


导语|不要望文生义、不要似是而非、不要以偏概全。AIGC发展到什么地步
了?一个产品经理能用它做到什么地步?这里用个人实践告诉大家。
本文作者:alanxrhuang,腾讯PCG产品经理
前言
本文是AI绘图篇,文中图片基本为本人操作生成。
AI绘图现主流是两派:高完成度且商业化的Midjourney(大部分AI头像来源),开源的Stable Diffusion(大部分的AI绘图工具基于它搭建)。
二者底层原理是一样的,只是呈现到用户的应用层交互、交付不同。
1、底层原理
AI绘画是一种拼凑吗?如你认为AI做到的只是类似“把A画的鼻子、B画的嘴巴…排列组合成一个人”这种拼凑,那可以肯定地说:不是。
AI绘画的底层原理是扩散模型——AI通过学习现有作品的“清晰<->模糊<->文本”阶段_( 实际更复杂)_,反向学会凭文/图就能进行“画面想象”。当让它画一个人时,它的想象顺序如下:
想象一个人的轮廓-》想象模糊图像-》想象更多细节..-》完成想象

引用一个苏剑林老师的比喻帮助大家理解:
我们可以将扩散过程想象为建楼,其中随机噪声是砖瓦水泥等原材料,样本数据是高楼大厦,所以生成模型就是一支用原材料建设高楼大厦的施工队。这个过程肯定很难的,但俗话说“破坏容易建设难”,建楼你不会,拆楼你总会了吧?
我们考虑将高楼大厦一步步地拆为砖瓦水泥的过程,当我们有了“拆楼”的中间过程x0,x1,,,,xT后,我们知道拆楼的每一步是如何完成的,那反过来不就是建楼的一步?如果我们能学会两者之间的变换关系,那么从xT出发,反复地执行一步建楼的过程,最终不就能造出高楼大厦x0出来了。
2、基本应用
0和1两个数,可排列组合成各式各样的程序。万物无论大尺度还是小尺度看,都有它的基本组成单元。
AI绘画应用层面上的基础单元是什么?文本和图片、图片和图片之间关联
1)文生图
你可通过几个prompt(关键词)+模型就生成出来一张图片,当有更定制化的需求(如让她看向观众),只需改下prompt就能达成:

2)图生图
你可以给出一张图片 or 某张图片的seed,加上文本_(非必要)描述生成出这张图片的变种(是的,人民群众最爱的头像制作)。_这里用刘亦菲的鲜花头像尝试生成新的头像:

同时,图生图有个基础的应用是,将模糊的图片变得更加清晰、局部改图(如只改掉刘亦菲的脸,其它地方不改),此类应用并不新鲜,不在此展开。
3、基础应用 - 持续改进
1)文本理解:使用更自然的语言,而不是prompt
“十年以后,全世界有50%工作会是提示词工程(prompt engineering),不会写提示词(prompt)的人会被淘汰。”=》个人反驳:prompt是新技术出现的阶段性特定产物,也可能很快被自然语言淘汰。
现在已经可以通过自然语言生成prompt _(如通过GPT)或 直接通过自然语言生成图片。如只需用“a woman holding a bouquet of pink roses in her hands and looking at the camera with a serious look on her face”_这段话,也能生成如下效果:

此时问题来了:写一个prompt 或 一段话也太麻烦,能不能用一张类似的图片直接提取出来参考?=》可以的,上面那段话就是通过现有技术拿刘亦菲头像生成出来的文字,一字不改。

2)图片(模型):更高质量、更自定义
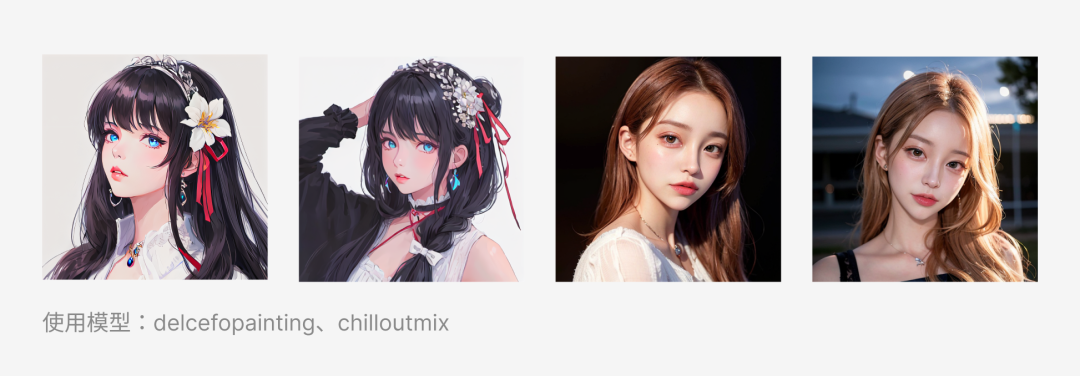
去年10~12月时的ai绘画模型质量参差不齐,如今模型质量已突飞猛进。除质量提升,你甚至可以用很低的成本(几张图)就DIY出一个属于自己的模型,该模型可生成出相当稳定的、特色效果。以下是一个网友们DIY的几个热门模型:

只需下载下来,通过简单的prompt,就能生成跟它相近的效果:
3、进阶应用
1)无限扩大图片(Infinity)
“无限扩图”是在“图生图”基础上演变出来有趣的应用——你可圈定一张图+空白区域,让AI填充空白,以此重复生成一张无限大的图片:

上图就是我把梵高的《阿尔夜间的露天咖啡座》不断补全,补出一张《阿尔夜间的长街》过程和结果图,效果还是高于预期的。
2)精确控制图片(Controlnet)
想要一个人物就按照我指定的姿势出现,用文字 or 图片怎么描述都不精准,怎么办?Controlnet满足你,只需通过一张图可反向生成骨架、手势等图,再将这些图结合模型,就能生成出一样动作的人物图片:

3)连续的N张图片=视频(Mov 2 Mov)
众所周知,一个视频是由很多帧图片组成。那么如果把一个视频的每一帧图片都用上图生图,不就可以用视频生视频?=》是的,你可以这么做到。以下中间视频是我基于上半部分视频+prompt一次性生成的效果:
同理是否可以文字生成出视频?毫无疑问,现如Runway、Google的Dreamix等产品已实现类似效果。
4)三视图+3D底模=3D模型
如题,AI绘图是否可生成一个角色的三视图,这样我就可以用该三视图通过一些工具转化为3D模型呢?可以的,通过prompt就能达成,如下:

4、与工具的结合
你现在可以直接在Photoshop等越来越多工具增加插件调用 或 直接调用AI绘画 能力。所使用的能力与上述没太大差别,更多的是场景结合带来了工作流效率提升,就不在此展开了。
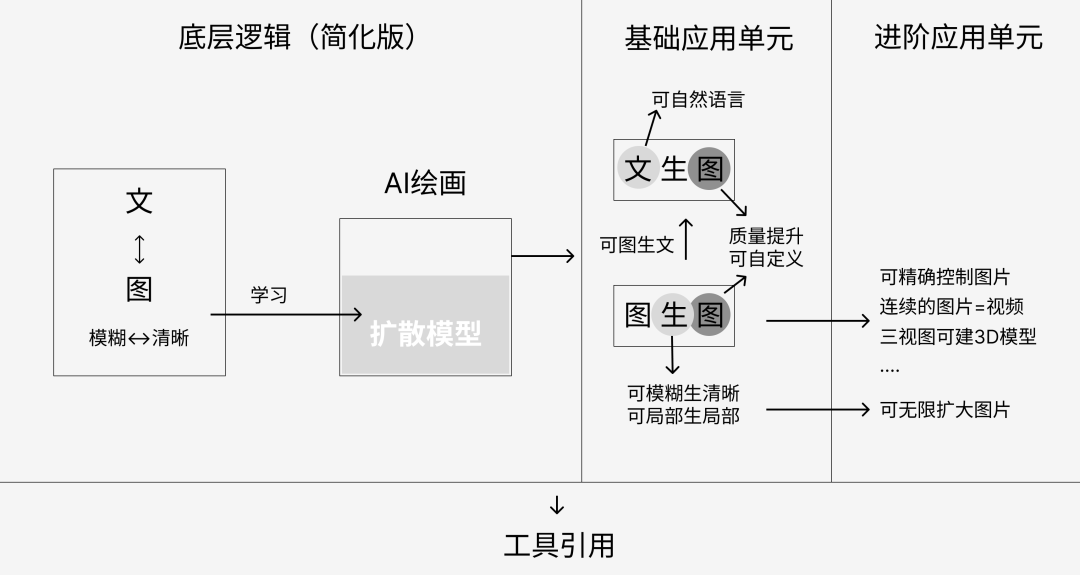
5、总结:一张图说明
用抽象的一张图总结上面1-4的内容:
6、尾言
此时应该开始瞎**畅想一番,但说实话人类最不缺乏瞎想,就不展开了。你与我能想象到的没有什么不同,从物质角度上来说只是消费了一点能量在脑海构造了几个画面,然后呢?由别人的想象带来的焦虑更是毫无意义。
可能有意义的是你我新增长了一点真实的知识 or 你我参与其中一步步把想象变成为了现实。共勉!
— — 技术直播预告 — —
技术科普对谈栏目,《技术人说》开播啦!
每期节目将以一个技术话题为核心,展开思维的碰撞。
来直播间,听技术科普、和嘉宾对谈,技术也没那么难~

本周三晚,直播间见👇
往期回顾:





