


本文来自腾讯蓝鲸智云社区用户:fadewalk
在问答社区看到有小伙伴在落地蓝鲸的过程中出现监控平台的grafana面板数据断点问题,往往出现这种问题,都比较的头疼。
如果将CMDB(配置管理数据库)比作运维的基石,那么监控可以比作运维的"眼睛"或"感知器"。监控在运维中起着至关重要的作用,类似于人的视觉系统,它可以实时监测和感知系统、应用程序和基础设施的状态和性能。
监控在运维中是一个非常重要的组成部分,它为运维团队提供了关键的信息和洞察力,帮助他们及时响应和解决问题,保障系统的稳定运行和业务的顺利进行。下面将对监控数据断点可能得问题进行排查和分析。
我们知道Grafana是一个用于可视化和监控数据的开源平台。它提供了丰富的功能和灵活的配置选项,可以用于创建各种类型的面板来监控不同的数据源。
分析
关于数据断点的情况,如果是Grafana面板上数据图表中的断点,即数据在某个时间点突然中断或消失,或者出现一段时间连续,一段时间不连续,可能有以下几种可能的原因:
1、数据源问题:数据源在某个时间点停止发送数据或者出现故障,导致面板上的数据断点。您可以检查数据源的连接和状态,确保数据源正常工作。
2、查询问题:面板中的查询语句可能存在问题,导致数据断点。您可以检查查询语句的正确性,包括时间范围、过滤条件等,确保查询返回正确的数据。
3、数据处理问题:在数据传输或处理过程中,可能发生了错误或丢失,导致数据断点。您可以检查数据传输和处理的过程,确保数据在各个环节都得到正确处理。
4、数据可用性问题:某些数据可能只在特定的时间段内可用,而在其他时间段内不可用,导致面板上的数据断点。您可以检查数据源的可用性和数据的时间分布,确保数据在所需的时间段内可用。
以上是一些可能导致Grafana面板上数据断点的情况。具体情况可能部署的配置、数据源和查询等因素而异。
下面是蓝鲸的监控数据链路方向
从左到右是数据的采集上报的方向

采集器
蓝鲸的监控数据是通过bkmonitorbeat 这个监控插件采集。先找一台断点严重的看看bkmonitorbeat采集器的日志,有没有啥异常。
# 查看进程
ps -ef|grep bkmonitorbeat
# 查看日志
tail -f /var/log/gse_bkte/bkmonitorbeat.log
Gse Agent
确保agent的状态是绿色可用的
检查agent的日志,看下system 日志
查看 TCP:58625 端口是否存在
Gse DataServer
检查 bk-gse-data 这个pod 是否正常,日志是否正常,连接kafka是否正常
Kafka
可以检查下kafka的吞吐率,日志是否有大量堆积,消费不过来的情况。
这里建议对kafka做一个监控,可以使用kafka exporter,jmx exporter
蓝鲸默认的kafka是单节点单分区模式,
如果单节点的kafka存在瓶颈的话可以考虑扩容节点,扩建分区 ,比如:三节点、三分区
https://${domain_name}/admin/metadata/kafkatopicinfo/?q=1001
检查kafka topic 分区
Transfer
bk-monitor-transfer-default-* 监控链路传输组件,负责从 kafka 消费数据并写入到 ES/influxdb
检查 bk-monitor-transfer-default-xxxx 这个pod是否正常,是否在重启,日志是否正常。
蓝鲸容器版本的Transfer pod 做了limit 资源的限额,如果你采集的数据量很大,存在Transfer pod 消费写入压力比较大,或者出现OOM被杀,而频繁重启。建议去掉Transfer pod的资源限制。
检查Transfer的日志,是否有链接kafka失败,获取topics失败的日志。
服务端的功能排查,主要集中在 transfer 和 influxdb-proxy 两个模块。两个模块都提供有指标接口,分别可以通过下面的方式获取两个模块的指标数据
#transfer
curl $BK_MONITORV3_TRANSFER_IP:$BK_TRANSFER_HTTP_PORT/metrics
1) 排查transfer是否正常
* 指标 transfer_pipeline_frontend_dropped_total
含义: transfer拉取kafka数据失败条数
处理建议: 如果观察该值不断增长,需要观察transfer日志,排查transfer与kafka的链接是否正常
* 指标 transfer_pipeline_processor_dropped_total
