



作者:monychen,腾讯 IEG 应用研究员
简单来说,ChatGPT 是自然语言处理(NLP)和强化学习(RL)的一次成功结合,考虑到读者可能只熟悉其中一个方向或者两个方向都不太熟悉,本文会将 ChatGPT 涉及到的所有知识点尽可能通俗易懂的方式展现出来,有基础的同学可以选择性跳过一些内容。
GPT 的进化史
本节的主要目的是介绍自然语言处理中语言模型的一些基础知识,理解语言模型到底在做什么。
GPT
所谓的 GPT(Generative Pre-trained Transformer),其实是 Generative Pre Training of a language model(语言模型)。那什么是语言模型呢?可以简单地把语言模型理解为“给定一些字或者词,预测下一个字或者词的模型”,这里的字或者词在 NLP 领域通常也被称为 token,即给定已有 token,预测下一个 token 的模型,这里举个例子,我们在搜索引擎里进行搜索时,自动会往后联想就是种语言模型的体现。

那么训练语言模型有什么优势呢?答案就是它不需要人工标注数据!
比如以“today is a good day”为例,它可以被拆解为:
| 训练数据 | 标签 |
|---|---|
| today | is |
| today is | a |
| today is a | good |
| today is a good | day |
接下来让我们来数学化地描述一下,给定一个句子,比如 ,语言模型其实就是想最大化:
其中 是考虑的窗口长度,条件概率 通过一个参数为 的神经网络来描述。
GPT 的神经网络采用了一个多层的 Transformer decoder,输入经过 embedding 层(token embedding 叠加 position embedding),然后过多层解码器,最后通过一个 position-wise 的前向网络得到输出的分布:
有了模型结构,有了目标函数,已经可以预训练一个大容量的语言模型了,这也就是 GPT 的第一阶段,在 GPT 的训练流程里还有第二个阶段,利用一些有标签数据进行微调。假设输入为 ,标签为 ,可以将输入喂入模型,模型的输出再叠加一个线性层作为最终的输出:
目标函数也就是:
然而作者在微调时还发现,同时考虑语言模型的自回归目标函数效果更好,也就是:
在微调阶段,可以优化的参数只有顶部的线性层已经用作分隔符的 token embedding。下图展示的就是 GPT 做微调时对文本的一些常见做法,其实就是拼接和加分割符之类的操作。

GPT2
GPT1 需要对特定任务再进行精调(依赖有标签数据进行监督学习),而 GPT2 则是考虑在预训练时考虑各种不同的任务,也就更加通用化。因此,GPT2 的模型从原本 GPT1 的:
改为 task conditioning 的形式:
也就是把任务也作为模型的输入,具体的做法是引入一些表示任务的 token,举几个例子。
- 自回归任务
input:Today is a
output:good - 翻译任务
input:Today is a [翻译为中文]
output:今天是一个 - 问答任务
input:我是小明 [问题] 我是谁 [答案]
output:小明
上面例子中 [翻译为中文]、[问题] 、[答案] 这些就是用于告诉模型执行什么任务的 token。
通过这样的方式,各种任务都能塞进预训练里进行了,想学的越多,模型的容量自然也需要更大,GPT2 的参数量达到了 1.5 Billions(GPT1 仅 117 Millions)。
GPT3
GPT3 可以理解为 GPT2 的升级版,使用了 45TB 的训练数据,拥有 175B 的参数量,真正诠释了什么叫暴力出奇迹。
GPT3 主要提出了两个概念:
- 情景(in-context)学习:就是对模型进行引导,教会它应当输出什么内容,比如翻译任务可以采用输入:请把以下英文翻译为中文:Today is a good day。这样模型就能够基于这一场景做出回答了,其实跟 GPT2 中不同任务的 token 有异曲同工之妙,只是表达更加完善、更加丰富了。
- Zero-shot, one-shot and few-shot:GPT3 打出的口号就是“告别微调的 GPT3”,它可以通过不使用一条样例的 Zero-shot、仅使用一条样例的 One-shot 和使用少量样例的 Few-shot 来完成推理任务。下面是对比微调模型和 GPT3 三种不同的样本推理形式图。
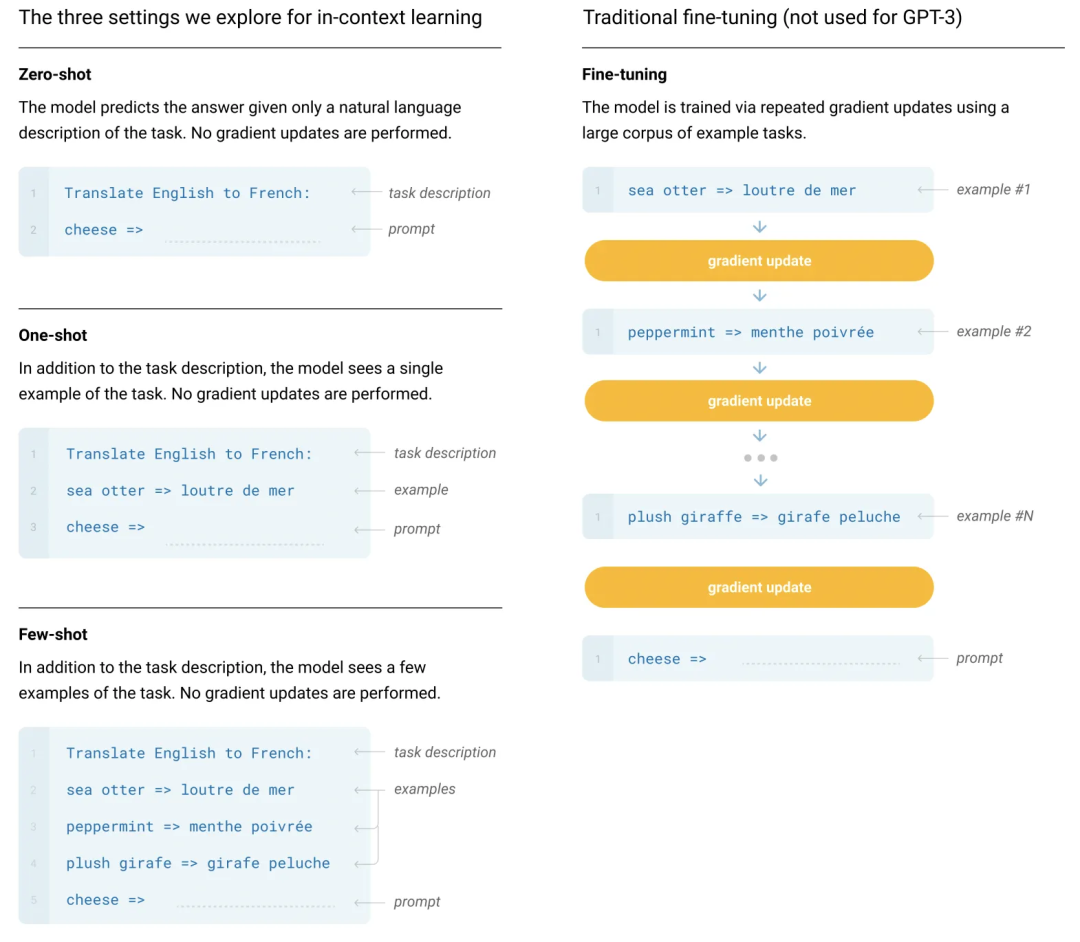
ChatGPT
