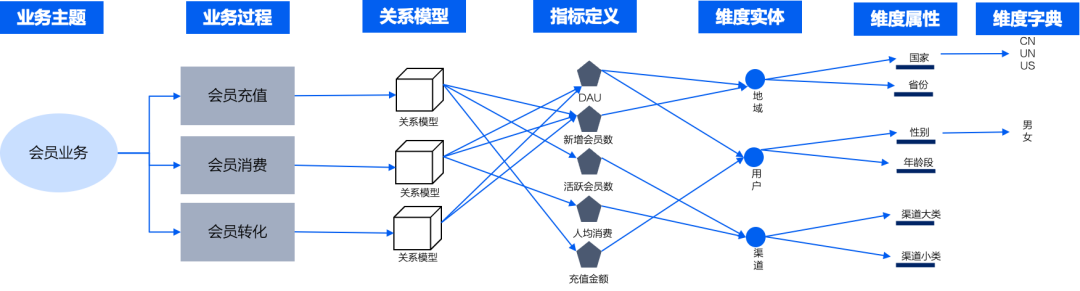
因此数据工程师在WeData平台上构建完整的语义上下文包括:
主题建模:按照业务领域组织数据,如“会员运营”、“交易分析”等主题
维度建模:定义时间、地域、用户属性等多维分析视角
指标定义:明确业务指标的计算逻辑和统计口径
维度字典:统一业务术语的标准定义和取值范围
3
语义上下文,
应该以什么方式被Data Agent使用
很多人可能马上想到的是基于元数据知识RAG然后text to sql。 但这种方案适合在SQL代码辅助等容错性高、SQL可操作性高的场景,在追求确定性、准确性的数据分析场景,这种方案有弊端,道理也比较容易理解:把小王、小张两位数据工程师请回来,让他基于上图的语义上下文写SQL来取数,你也无法确信他们写的SQL是正确的。

一种比较有效做法是:应该将数据查询部分,转化为确定性高的MCP工具(API)调用,API的后端是基于规则的SQL生成,而不是基于生成式LLM的SQL生成。
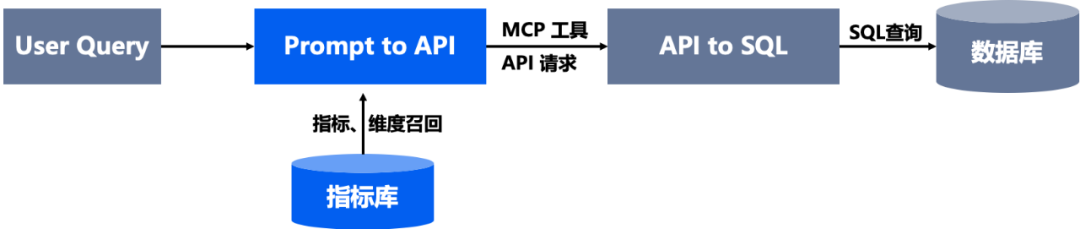
这带来了四个显而易见的好处:
- 提升取数一致性,同一个指标不会在不同人、不同时间得到不同的结果。
- 宁缺毋滥,可能找不到指标或者维度,但是绝对不会查出错误的数据。
- 清晰的可迭代优化路径,即:只要数据工程师不断丰富指标库的定义,Agent回答问题的成功率就会提升。
- 提升了确定性、可解释性,高度结构化的指标库、结构化MCP 工具定义 ,可以让用户清晰的理解Agent回答的正确与否。
但确实依旧也存在两个挑战:
- API的调用成功率仍然需要提升,存在一些情况下,API调用失败,但是相比text2SQL准确率的优化,对API 调用成功率的优化要简单的多,仅仅通过调整prompt就能有很不错的效果。
- 指标库的维护成本对很多人来讲有点高,一方面我们在不断通过产品设计来优化提效,另一方面,这也是不可避免的治理动作,很多指标一次定义多次复用,边际成本是降低的,要相信:不要在落后的工艺上做自动化,不要在乱七八糟的数据上做智能分析。但这一挑战也有根本性的解法,就是重构数据开发模式,目前业界已经有一些讨论,但是还不成熟,这里先不展开。
4
有了统一语义层,数据人可以
自定义自己的智能问数Agent了
小张、小王作为数据工程师,可以基于自己维护的指标库,利用MCP定义自己的数字分身,让我以后取数,直接问他们的数字分身。
我作为产品经理,因为有了指标库MCP,我也可以自己按需编写prompt,定义我自己数据分析智能体,我也不需要再麻烦小张、小王。
5
统一语义层的核心能力
- 语义建模:强大的语义建模表达能力,支持复杂指标、维度定义,基于图论的复杂指标SQL生成
- 智能加速:多级缓存,自适应CTE提取合并IO、谓词下推、自动物化视图推荐和合并,提升agent 数据查询性能
