



最近突然感觉:很多软件、硬件在设计上是有root reason的,不是by desgin如此,而是解决了那时、那个场景的那个需求。一旦了解后,就会感觉在和设计者对话,了解他们的思路,学习他们的方法,思维同屏:活到老学到老。

问题思考
1、Consumer Queue Offset是连续的吗, 为什么?
2、Commit Log Offset是连续的吗, 为什么?
3、Java写的文件,默认是大端序还是小端序,为什么?
Commit Log真实分布
在大家思考之际, 我们回想下commit log是怎么分布的呢?
在Broker配置的存储根目录下,通过查看Broker实际生成的commit log文件可以看到类似下面的数据文件分布:
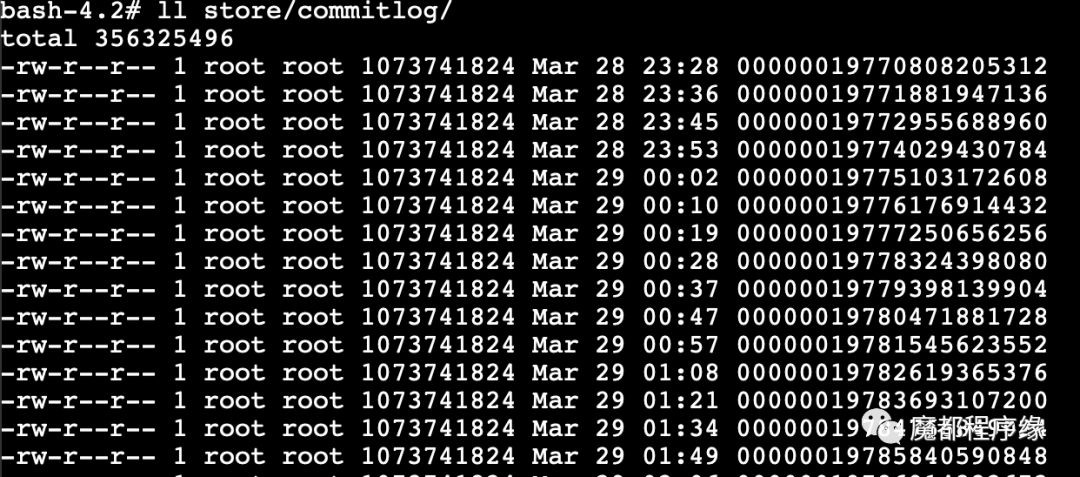
Broker真实数据文件存储分布
可以看到,真实的存储文件有多个, 每一个都是以一串类似数字的字符串作为文件名的,并且大小1G。
我们结合源码可以知道,实际的抽象模型如下:
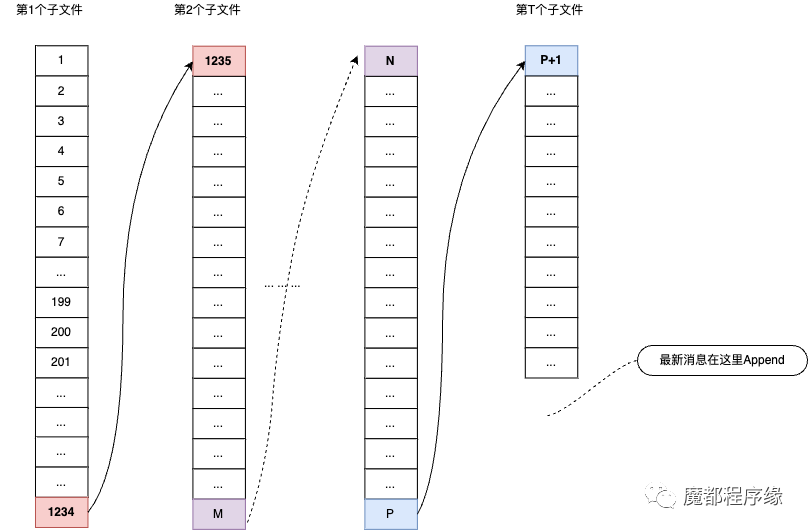
Commit Log存储文件分布抽象
由上图得知:
Commit Log是一类文件的称呼,实际上Commit Log文件有很多个, 每一个都可以称为Commit Log文件。如图中表示了总共有T个Commit Log文件,他们按照由过去到现在的创建时间排列。
每个Commit Log文件都保存消息, 并且是按照消息的写入顺序保存的,并且总是在写创建时间最大的文件,并且同一个时刻只能有一个线程在写。如图中第1个文件,1,2,3,4...表示这个文件的第几个消息,可以看到第1234个消息是第1个Commit Log文件的最后一个消息,第1235个消息是第2个Commit Log的第1个消息。
说明1:每个Commit Log文件里的全部消息实际占用的存储空间大小<=1G。这个问题大家自行思考下原因。
说明2:每次写Commit Log时, RocketMQ都会加锁,代码片段见 https://github.com/apache/rocketmq/blob/7676cd9366a3297925deabcf27bb590e34648645/store/src/main/java/org/apache/rocketmq/store/CommitLog.java#L676-L722

