



《E往无前》系列将着重展现腾讯云ES在持续深入优化客户所关心的「省!快!稳!」诉求,能够在低成本的同时兼顾高可用、高性能、高稳定等特性,可以满足微盟、小红书、微信支付等内外部大客户的核心场景需求。
E往无前 | 人人在用的微信支付,腾讯云大数据ES如何让它低成本高可用?
导语:微信支付是国家重要的关键信息基础设施,服务于几千万商户和上亿国民,可用性要求高于5个9。本案例重点介绍了ES在微信支付服务中满足金融账单数据需求的同时,如何进一步降低成本,提高可用性。
Elasticsearch(下文简称为ES)经常用来保存大量带有时间属性的数据,例如:系统监控数据,股票交易数据,用户账单。可以利用ES丰富的组合查询,统计功能来分析这些数据。这类数据除了都有时间字段之外,还各有自身的特点。例如:股票交易数据产生后不会被修改,监控数据除了不会修改之外,还可以通过只保留统计值(降低老数据的精度)来降低存储成本。它们的不可修改性、可降低精度特点都是系统优化的入口。而用户账单既要全量保存(不可降精度),又要支持修改,这些功能要求对系统的低成本、高可用性目标带来了挑战。本文主要讨论的对象是可修改的全量账单数据,如何降低它的使用成本和提高它的查询可用性。
1、ES的标准低成本方案是什么
1.1、热温冷架构
当ES中保存带有时间属性的数据时,通常都会考虑热温冷架构,这也是社区推荐的低成本方案。
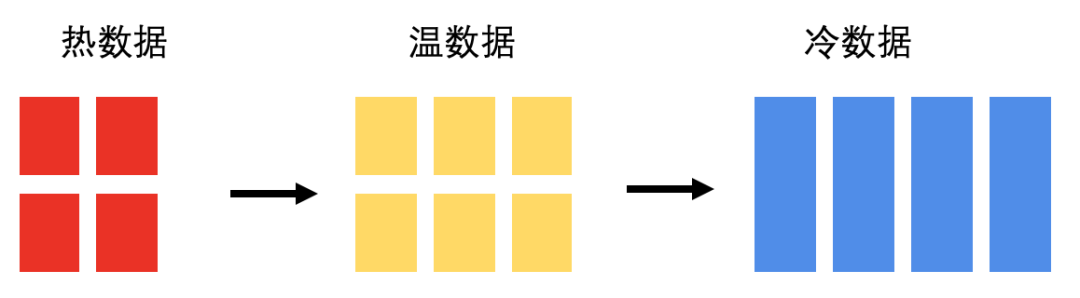
首先我们需要了解下经典热、温、冷区的定义:
- 热区: 负责保存最新的数据,承担所有数据入库负载,同时最新的数据被使用的概率也最高,所以也会处理频繁的查询请求。
- 温区: 当一个Index表的数据增长到一定的容量,或是已经保存了特定一段时间后,会将它转移到温区数据节点,温区数据是只读的,也就是不会处理数据入库和更新的请求。温区中的数据也没有热区里那么新,被查询的频率也会降低。
- 冷区: 当一个Index表的数据经过一段较长的时间,使用频率变得很低,会将它转移到冷区数据节点,并且针对这些数据做 Freeze 处理(下面会介绍),这时数据以最节省系统资源的状态被保存,还是可以提供查询服务,但是速度比较慢。
我们可以看到,从热区到冷区,数据处理的负载越来越低,数据量越来越大,这是一个降低成本的切入点。那么ES是怎么做的呢?
1.2、利用数据只读降低内存消耗,从而保存更多的数据
热区数据的写入、查询负载最高,其中的数据节点使用高配置硬件,特别配置了ssd,这也是ES通常推荐的高性能配置。而温区不处理数据写入,只服务不多的数据查询,那么温区的主要困难便是如何平稳的管理大容量不热的数据,数据容量越大成本越低。考虑到数据的部分索引是需要加载到内存中,那么温区数据节点的内存和数据量的比例就成为了一个降成本的指标。我们详细分析下内存的使用,ES的堆内存都保存了哪些内容呢?
- Node query cache 节点查询缓存,默认使用10%的堆内存空间,Node query cache 用来缓存 Term 查询 和 filter 查询,从而加速相同条件的后续查询。
- Indexing buffer 索引缓冲区,默认使用10%的堆内存空间。Indexing buffer 用于存储最新被索引的数据,当 indexing buffer 被填满后,缓存的数据将被写入磁盘的 segment 中。此内存用来提高数据入库构建索引的性能。
- Shard request cache 分片请求缓存,默认使用1%的堆内存空间。用来加速 aggregations 和 suggestions 查询。