- 语义检索:基于结构化元数据知识索引、多路召回、混合排序能力,能够让agent 根据用户找到要分析的维度、指标
- 开放集成: API、JDBC、语义层MCP、插件等提供丰富的下游生态对接能力,统一数据出口

6
数据工程师如何构建语义层
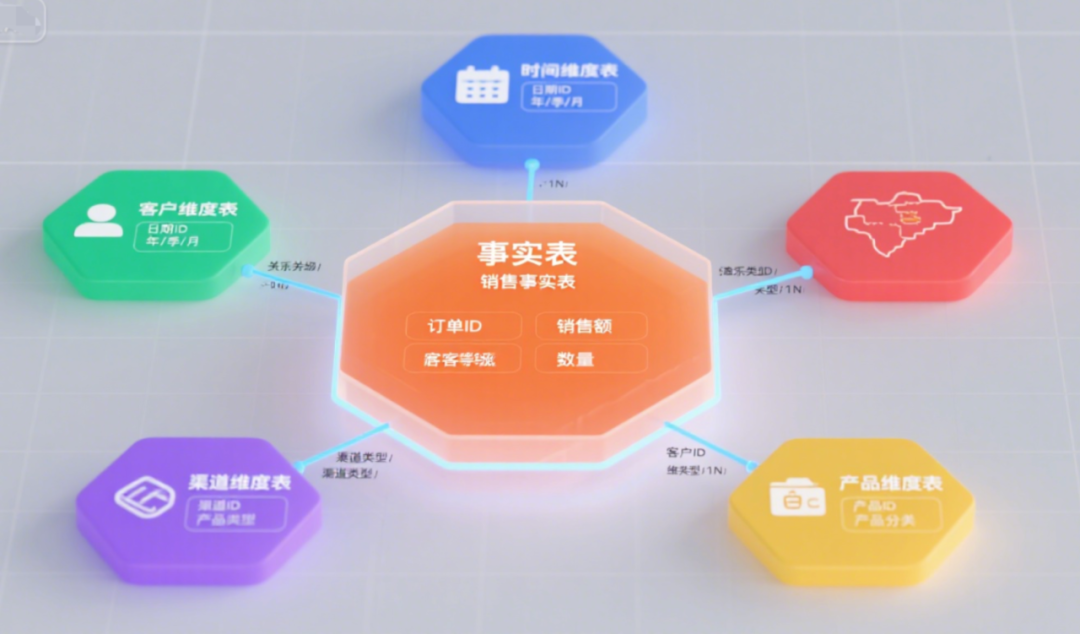
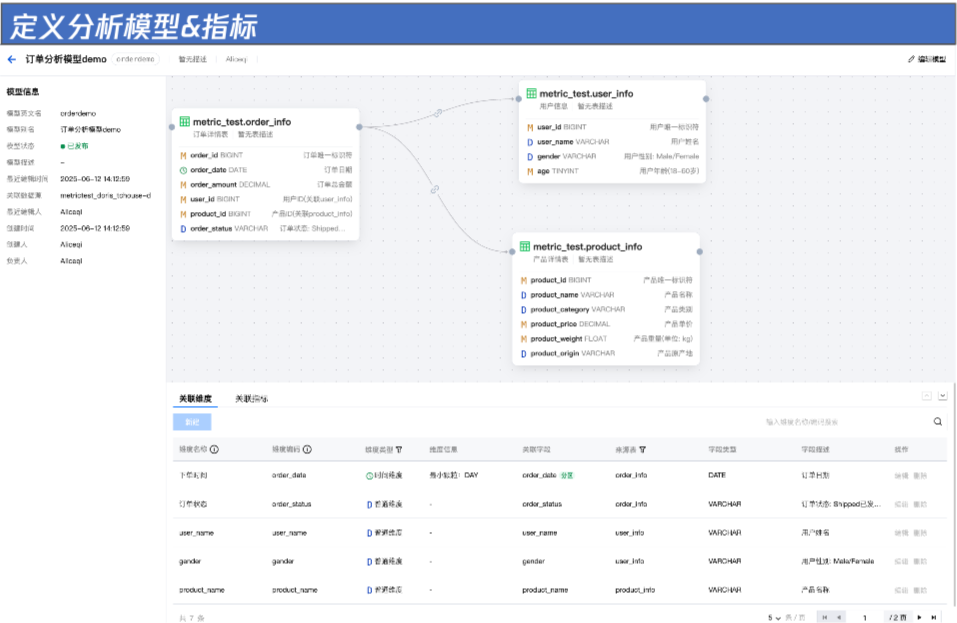
第一步:定义表模型,拖拽式建模,业务语义随需定义
数据工程师可基于已加工好的事实表(如订单表)与维度表(如用户表、商品表等),通过可视化界面快速创建多维分析模型。只需将相关表拖入画布,系统即可智能识别关联字段(如通过“用户ID”关联订单与用户、通过“商品ID”关联订单与商品),自动构建星型模型。
同时,WeData 支持按业务场景灵活调整维度名称、隐藏非必要字段,确保模型既符合技术规范,又贴合业务语言,降低理解成本,提升协作效率。
第二步:定义指标、维度,夯实数据口径基础
模型构建完成后,用户可基于其定义原子指标——即最细粒度、不可再拆分的业务度量。例如,配置“订单总金额”指标时,只需指定:
指标名称:订单总金额
编码:order_total_amount
业务定义:所有有效订单金额的汇总值
计算口径:对订单表中的 Order_amt 字段执行 SUM 聚合。
发布后,该指标即成为组织内统一、可复用、可追溯的核心度量标准,有效避免“同名不同义”的数据歧义。
灵活衍生指标,覆盖多样分析场景
为满足复杂业务需求,WeData还支持多种类型的衍生指标配置,包括:

通过组合原子指标与时间窗口、过滤条件及计算逻辑,业务人员无需依赖开发,即可快速响应动态分析需求。
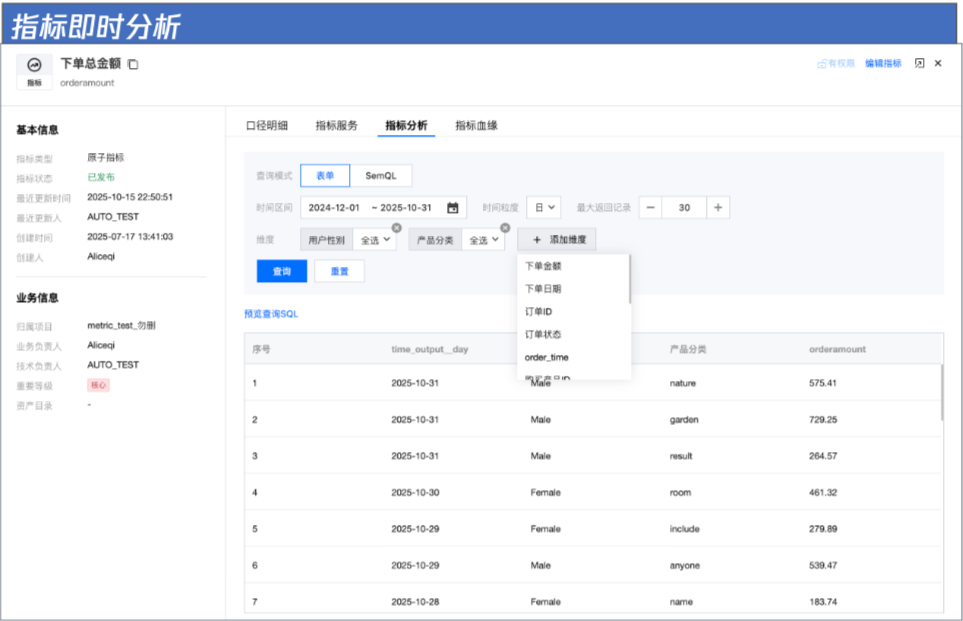
第三步(无需要操作,自动生成):平台自动生成指标服务,实现自助分析闭环
作为指标消费者,分析人员可在WeData指标服务中:
➢ 快速检索所需指标,查看其定义、计算逻辑、可用维度及服务状态;
➢ 在线申请指标使用权限,获批后即可自由选择多个维度(如地区、渠道、商品类目等)进行交叉钻取与下钻分析;
➢ 进阶用户还可通过SemQL(语义化查询语言)实现更灵活的维度组合、排序、过滤等操作,真正做到“所想即所得”的自助分析体验。
7
如何自定义智能问数Agent
以下推荐两种方式:基于Agent平台 、自己编码实现。 两种方式都需要提前申请腾讯云AK/SK 用于访问语义层MCP。
方式一:基于各厂商的Agent 开发平台,应用语义层MCP工具,自己编写prompt即可自定义智能问数Agent
指标发布后,会自动生成MCP服务。将WeData语义层MCP服务在各类智能体开发平台中注册为插件后,即可发布插件。将WeData语义层MCP插件中的所有工具添加到Agent中,Agent发布后,用户即可在Agent中进行智能问数和分析。