含义: transfer处理异常数据丢弃数量
处理建议: 如果观察该值不断增长,观察日志确认数据被丢弃原因
* 指标 transfer_pipeline_backend_dropped_total
含义: transfer数据入库丢弃数量
处理建议: 如果该值不断增长,可以观察日志确认写入失败原因,同时检查对应的存储(influxdb/ES)是否有异常
如果观察到是写入异常或无任何异常指标,此时需要观察influxdb-proxy
Influxdb-Proxy
bk-monitor-influxdb-proxy-* influxdb-proxy 负责 influxdb 的直接写入和查询。
这个pod是跟Influxdb 打交道的,这个默认也做了limit限制,如果你的数据量很大,建议去掉limit限制。
#influxdb_proxy
curl $BK_MONITORV3_INFLUXDB_PROXY_IP:$BK_INFLUXDB_PROXY_PORT/metrics
2) 排查influxdb-proxy及influxdb
* 指标 influxdb_proxy_backend_alive_status
含义: influxdb_proxy_backend_alive_status
处理建议: 如果发现有任何一个后端为0,表示此时proxy到influxdb链接异常,需要检查influxdb为何不存活或链接异常
* 指标 influxdb_proxy_backend_backup_status
含义: influxdb-proxy异常数据备份数量
处理建议: 如果该值不断在增长,此时应该检查influxdb-proxy确认influxdb写入异常原因,并对influxdb进行修复
Influxdb
最后到了数据真正写入的节点。
社区版本的蓝鲸influxdb 是单节点的,蓝鲸企业版本是influx双节点。
influxdb 的社区免费版本也是单节点的,高可用的版本需要购买influxdb license。
当然社区也有一些魔改的各种版本,感兴趣的小伙伴可以尝试。
当出现数据断点的时候开启对influx的监控,将influx的内部情况做到一个grafana 面板,可以使用telegraf 或者在蓝鲸的grafana直接配置influx的数据源。
可以根据自己的需求选择
1、Telegraf: system dashboard
InfluxDB dashboards for telegraf metrics
2、采用influx数据源,读取internal 监控库的可以使用下面这个面板
InfluxDB Internals
InfluxDB internal metrics display
这里我使用的是第二种监控方式,
当出现数据断点的时候,通过前面的排查,都莫有发现明显的异常。
但是到了influxdb这里,检查监控发现
- influxdb Cache监控发现 disk bytes 为0B
- Https 监控出现了大量的客户端 client error
- database 监控发现了大量的 write error
一开始怀疑是 Transfer pod 的问题,但是检查发现Transfer pod 并未出现明显的异常,没有重启。
influx-proxy 有大量的 http 请求失败的日志
因此可以断定是influxdb 写入失败,导致客户端大量请求异常,从而导致采集的数据无法入库,自然在grafana监控面板出现数据断断续续。
经过检查influx的数据库表和配置参数
发现是 series 超过了influx 的默认限额导致无法写入数据
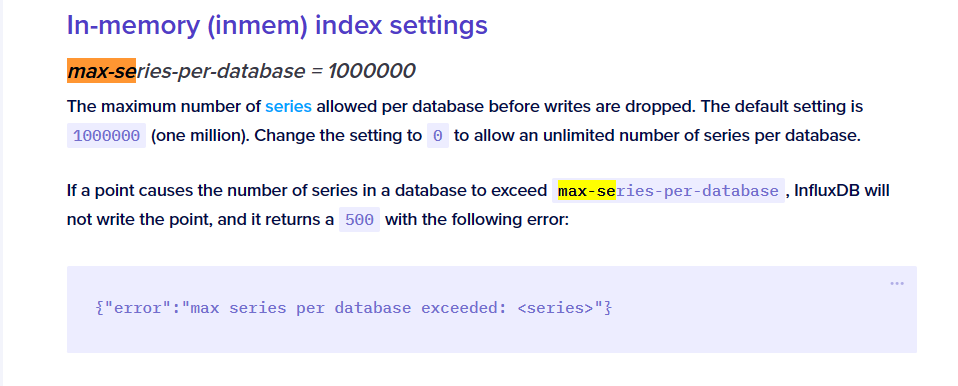
每个数据库允许的最大series数。默认设置为 1000000(一百万)。将设置更改为 0 以允许每个数据库的系列数量不受限制。
如果某个点导致数据库中的系列数量超过 max-series-per-database,InfluxDB 将不会写入该点,并返回 500 并显示以下错误:
{"error":"max series per database exceeded: <series>"}
[max-series(https://docs.influxdata.com/influxdb/v1.7/administration/config/#max-series-per-database–1000000)
这里将influx 部署的yaml 配置文件修改为
....
config:
data:
max-series-per-database: 0
....
