



人工智能作为推动数字经济发展的算力基础和重要支撑,已经广泛运用于诸如自然语言处理、图像识别、自动驾驶、医疗诊断、金融风控等各大应用领域。其中在深度学习分支,模型训练是一个非常耗时和计算密集的过程,需要大量的计算资源和时间。
随着算力需求的不断增长,计算集群规模不断扩大,模型训练计算节点之间网络性能要求也越来越高,其中高吞吐和低时延成为两个重要的关键诉求。
云上实现节点间高速低延时互联通常需要高性能专有计算集群,通过专用的交换机,支持集群节点高速低延时的 RDMA(Remote Direct Memory Access)互联,为大规模集群提供高效的多机加速比。
由于使用了专用的网卡和交换机硬件,RDMA 集群设备往往都需要花费高昂的费用来换取更高性能的网络通信能力;而腾讯云最新自研技术弹性 RDMA 网卡 EFI 旨在为客户提供云上大规模普惠 RDMA 能力,用户无需多付额外成本、无需改变业务组网,即可在 VPC 网络下体验 RDMA 加速互联能力。
EFI 是什么
弹性 RDMA 网卡(Elastic Fabric Interface,EFI)是一种可以绑定到 CVM 实例的虚拟网卡,用户可在 CVM 实例上添加该设备,即可获得相较于常规的弹性网卡(Elastic Network Interface,ENI)接口更低延迟和单链接更高吞吐的服务,推荐应用于高性能计算、机器学习等领域。
EFI 有什么优势特点
- 低延迟。传统 RDMA 将数据传输到网络上不需要经过 Kernel 以及无内存拷贝,从而实现低延迟。EFI 具有传统 RDMA 网卡的优点,超低的延迟让用户在云网络中体验到 RDMA 带来的优越性能。
- 高吞吐。为达到高带宽的目的,传统 RDMA 将可靠传输协议和内存地址转换卸载到 HCA 中,以降低 CPU 和内存带宽开销。EFI 采用相似的技术路线实现高吞吐目标。
- 高可用性。EFI 设备底层采用腾讯自研传输协议,其包含高可用设计:在网络设备故障时,可在数毫秒内感知故障并自动规避,从而降业务层长尾延迟。
- 规模部署。传统 RDMA 基于无损网络,规模部署成本高且困难。EFI 仅依赖有损的以太网络,基于自研的拥塞控制算法实现类似无损网络,从而实现规模化部署。
EFI 功能点
EFI 支持绝大部分的 RDMA 功能,支持多种不同的模式以实现高速数据传输和处理,主要包括以下几个功能:
- Message:Message 是一种基于 RDMA 的点对点通信模式,用于在两个节点之间进行消息传递。在 Message 模式下,发送方将消息写入本地内存,然后通过 RDMA 操作将消息发送到接收方的内存中。接收方可以通过 RDMA 操作读取消息,并进行相应的处理。
- Memory:Memory 是一种基于 RDMA 的内存访问模式,用于在两个节点之间进行内存读取和写入。在 Memory 模式下,发送方可以直接访问接收方的内存,从而实现高效的内存读取和写入。
- Event:Event 是一种高效的 RDMA 操作模式,可以在不阻塞 CPU 的情况下进行 RDMA 操作。在 Event 模式下,EFI 可以直接将 RDMA 操作的结果通知给应用程序,而不需要 CPU 的干预。
- Inline data:Inline data 是一种高效的 RDMA 操作模式,可以将数据直接嵌入到 RDMA 操作中,从而避免了数据传输的额外开销。在 Inline data 模式下,EFI 可以直接将数据写入到内存中,而不需要通过 DMA(Direct Memory Access)操作进行数据传输。
| 功能 | 支持情况 |
|---|---|
| RDMA语义 | - Message: Send, Send with IMM - Memory: Write, Write with IMM, Read, Atomic |
| QP类型 | Reliable Connection(RC) |
| Event模式 | 支持 |
| Inline Data模式 | 支持 |
EFI 性能表现
由于 EFI 在原组网的基础上便可实现 RDMA 网络互联的能力,因此在同一个 CVM 实例上并不需要有额外的花费支出,但 EFI 的性能表现相比 ENI 却可以获得不小的提升。
静态延迟
静态延迟即在没有背景流量情况下,测试报文单向传输延迟。静态延迟性能是衡量网络型的重要指标之一,直接影响了网络通信的实时性和响应性,对于需要进行大规模数据传输和处理的应用场景尤为重要。在同一 CVM 实例下,基于 EFI 的 RDMA 单向传输延迟仅为基于 ENI Kernel TCP 的三分之一,传输时延可降低67%。