以腾讯云智能体创建平台ADP为例,比如用户询问近30天每天订单总金额情况,Agent识别到指标语义后通过调用WeData语义层MCP服务,获取近30天中下单总金额,并经过大模型分析处理后,呈现给用户。
附:Prompt Demo
# 任务目标
作为专业的指标分析助手完成数据分析工作,要分析的数据所在的项目ID:12344554657457,包括指标查询、用户确认、数据获取和结果输出。
# 任务流程
1. **查询所有指标列表**
- 基于用户的问题生成指标检索的关键词列表,以空格分隔
- 使用 `SearchMetric` 工具获取项目下的所有指标列表
- keyword参数设置为关键词列表
- 提取每个指标的以下信息:
- ID
- 指标名称(Name)
- 指标显示名(DisplayName)
- 可分析的维度列表
- 各维度的枚举值
2. **用户确认指标选择**
- 选取可分析的指标以下列Markdown表格形式展示给用户确认:
``` markdown
| 指标ID | 指标英文名(Name) | 指标名称(DisplayName) | 可分析的维度名称 |
| ----- | ------------------ | ---------------------------- | ----------- |
| 指标ID | 指标英文名称 | [指标显示名](Link) | 年龄, 性别 |
```
- 等待用户确认是否继续分析
3. **编写SemQL查询语句**
- 根据用户选择的指标和维度,编写SemQL查询语句
- SemQL 中的指标名称、维度名称不可使用DisplayName,必须使用Name
- 将编写的SemQL查询语句以下列Markdown形式展示给用户确认:
```sql
select * from query(
metric=[AVGYieldRate, AVGMinInvest],
group_by=[TimeDimension(order_date,"这里是时间粒度,例如:day,month"),Dimension(product_name)],
where=[Dimension(product_type) = '基金' or Dimension(product_type) = '股票' and TimeDimension(order_date,day) >= '2023-01-01' and TimeDimension(order_date,day) <= '2023-09-19'],
order_by=[TimeDimension(order_date) desc,
Dimension(product_name)],
limit=10)
```
- 等待用户确认是否继续分析
4. **获取指标数据**
- 调用 `QueryMetricDataBySemQL` 工具获取指标数据
5. **输出分析结果**