- Field data cache 字段数据缓存,正排索引缓存。
- Segment Memory,将数据的部分索引(如FST)加载到内存中,从而加速查询和数据入库的过程。
根据前面的分析可以得知,温区数据节点挂载更多数据而降成本的关键措施为:
- 温区数据无写入,这样能够完全去掉写入相关的内存消耗,包括上面提到的 Indexing buffer,
- 温区数据只有少量读,只需要提供有限的查询服务,这样能够降低、甚至去掉上述各种查询缓存。
经过上面的分析,温区数据只需要留下直接与数据量相关的 Segment Memory。这样温区数据节点就能够保存更多的数据。换句话说,当温区数据节点使用与热区数据节点相同cpu/mem配置时可以挂载更多的数据,从此应用需求出发,可以得知温区数据节点通常使用高容量,较低性能的sata机械盘,降低温数据的保存成本。
1.3、接受更长的查询时间来进一步降低内存消耗,从而挂载更多的数据
通过前面的分析,我们了解到温区数据的主要内存消耗是 Segment Memory,它与节点上保存的数据量正相关。能否进一步减少它的使用量呢?一个可能的解决方案是关闭索引。如果我们关闭一个索引,就释放了它占用的内存,但需要搜索时又要重新打开它。重新打开索引将带来较长的操作时间,业务是否能够接收呢?另外,此操作也引入管理上的复杂性,还需要及时关闭索引,否则它会继续使用堆内存。社区沿着这个思路做出一个更平滑的节省内存方案,引入了 Freeze Indices 的数据保存方式。当我们冻结一个索引时,它变成只读的,它所占用的内存被释放。反过来,当我们对冻结的索引运行查询时,再零时将数据结构加载到内存中。通过降低查询性能来节省内存,从而挂载更多的数据。
ces在这个方向上进行了极致优化,将sata盘进一步替换成对象存储,进一步降低存储成本,同时也优化了性能问题。
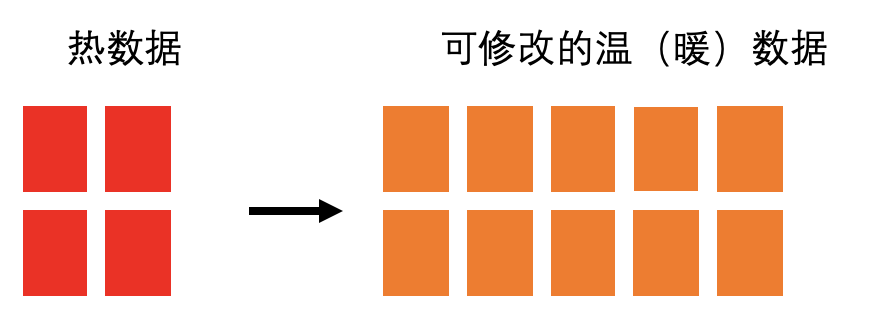
2、用户账单需要热+(可修改的)温架构
用户账单有时间属性,但并没有随着时间的流逝降低对用户的服务质量。多年以前的历史账单仍然支持用户做修改,仍然提供分类查询能力,还要保持秒级查询响应。而ES经典热温冷架构假设历史数据是不可修改的,只提供很慢的少量查询能力。如果要将历史账单映射到前面的经典热温冷架构的话,需要做些调整,可以称历史账单为可修改的温数据。一旦温数据可修改,前述的各种数据只读带来节省内存的方案都无法应用。而秒级查询也导致 Segment Memory 无法卸载。看起来我们面对的是一种温度很高的温数据,也许可以叫做暖数据。低成本,高可用的难点就集中在了可修改的温数据上。
3、保障日常高可用,探索低成本
我们需要在达成性能、可用性目标的前提下,讨论低成本。同样规格的1个节点,挂载的数据越多,成本就越低。根据测算,一个24核,128GB的温节点可以挂载20TB的sata盘,按照75%的使用率,可以装到15TB。刚开始的时候一切都正常,随着温节点上数据越装越多,事情开始有了变化。
3.1 问题:大容量温节点导致控制命令失效,监控失效
当温节点装载4TB数据时,集群可以正常的工作;当温节点装载到10TB数据时集群开始出现各种不稳定现象:
- 监控超时、失效,导致告警延迟,甚至失效。最终导致故障不能被及时发现。
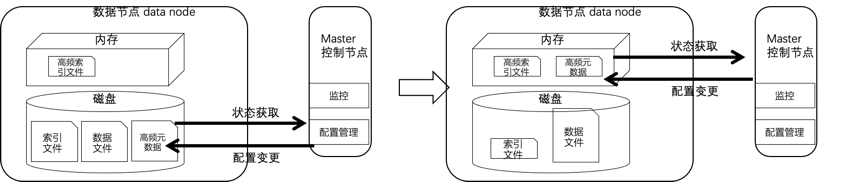
master无法在规定周期内收集到集群监控数据