ChatGPT 使用了类似 InstructGPT 的方式来训练模型,该方法也叫做 Learning from Human Feedback。主要分为三个步骤:
- 用有监督数据精调 GPT-3.5;
- 对于模型输出的候选结果(因为采样会导致同一输入有不同输出)进行打分,从而训练得到一个奖励模型;
- 使用这个奖励模型,用 PPO 算法来进一步对模型进行训练。
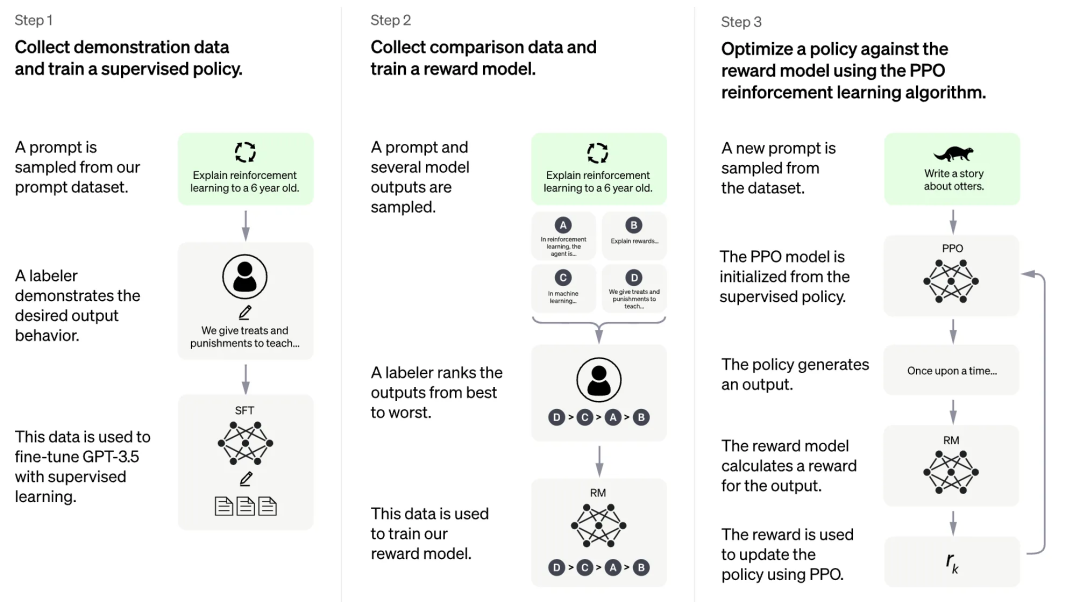
如何训练一个 GPT
接下来我们来动手实践一下如何训练一个 GPT 模型出来,这里以从头训练一个代码补全的 GPT 模型为例。
代码补全有什么用呢,比如我们给模型一个提示:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# build a BERT classifier
然后模型就能够输出:
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased')
帮我们定义了一个基于 Bert 的分类器出来。
为了训练这样一个模型,首先我们需要准备用于训练的数据,常见的代码补全的数据为 codeparrot。
https://huggingface.co/codeparrot/codeparrot
这里随便打印一条数据(截断了,不然太长了)出来看看,可以看到其实跟我们正常写的代码是一样的。

然而模型是不能直接接收这样的“文本”信息的,所以训练 NLP 模型前通常需要对其进行“分词”,转化为由一串数字表示,可以创建一个分词器:
tokenizer = AutoTokenizer.from_pretrained("./code-search-net-tokenizer")
对上面的代码进行分词转化,就可以得到如下的一串 id:
[3, 41082, 17023, 26, 11334, 13, 24, 41082, 173, 2745, 756, 173, 2745, 4397, 173, 2745, 1893, 173, 2745, 3857, 442, 2604, 173, 973, 7880, 978, 3399, 173, 973, 10888, 978, 4582, 173, 173, 973, 309, 65, 552, 978, 6336, 4391, 173, 295, 6472, 8, ...