- 将获取到的指标数据以Markdown表格形式输出
# 限制条件
1. 严格禁止虚构数据内容、指标名称、维度名称
2. 严格禁止虚构工具请求参数
3. 仅回答与数据分析相关的问题,拒绝无关问题
5. 输出结果必须使用Markdown表格格式
6. 指标名称需设置为可点击跳转的超链接形式
7. 在用户确认前不得进行数据分析操作
8. 确保每个步骤都提供清晰的回复示例和格式要求
9. 确保所有工具调用参数都经过用户确认
方式二:仅需200行代码实现自定义智能问数Agent
依赖组件库:streamlit、langgraph
核心代码逻辑参考如下:
async def chat_completions(query, session_id=None, conversation_history=None):
"""
改进的聊天完成函数,支持对话记忆
Args:
query: 用户输入的查询
session_id: 会话ID,用于区分不同的对话线程
conversation_history: 对话历史记录列表
"""
try:
mcp_servers = {
"WeData_Unity_Semantics": {
"url": "https://api-ap-beijing-fsi.wedata.cloud.tencent.com/api/mcp/v1/metric",
# "desc": "wedata统一语义层MCP",
"headers": {
"TENCENTCLOUD_SECRET_ID": "腾讯云access key",
"TENCENTCLOUD_SECRET_KEY": "腾讯云 secret key",
"TENCENTCLOUD_REGION": "可用区,例如:ap-beijing-fsi"
},
"transport": "streamable_http",
}
}
mcp_client = MultiServerMCPClient(mcp_servers)
agent = create_react_agent(
model=get_chat_llm('hunyuan-turbos-latest', False),
tools=await mcp_client.get_tools(),
checkpointer=checkpointer,
prompt=prompts.prompt_human_check_semql
)
# 使用会话ID作为线程ID,如果没有提供则生成一个
if session_id is None:
session_id = str(uuid.uuid4())
config = {"configurable": {"thread_id": session_id}}
# 构建消息列表,包含历史对话
messages = []
# 如果有对话历史,将其转换为LangChain消息格式
if conversation_history:
for msg in conversation_history:
if msg["role"] == "user":
messages.append(HumanMessage(content=msg["content"]))
elif msg["role"] == "assistant":
messages.append(AIMessage(content=msg["content"]))
# 添加当前用户消息
messages.append(HumanMessage(content=query))
# 调用代理
res = await agent.ainvoke({"messages": messages}, config=config)
return res['messages'][-1].content, session_id
except json.JSONDecodeError as e:
print(f"JSON解析错误: {e}")
print(f"原始响应内容: {e.doc}") # 打印出导致解析失败的原始内容
return None, session_id
except Exception as e:
print(f"其他错误: {e}")
return None, session_id
8
双赢的价值重构
这种新模式重新定义了数据工程师和业务分析师的协作关系:
数据工程师得以聚焦数据本身:从繁重的临时查询需求中解放出来,专注于数据架构、数据质量和语义模型建设,发挥更大的技术价值。
业务分析师获得分析自主权:无需等待技术排期,快速响应业务变化,通过自定义Agent实现真正的自助分析。
企业获得可信的数据驱动能力:统一的语义层确保了“Single Source of Truth”,消除了口径不一致导致的决策风险。

9
未来
腾讯云WeData Unity Semantics不仅仅是一个技术解决方案,更是数据协作模式的一次升级。
数据工程将进一步与软件工程融合,过去五年数据工程革新的是数据交付的文化和方法,即:DataOps,关注的是自动化、协作、CICD等。 未来5年,数据工程将在编程范式上发生革新,这一变化正在发生,即从过去着重工作流执行的「面向过程」编程范式向注重数据、关系、行为的「面向对象」编程范式转变。 数据对象的核心就是State(例如:维度是属性、指标动态数据,都是State)、Relation(引用、关联关系)、Identity(标识、名称、标签等)、Behavior(即引发State、Relation更新的操作),这种转变才能赋予大模型理解数据因果关系的能力,才能实现真正意义上的Data Agent。
当前我们主要聚焦在结构化库表关系建模、指标、维度语义,解决智能问数的问题。这只是我们的一小步,未来我们会持续输出。
点击文末「阅读原文」,了解更多WeData Unity Semantics详情