单链接吞吐
单链接吞吐是指在网络通信过程中,单个链接在单位时间内传输的数据量。在单链接吞吐场景下,同一实例基于 EFI RDMA 的单QP吞吐相比基于 ENI 的 kernel TCP 可提升70%。

EFI 最佳实践
EFI 为 CVM 实例带来了低延迟、高吞吐的网络通信能力,可适用于大规模分布式计算和机器学习等领域。EFI 可支持多种集合通信框架,推荐基于以下通信框架进行使用体验:
- NCCL(Nvidia Collective Communications Library):NCCL 是一种由 Nvidia 开发的集合通信库,可以实现多个 GPU 之间的通信和协同计算。EFI 可以与 NCCL 库配合使用,提供高效的 GPU 集合通信能力,从而加速深度学习和机器学习的训练速度和效率。
- TensorFlow-Parameter Server:TensorFlow-Parameter Server 是一种用于分布式训练的架构,可以将模型参数存储在一个或多个参数服务器上,并将训练任务分配给多个工作节点进行并行计算。在 TensorFlow-Parameter Server 架构中,参数服务器负责存储和更新模型参数,而工作节点负责计算梯度和更新模型参数。
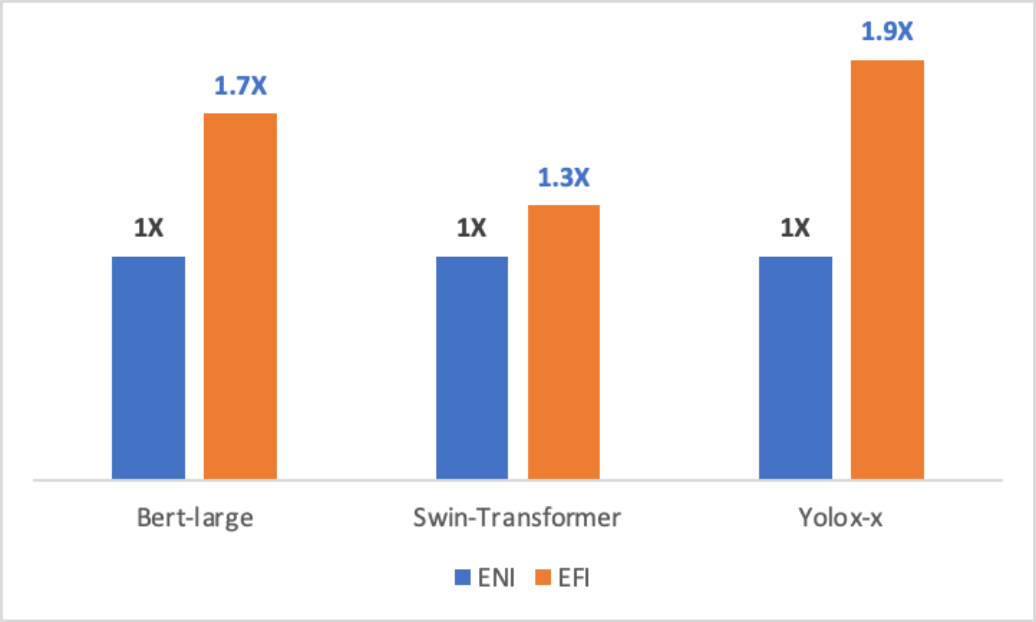
在多机多卡训练场景下,EFI 的性能得到了更大程度的发挥和运用,可以进一步提高分布式训练的效率和性能。实验结果显示 EFI 在多个不同的训练模型下,都有明显的性能提升表现。以下为具体的实验结果表现,在相同实例环境下,搭载使用了 EFI 的实例性能提升了30%-90%不等。
如何体验
腾讯云最新自研技术 EFI 现已发布内测,可支持 GPU 型 PNV4ne,适用于小型分布式 AI 训练场景。在不增加额外费用的前提下,用户可以体验高性能的 RDMA 网络通信能力。如果您对腾讯云自研技术 EFI 感兴趣,欢迎点击链接进行 EFI 内测申请。腾讯云致力于为客户提供云上大规模普惠 RDMA 能力,助力用户降低成本,提高效率。