从kibana上看到监控图断断续续,和后台的监控超时日志相对应。
- 管控命令下发超时,集群控制失效,影响日常变更,降低系统信心。
master不能在规定周期内下发集群配置变更

我们已经触碰了可修改温数据的单节点容量上限了吗?
3.2、原因:大容量数据对节点内状态管理提出了挑战
- cpu占用率持续高,与温节点较低的业务查询和修改量不相符
- 节点垃圾回收频繁,负载重,与业务量不相符


- 节点收集自身状态超时

节点收集自身状态超时是一个关键点。我们重点分析了ES/lucene内部的状态管理逻辑,结合内存分析,找到了lucene的热点代码,lucene在评估节点数据容量和数据占用内存时消耗了大量资源。相关方法为:RamUsageEstimator#shallowSizeOfInstance和FSDirectory#fileLength。

3.3、方案:利用LSM的不变性优化内核
根据前面的分析,可以了解到lucene在评估数据容量和数据占用内存时的消耗与节点上数据总量正相关。这也能解释随着数据量的不断增多,问题恶化的现象。那么方案是什么呢?
lucene是一种类LSM-Tree的结构,LSM-Tree全称是Log Structured Merge Tree,是一种分层,有序,面向磁盘的数据结构,其核心思想是充分利用磁盘批量的顺序写远优于随机写性能。底层数据全部以Append的模式追加,不存在删除和修改。业务概念上的删除和修改通过append 相同key的数据来实现。
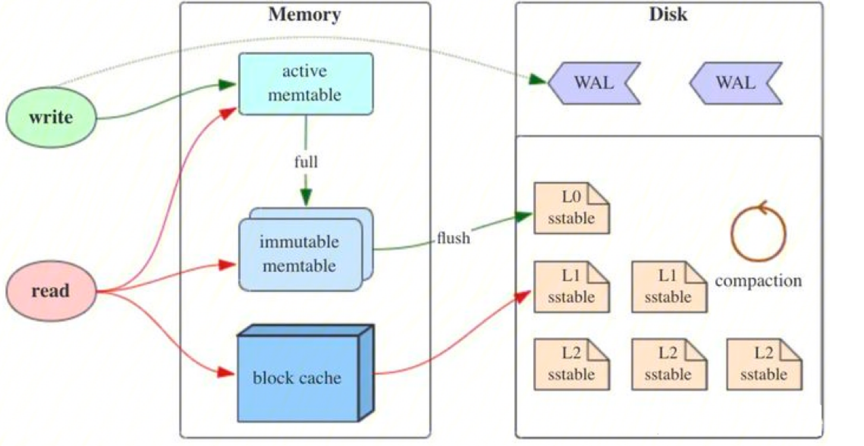
LSM-Tree主要由三部分构成: MemTable,Immutable MemTable,SSTable(Sorted String Table)
-
MemTable,是在内存中的数据结构,用于保存最近更新的数据,
-
Immutable MemTable,当 MemTable达到一定大小后,会转化成Immutable MemTable。Immutable MemTable是将转MemTable变为SSTable的一种中间状态。写操作由新的MemTable处理,在转存过程中不阻塞数据更新操作。
-
SSTable(Sorted String Table),是LSM树在磁盘中的数据结构。文件是不可变的。
lucene是一种类LSM-Tree的结构, 区别在于内存中的数据(对应Mem Table)是不可搜索的。磁盘上的文件称之为Segment(对应SSTable)也是不可变的。我们是否能够利用LSM的不可变性,加速内核中的状态管理?给出方案的如下目标:
- 缓存高频元数据。由segment文件的不可变性可知,缓存value不需要更新。
- 控制缓存的规模。merge操作产生新segment的同时还会删除源文件,需要过期删除文件对应的缓存key,从而释放内存。
- 利用缓存加速状态管理。当大数据量节点收集自身状态时,能够直接利用缓存的元数据,秒级完成状态收集,快速上报到控制节点。同时加速控制节点的集群内配置变更。最终解决监控超时失效,集群控制失效的问题。
3.4、效果:大容量节点冷静如初,集群管控迅速
与之前相比,系统负载降到原来的1/4,GC较少发生。状态收集代价很小,监控不再超时,做到了10s的上报精度。配置变更也很顺畅。另外:此时温节点已经装载了15TB的数据。因为此优化的落地,我们也有信心在温节点上装入更多的数据,开始考虑启用更高的压缩比。传送门:Lucene索引引擎的压缩编码优化