append加锁
我们看到Commit Log文件中有很多个消息,按照既定的协议存储的,那具体协议是什么呢, 你是怎么知道的呢?
Commit Log存储协议
关于Commit Log存储协议,我们问了下ChatGPT, 它是这么回复我的,虽然不对,但是这个回复格式和说明已经非常接近答案了。
ChatGPT回复
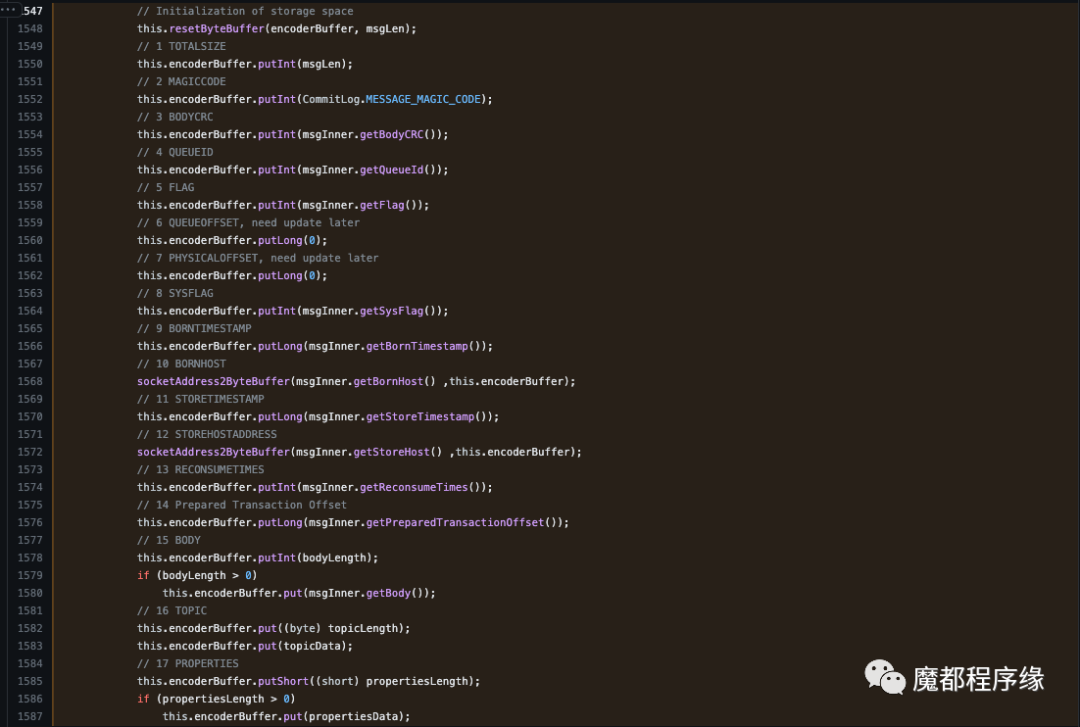
Commit Log存储协议
我整理后, 如下图:
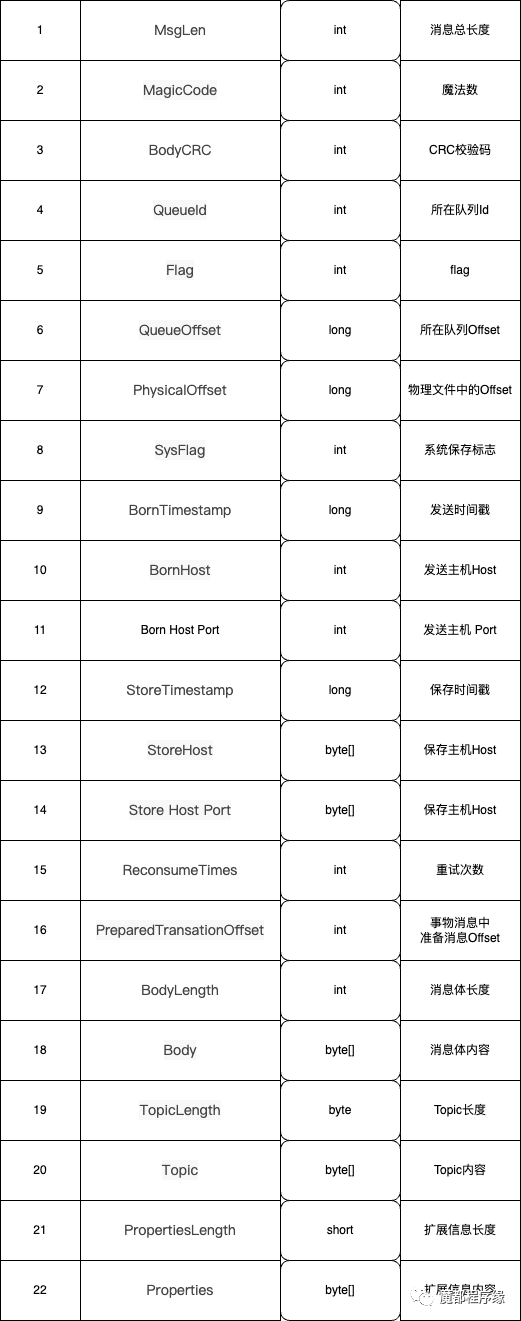
我理解的Commit Log存储协议
说明1:我整理后的消息协议编号和代码中不是一致的,代码中只是标明了顺序, 真实物理文件中的存储协议会更详细。
说明2:在我写的《RocketMQ分布式消息中间件:核心原理与最佳实践》中,这个图缺少了Body内容,这里加了,也更详细的补充了其他数据。
这里有几个问题需要说明下:
1、二进制协议存在字节序,也就是常说的大端、小端。大小端这里不详细说明感兴趣的同学自己google或者问题ChatGPT,回答肯定比我说的好。
2、在java中, 一个byte占用1个字节,1个int占用4个字节,1个short占用2个字节,1个long占用8个字节。
3、Host的编码并不是简单的把IP:Port作为字符串直接转化为byte数组,而是每个数字当作byte依次编码。在下一节的Golang代码中会说明。
4、扩展信息的编码中,使用了不可见字符作为分割,所以扩展字段key-value中不能包含那2个不可见字符。具体是哪2个,大家找找?
我们看到这个协议后,如何证明你的物理文件就是按照这个协议写的呢?
用Golang解开RocketMQ Commit Log
RocketMQ是用java写的,根据上文描述的存储协议,我用Golang编写了一个工具,可以解开Commit Log和Cosumer Queue,代码地址:https://github.com/rmq-plus-plus/rocketmq-decoder。
这个工具目前支持2个功能:
1、指定Commit Log位点,直接解析Commit Log中的消息,并且打印。
2、指定消费位点,先解析Consumer Queue,得到Commit Log Offset后,再根据Commit Log Offset直接解析Commit Log,并且打印。
在Golang中没有依赖RocketMQ的任何代码,纯粹是依靠协议解码。

golang-import
这里贴了一段golang中解析Commit Log Offset的例子:在java中这个offset是一个long类型,占用8个字节。
在golang中,读取8个字节长度的数据,并且按照大端序解码为int64,就可以得到正常的Commit Log Offset。
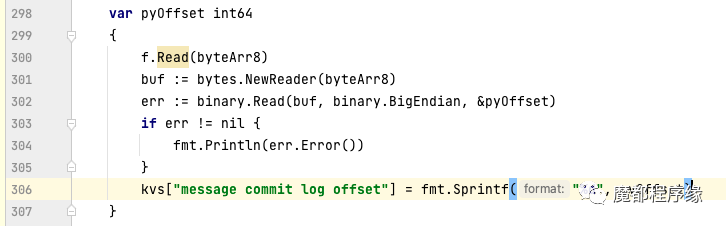
Golang-demo
我跑了一个demo结果,大家参考:
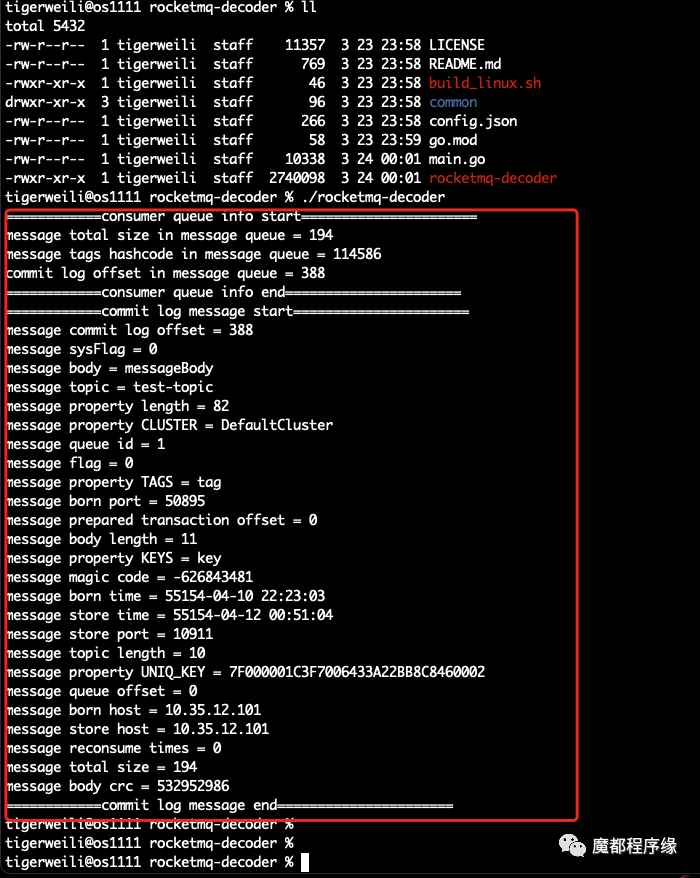
读取consumer-queue-commit-log
回答最初的问题
以下为个人见解,大家参考:
1、Consumer Queue Offset是连续的吗, 为什么?
是连续的。
consumer queue offset,是指每个queue中索引消息的下标,下标当然是连续的。消费者也是利用了这个连续性,避免消费位点提交空洞的。
每个索引消息占用相同空间,都是20字节,结构如下:
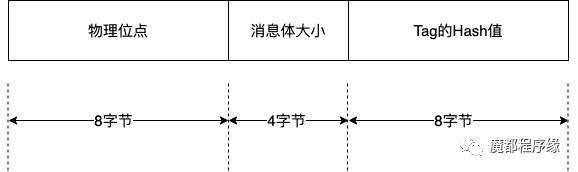
consumer-queue索引消息结构
这里物理位点也就是Commit Log Offset。
2、Commit Log Offset是连续的吗, 为什么?
不是连续的。
Commit Log Offset是指的每个消息在全部Commit Log文件中的字节偏移量, 每个消息的大小是不确定的,所以Commit Log Offset,也即是字节偏移量肯定是不一样的。
并且可以知道,每两个偏移量的差的绝对值就是前一个消息的消息字节数总长度。
并且上文中图 “Commit Log存储文件分布抽象”中的有误解,每个小方格的大小其实是不一样的。
3、Java写的文件,默认是大端序还是小端序,为什么?
大端序。大端序其实有字节存储顺序和网络传输顺序,java中默认用的大端序,保持和网络传输一样,这样方便编解码。
每段网络传输层的数据报文最前面的字节是表达后面的数据是用什么协议传输的,这样数据接收者在接受数据时, 按照字节顺序,先解析协议,再根据协议解码后面的字节序列,符合人类思考和解决问题的方式。
讨论说明:由于RocketMQ一些版本可能有差异,本文在4.9.3版本下讨论,大家可以参考这个方法,解开5.0甚至其他版本,其他数据文件的存储协议格式。
往期
推荐

扫描下方二维码关注本公众号,
了解更多微服务、消息队列的相关信息!
解锁超多鹅厂周边!

戳原文,查看更多
消息队列 RocketMQ 版的信息!

点个在看你最好看





