


现今,许多B端设计师在日常设计中难免会遇到各种运营 3D banner 设计需求。在设计过程中,他们不仅需要费尽心思构思各种造型,还要不断进行重复渲染,而有时渲染结果也难以令人满意。本文旨在介绍一种基于 Stable Diffusion 混合 AI 的B端 3D Banner 设计方法和流程,可供任何对该领域感兴趣的人进行实验,创作出各类B端模型。
部署 Stable Diffusion 流程
云端部署
首先,需挑选一台腾讯云的 GPU 服务器。GPU 卡型本次选择 V100,对应“GN10X”机型。从 GPU实验室活动页可购买特价的折扣机型。

注意,点击立即购买后,预装镜像要选择“Docker基础镜像”。若选择其他镜像,会导致无法顺利跑通本流程。

拉取镜像(10-15min)
登录机器后,直接输入如下命令,拉取容器镜像。拉取约需10-15min,可以先喝杯茶,休息一下。
sudo docker pull gpulab.tencentcloudcr.com/ai/stable-diffusion:1.0.8
拉取中

拉取完成
启动容器,完成部署(1min)
复制粘贴下述命令,启动容器,完成部署。
sudo docker run -itd --gpus=all --network=host --device=/dev/dri --group-add=video --ipc=host --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --name=stable-diffusion gpulab.tencentcloudcr.com/ai/stable-diffusion:1.0.8 | xargs sudo docker logs --follow
使用生成的 public url,即可启动 AI 绘画环境(如果生成 public url 失败,可使用下面命令重启容器)。

生成链接,若需重启容器,输入以下命令即可:
sudo docker restart stable-diffusion | xargs sudo docker logs --follow
本地安装 Stable Diffusion
| | 优势 | 劣势 |
|---|---|---|
| 云端安装 | 根据情况选择硬件,成本可控;即开即用 | 需要手动安装插件;部署存在一定门槛 |
| 本地安装 | 预装包插件较完整 | 极度依赖本地硬件;成本高 |
本地安装教程可参考视频教程。
3D banner 模型训练流程

收集设计素材,准备训练集
设计师在寻找素材尽可能风格上统一,图片本身的质量较高(指看得清楚)。图片的数量也不是越多越好,数量大概在20张以内,5张以上就好(目前使用的是腾讯云的运营活动 Banner)。
图片处理与裁切
对图片进行裁切和处理,尽可能让素材中的主元素在画面的中间,图片的大小处理为方形大小(512 * 512),处理的原则模型主体清晰。

图片预处理操作(手动为图片添加描述)
打标的处理方法相对前步骤会比较麻烦,因为B端 banner 都偏抽象类型,很难用一句话描述清楚,所以这里我们也不能使用 Stable diffusion 默认的预处理图片方式,我们选择手动打标的方式,描述分为两个模块:底座造型的描述和主体造型的描述。
底座的描述:一个方形白色为主的蓝色点缀底座,圆形的装饰物,发光灯条,透明玻璃材质,蓝色的玻璃质感,白色科技感。
主体的描述:白色科技感,几何图形,球形,立方体,蓝色玻璃质感,蓝色科技感,科技感,立方体发光,透明玻璃材质,云ICON,云logo。
针对每张图新建一个 text 文档添加描述,我们将上述内容手动改为英文:A white square base with blue accents, circular decoration, glowing light bars, transparent glass material, blue glass texture, white tech feel, geometric shapes, spherical, cubic, blue glass texture, blue tech feel, tech feel, cubic glowing, transparent glass material, cloud icon, cloud logo.

使用 Dreambooth 进行训练

创建模型
在“1“这里输入你训练出来的模型的名称,你可以按照你的喜好随意起一个英文名,例如:tencentcloud_icon/tencentcloud_banner 之类的,使用 A100 GPU 训练一个模型只需要5分钟,所以可能会训练多个模型来做对比测试,时间一长你就不知道这些模型是干啥的了,所以我建议规范命名,能清楚阐述模型的效果。
“2”这里选择基底模型,Dreambooth 模型是基于一个现成的模型生成的,理想情况下,你训练出来的新模型中:你训练的主元素由你训练出来的这部分绘制,其他内容由基底模型生成(基底模型决定了整个新模型的风格,如果用的是二次元的模型,最后出来的风格也就是二次元的icon)选择一个基础模型来进行训练,我们这次是基于 lyriel_v14.safetensors (这是一款偏写实人物的模型,通过C站搜索可直接下载)。
点击“3”创建模型。