4、保障变更高可用,降低变更对查询超时的影响
4.1、问题:数据从热区下沉到温区过程中产生大量查询超时
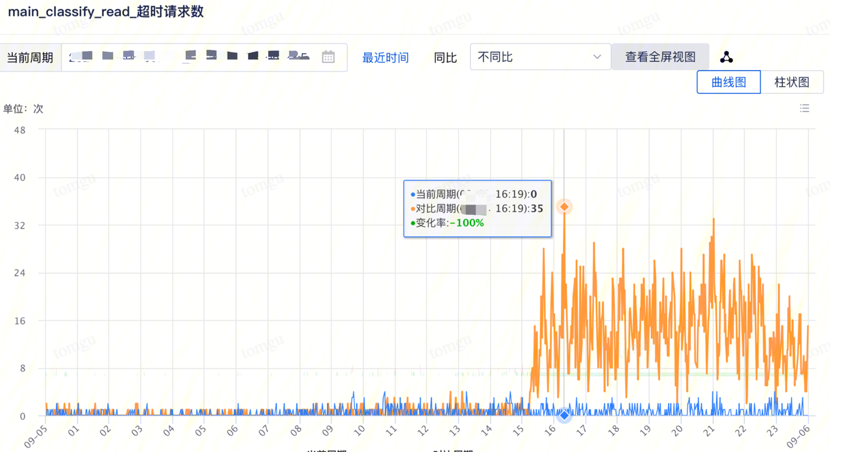
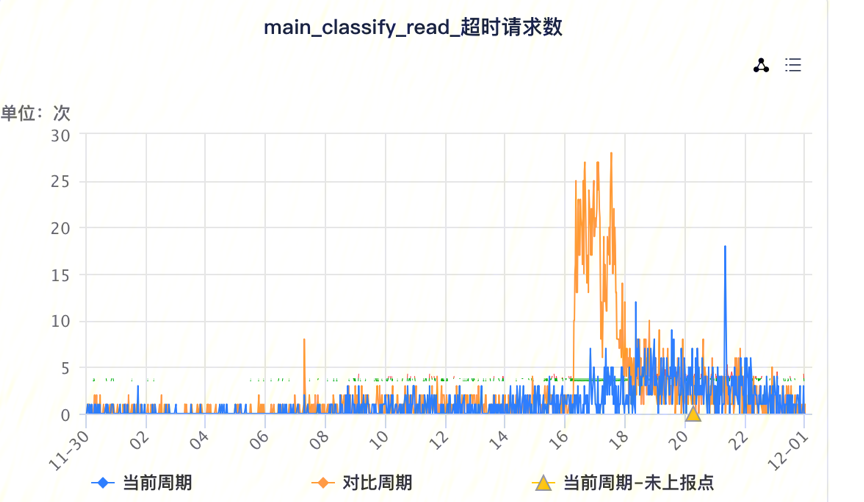
数据从热区搬迁到温区期间,用户检索记录超时数是日常超时数的几十倍! 黄线:搬迁期间的用户查询超时数,蓝线:日常用户查询超时数。能否完全消除数据搬迁对用户查询的影响?
4.2、原因:磁盘IO冲突导致用户查询超时
数据搬迁时产生持续的、大量的磁盘读写IO。如果用户检索请求落在参与数据搬迁的磁盘上,检索请求不能被快速处理,响应超时