influx 内存优化
更改索引方式
InfluxDB 默认的索引是在内存上维护的,不断地数据增长会使用越来越多的内存,并有一个参数 index-version 可以设置索引方式1。如果是直接在主机上部署的可以修改配置文件,Docker 部署则需要通过环境变量设置:
index-version = "inmem"
用于新分片的分片索引类型。默认 (inmem) 索引是在启动时重新创建的内存中索引。要启用基于磁盘的时间序列索引 (TSI) 索引,请将值设置为 tsi1。
[Environment variable: INFLUXDB_DATA_INDEX_VERSION](https://docs.influxdata.com/influxdb/v1.7/administration/config/#index-version--inmem)
将索引数据存储在磁盘上,可以通过日志或者查看分片的目录结构验证修改是否生效,若索引方式为 tsi1,在分片目录下会有一个名为 index 的目录,inmem 索引则没有。
具体位置是 /var/lib/influxdb/data/<数据库>/<保留策略>/<分片>。
[root@izuf6czs1dw6siz3zokdiez 1_day]# ls
1 10 11 12 13 14 15 16 18 19 20 21 3 4 5 6 7 8 9
[root@izuf6czs1dw6siz3zokdiez 1_day]# cd 15
[root@izuf6czs1dw6siz3zokdiez 15]# ls
000000001-000000001.tsm fields.idx index
存储介质
硬件方面
influx 这种高IO的软件一般都建议使用SSD固态硬盘进行存放数据。
因为参数优化需要结合不同的实际环境,所以这里更多的需要小伙伴自己去探索。更多的优化,比如请求等可以参考influx config 文档
其他优化
在InfluxDB的配置文件中,通常有两个主要部分:http和data 可以进行参考优化
http部分:
max-concurrent-write-limit: 0:此参数控制同时写入数据的最大并发连接数。设置为0表示没有限制,可以并发无限制写入数据。
max-enqueued-write-limit: 0:此参数设置写入数据时的最大队列长度。设置为0表示没有队列长度限制。
max-connection-limit: 0:此参数控制InfluxDB HTTP服务的最大连接数。设置为0表示没有连接数限制。
max-row-limit: 0:此参数控制查询结果的最大行数限制。设置为0表示没有行数限制。
max-body-size: 0:此参数设置HTTP请求的最大请求体大小限制(以字节为单位)。设置为0表示没有请求体大小限制。
log-enabled: false:此参数控制是否启用HTTP请求的访问日志。设置为false表示禁用访问日志。
data部分:
max-series-per-database: 0:此参数控制单个数据库中允许的最大时间序列数量。设置为0表示没有时间序列数量限制。
max-values-per-tag: 0:此参数控制单个标签键值对(tag key-value pair)允许的最大值数量。设置为0表示没有标签键值对数量限制。
max-series-per-request: 0:此参数控制单个请求中允许的最大时间序列数量。设置为0表示没有请求中时间序列数量限制。
index-version: tsi1:此参数设置InfluxDB使用的索引引擎版本。"tsi1"表示使用Time-Structured Merge Tree索引引擎。这里是数字1 注意,不是英文的l 容易混淆
cd /root/bkhelmfile/blueking
vim ./environments/default/influxdb-custom-values.yaml.gotmpl
config:
data:
max-series-per-database: 0
max-values-per-tag: 0
max-series-per-request: 0
index-version: tsi1 # 最后面是数字 1
http:
max-concurrent-write-limit: 0
max-enqueued-write-limit: 0
max-connection-limit: 0
max-row-limit: 0
max-body-size: 0
log-enabled: false
同步配置
helmfile -f monitor-storage.yaml.gotmpl -l name=bk-influxdb sync
重启pod生效
kubectl rollout restart StatefulSet -n blueking bk-influxdb
索引 index-version: tsi1 这里如果一开始没有采用tsi1,那么你改配置后是不生效的,需要重建influxdb才能使生效。重建会有数据丢失风险,根据自己的需要调整。
小结
总结监控数据断点的解决思路
1、检查数据各节点进程、日志
2、确保各节点传输正常
3、确保内存资源充足
4、最后最关键的就是influx的参数优化
可以发现蓝鲸的大多数组件都是默认的参数配置,这是为了控制部署的时候的资源消耗,但我们在实际运用的过程中,资源足够的情况下,还是要结合直接的真实环境区去除或者优化参数,以达到最佳的体验效果,保障系统的稳定性。
以上便是这次分享,如果其他小伙伴有其他的思路和问题,可以留言一起讨论。