开始训练
“1”“2”输入你的模型的存放目录和输出目录(文件夹命名的方式例如:tencentcloud_in,tencentcloud_out)。
输入图片的尺寸(因为之前已经把图片的尺寸调整为512x512,那么这个地方直接输入就好)。
因为我们已经手动为图片打标过了,所以我们需要把 Stable diffusion 生成的打标内容手动替换成我们自己的文本内容。
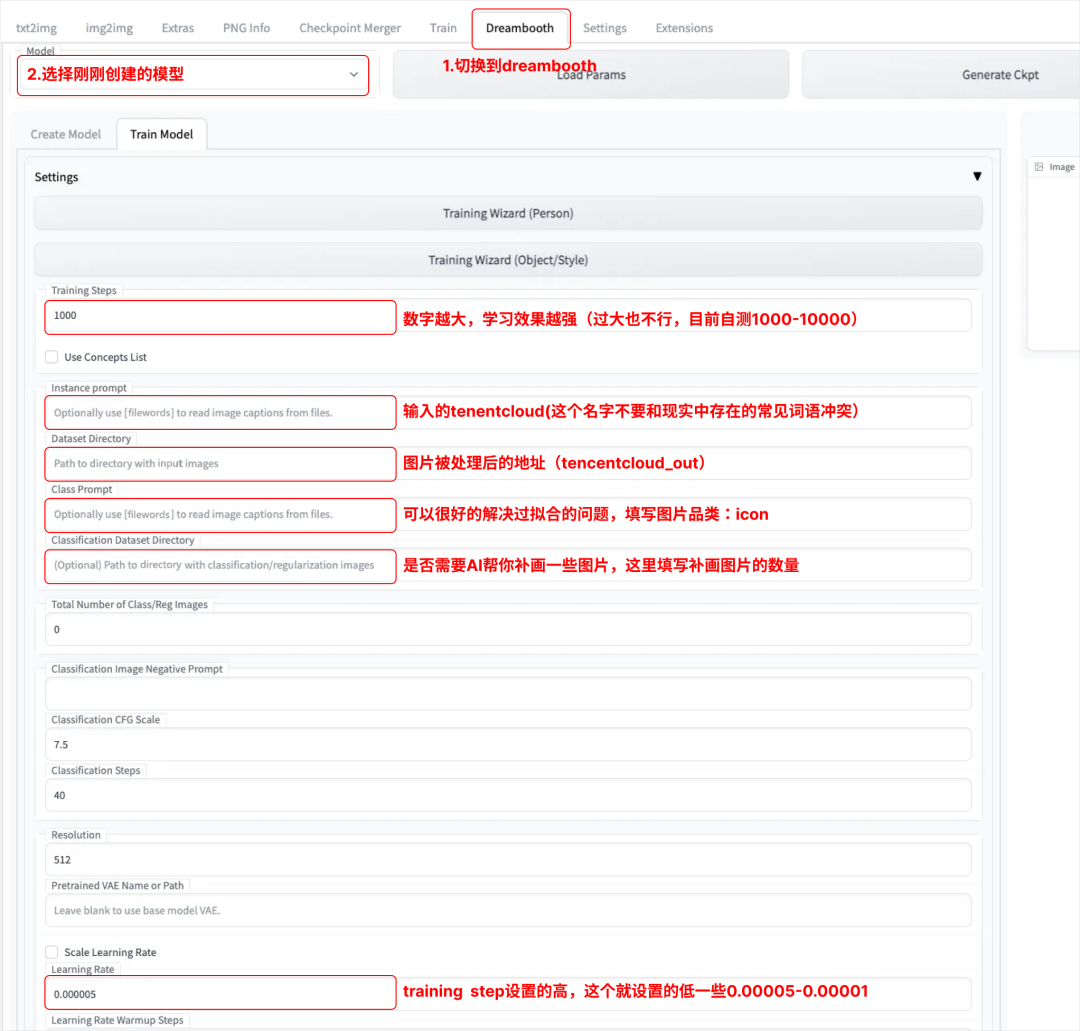
Dreambooth 设置
- 到 dreambooth 选项卡中,选择刚刚创建的模型:tencent cloud_banner
- Instance prompt:输入的 tenentcloud(这个名字不要和现实中存在的常见词语冲突)
- Dataset Directory:填写你输出的图片和文本的目录
- Class Prompt:填写icon/或者品类
- Classification Dataset Directory 和 Total Number of Class/Reg Images 的参数根据自己的需要来填写,例如:40
- Learning Rate 和 Training Steps 这两个选项都是决定训练强度的,数字越大,学习效果越强,学习效果越强,就越容易过拟合,但是过低又会欠拟合
- Train Wizard 如果是训练人物模型的可以选择 lora,不是的话可以不用选择
- 点击"Generate Ckpt",大概4个小时之后就可以炼丹成功(根据显卡配置测算时间,2080T大概时间6小时,3080T大概时间4小时)
设计师生产流程

文生图生成内容
- 关键词写法:内容,风格,质量,视角四个方向填写关键词
- 以“服务器”为例。正面关键词:A server, a round object with blue center and top white center, top with light blue center and white center, white background, very high quality 3D ICON. The model is divided into two parts, top and bottom. The bottom is a white metal cube with a slightly glassy texture. There are metal screws at all four corners. The screws are very small. There is only one main object in the scene, the object is on the right side of the screen, and the camera is an isometric perspective. X-axis is -20°, y-axis is 45°, z-axis is 0°, masterpiece, best quality, high resolution ;负向描述:nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry,fuzzy structure
- 采样迭代步数:20-30(不是越高越好,过高也会出现抽象的内容)
- 生成数量:跟随自己的电脑配置来填写参数,配置好填写数量高,配置低填写低
- 宽度/高度:512*512
- 最后的生成效果(我们挑选了一些生成较好的效果)

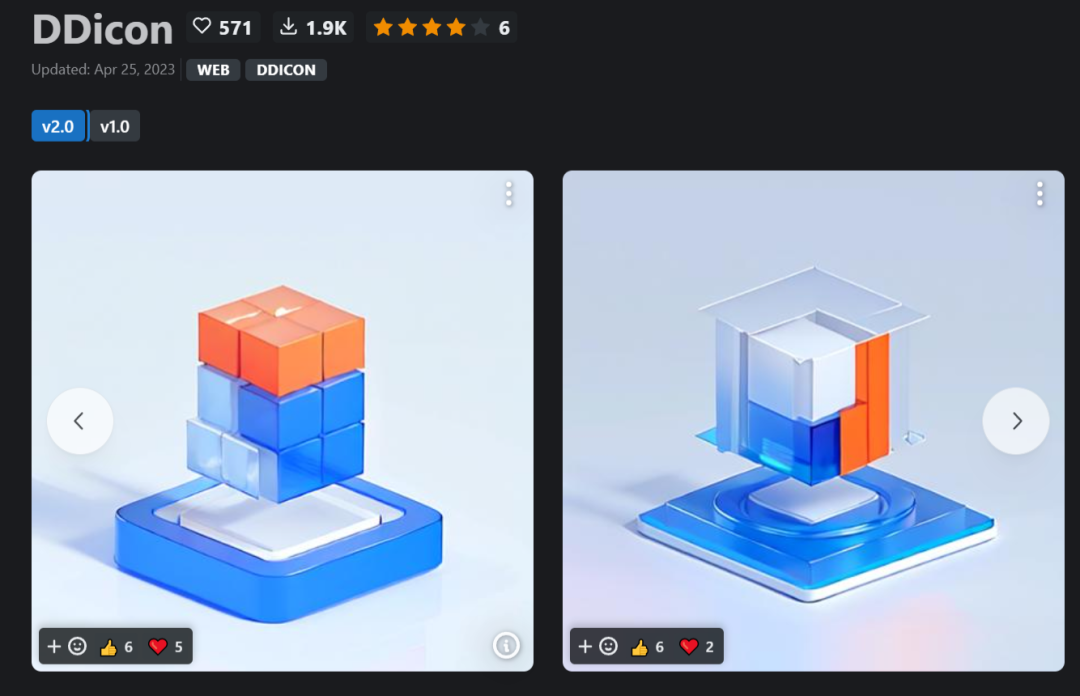
混入 Lora 生成内容
再生成的时候融入了 DDiconLora 模型(可在C站下载)。
- 以“AI 大脑”为例。正面关键词:A brain, a round object with blue center and top white center, top with light blue center and white center, white background, very high quality 3D ICON. The model is divided into two parts, top and bottom. The bottom is a white metal cube with a slightly glassy texture. There are metal screws at all four corners. The screws are very small. There is only one main object in the scene, the object is on the right side of the screen, and the camera is an isometric perspective. X-axis is -20°, y-axis is 45°, z-axis is 0°, masterpiece, best quality, high resolution lora:DDicon:1;负向描述:nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry,fuzzy structure
- 采样迭代步数:20-30(不是越高越好,过高也会出现抽象的内容)
- 生成数量:跟随自己的电脑配置来填写参数,配置好填写数量高,配置低填写低
- 宽度/高度:512*512
- 生成结果:


当我们在关键词中一些“球体”关键词,也有一些抽象图形的产生。

当我们在关键词中一些“爱心”关键词,也有一些爱心图形的产生。

同样的方法我们也训练了其他的风格效果(目前跟腾讯云简介页设计风格一致)。

另外一种风格的尝试:

后期放入到运营场景使用。使用相同方法,不同尺寸进行场景风格测试,通常可用于场景头图 banner 绘制,做商用的状态。


结语
总的来说,AI 技术的发展为B端设计师提供了更多的创作可能性和工具。本文介绍的基于 Stable Diffusion 混合 AI 的 3D Banner 设计方法,不仅能够减少设计师的重复渲染工作,还能够创造出更加出色的设计作品。
我们相信,随着 AI 技术的不断发展,它将会在B端创作中发挥越来越重要的作用,为设计师们带来更多的创作灵感和更高效的工作方式。这种新思路的出现,不仅可以提高设计师的工作效率和创作质量,也能够为企业带来更多的商业价值。因此,我们期待着更多的 AI 技术能够应用到B端创作中,为这个行业带来更多的创新和突破。