而温区的sata盘是矛盾的焦点,承担了1/10的负载(业务场景数据),只有1/500的性能(与ssd相比)。ssd性能富余也是方案的一个利用点。
| Header | iops规格 | iops规格之比 | io负载之比 |
|---|---|---|---|
| sata | 203① | 1 | 1 |
| ssd | 111500② | 500 | 10 |
4.3、方案:防守反击
针对IO冲突,给出下面两个方案
- 防守,使用ES自带的自适应查询功能,根据节点的历史查询质量选择下一次查询的目的地。利用此统计数据,在后面的查询中绕开查询质量差的节点。
- 反击,查询IO隔离,规划预测数据下沉的顺序、路径,提前一步将相关节点从查询路由中剔除,完全避免IO冲突,避免查询超时。
4.3.1-自适应查询消减查询超时
此特性源于一篇paper,C3: Cutting Tail Latency in Cloud Data Stores via Adaptive Replica Selection,最初,这是Cassandra的一个特性,后来被引入ES6.1版本。它的基本原理如下:每次处理查询请求前,ES会对数据的多个副本(通常是3副本)质量进行评估,选出最健康的副本,然后发出查询请求。质量评估的公式如下:
Ψ(s) = R(s) - 1/µ̄(s) + (q̂(s))^3 / µ̄(s)
概括来说就是考虑下面三个因素,对节点质量进行评估:
- 协调节点与数据节点之间的先前请求的响应时间
- 数据节点执行先前搜索所花费的时间
- 数据节点的搜索线程池的队列大小
我们可以看出自适应查询在这个场景下的不足之处
- 数据三副本所在节点质量都差
三副本质量都差,自适应查询也会无米可炊,无健康节点可选。
那么三副本所在节点质量都差的概率有多少呢?我们很容易想到正在被搬迁的分片首先受到影响,但容易被忽略的一点是,搬迁分片的源磁盘、目的磁盘上面的其他分片也都受到了影响。以标准3.4TB磁盘为例,至少存储60个40GB的分片,如果并发10个分片下沉,受影响的分片将会是60X10X2=1200个。覆盖3副本的概率很大。
- 试错成本,节点的历史质量数据通过试错产生
公式的正常运作依赖于历史的查询质量数据,只有查询超时后才能指导后续的查询路由。同时,还需要考虑到曾经的质量差节点也会变好,还需要周期性消耗一些查询(新的慢查询)来更新它的最新质量数据。
4.3.2-查询IO隔离,避免查询超时
基于自适应查询的弱项,可以采用下面措施解决问题
- 三副本质量都差
规划预测数据下沉的顺序、路径,使任一时刻参与下沉的一批磁盘上的所有分片不会覆盖任一块数据的三副本。 - 试错成本
改造ES内核的路由逻辑,提前一步将相关节点从查询路由中剔除,不路由任一条查询到繁忙的节点,不产生超时请求,消除试错成本。
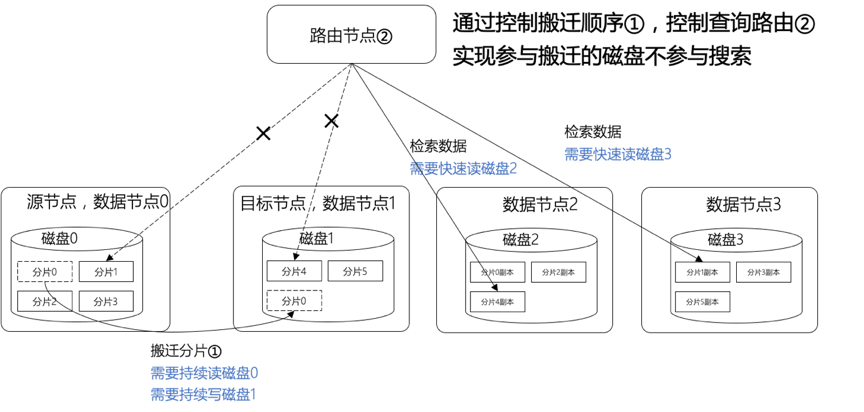
完善的方案还需要考虑下面几个目标
- 数据一致性
我们只从查询路由中拿掉了相关节点,但这些节点仍然参与数据写,保障副本之间的一致性。 - 减小搬迁性能的下降
IO隔离保障数据检索时延的同时,会降低搬迁的并行度,导致更长的搬迁时间,降低搬迁性能。需要控制性能的损失。前面分析的ssd与sata盘性能差异是一个性能提升的切入点。 - 故障适应性
如果在数据下沉期间,集群有节点故障,部分数据的3副本变成了2副本,甚至只留了1个完整副本,这时的IO隔离不能让无数据可查。
4.4、效果:数据下沉期间产生的查询超时数很大的减少
蓝线为在IO隔离情况下,操作数据下沉产生的超时数,期间超时数基本与背景超时数相当。
给ES增加的查询io隔离可以应用在下面场景
- 数据搬迁,包括:数据下沉,数据均衡,节点裁撤场景
- 节点滚动重启
节点滚动重启是一个容易忽视的应用场景,节点重启后,需要从本地恢复大量shard,正在恢复的shard虽然不会对外提供查询服务,但与此shard共享同一块磁盘的其他已恢复shard会对外提供查询服务,此时会发生磁盘IO冲突,也可以应用查询io隔离特性,降低、消除期间的查询超时。
ES有奖征文活动
征文活动火爆ING🔥
活动详情请戳👇

只要是与【Elasticsearch Service】相关的技术产品干货内容,都可以参加此次活动,参与活动即可获得腾讯云 X Elasticsearch联名精美周边礼品,Apple Watch、Cherry机械键盘、京东卡等超级丰厚大礼 等你来拿~扫码加群了解活动详情:

免费体验活动专区
Elasticsearch 新用户可享 2核4G,0元 体验 30 天!顺畅体验云上集群

推荐阅读



关注腾讯云大数据公众号
邀您探索数据的无限可能

点击“阅读原文”,了解相关产品最新动态
↓↓↓