上面的例子展示了对单条样本进行分词的结果;通常我们会把分词函数定义好(中间会涉及到比如需不需要截断、最大长度多少等细节配置这里就不详细展开了),然后直接对整个数据集进行 map 就可以对整个数据集进行分词了。
def tokenize(element):
outputs = tokenizer(
element["content"],
truncation=True,
max_length=context_length,
return_overflowing_tokens=True,
return_length=True,
)
input_batch = []
for length, input_ids in zip(outputs["length"], outputs["input_ids"]):
if length == context_length:
input_batch.append(input_ids)
return {"input_ids": input_batch}
tokenized_datasets = raw_datasets.map(
tokenize, batched=True, remove_columns=raw_datasets["train"].column_names
)
搞定数据后,接下来就需要创建(初始化)一个模型了,GPT 的结构其实就是由 transformer 组成的,网上的轮子已经很多了,这里就不重新造轮子了,最常见的直接用的 transformers 库,通过配置的方式就能够快速定义一个模型出来了。
from transformers import AutoTokenizer, GPT2LMHeadModel, AutoConfig
config = AutoConfig.from_pretrained(
"gpt2",
vocab_size=len(tokenizer),
n_ctx=context_length,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
model = GPT2LMHeadModel(config)
model_size = sum(t.numel() for t in model.parameters())
print(f"GPT-2 size: {model_size/1000**2:.1f}M parameters")
这是一个 124.2M 模型参数的 GPT2,模型的代码结构打给大家看看(详细的代码实现可以阅读 transformers 库的源码),其实主要就是前面有个 embedding 层,中间 12 个 transformer block,最后有个线性层。
GPT2LMHeadModel(
(transformer): GPT2Model(
(wte): Embedding(50000, 768)
(wpe): Embedding(1024, 768)
(drop): Dropout(p=0.1, inplace=False)
(h): ModuleList(
(0): GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
#################
中间省略重复的10层Block
#################
(11): GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=768, out_features=50000, bias=False)
)
这里也给出 GPT2 和 GPT 的模型结构图,感兴趣的同学可以仔细看看,可以发现,GPT2 的模型结构(右)较 GPT 的模型结构(左)有所改动。在 GPT2 中的一个 Transformer Block 层中,第一个 LayerNormalization 模块被移到了 Msaked-Multi-Self-Attention 模块之前, 第二个 LayerNormalization 模块也被移到了 Feed-Forward 模块之前;同时 Residual-connection 的位置也调整到了 Msaked-Multi-Self-Attention 模块与 Feed-Forward 模块之后。
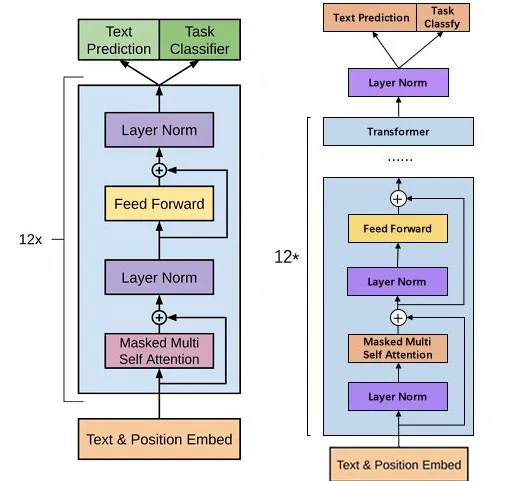
数据和模型结构都确定下来后,接下来我们需要有一个训练的流程或者框架,最简便的那就是直接调用 transformers 提供的训练器,给定一些配置,模型、分词器、数据集。
from transformers import Trainer, TrainingArguments
args = TrainingArguments(
output_dir="codeparrot-ds",
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
evaluation_strategy="steps",
eval_steps=5_000,
logging_steps=5_000,
gradient_accumulation_steps=8,
num_train_epochs=1,
weight_decay=0.1,
warmup_steps=1_000,
lr_scheduler_type="cosine",
learning_rate=5e-4,
save_steps=5_000,
fp16=True,
push_to_hub=True,
)
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=args,
data_collator=data_collator,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["valid"],
)
然后就可以一键训练了:
trainer.train()
自由度高一点的训练方式也可以自行打造,依次拿到每个 batch 数据、送入模型、计算 loss、反向传播;对于大模型来说,常见的用 accelerate 库来进行加速,比如混合精度、梯度累积等操作。
上述的这些代码(使用训练器或者 accelerate 库进行训练)在 transformers 的官方教程里都有,感兴趣的可以自己跑一跑哦。
https://huggingface.co/course/chapter7/6?fw=pt
训练完模型后我们可以来看一下它的代码生成能力,那就先来跟大家 hello world 一下。
给定 prompt:
def print_hello_world():
"""Print 'Hello World!'."""
得到:
def print_hello_world():
"""Print 'Hello World!'."""
print('Hello World!')
给定 prompt:
import numpy as
它知道我们常用的缩写就是:
import numpy as np
给定 prompt:
import numpy as np
from sklearn.ensemble import RandomForestClassifier
# create training data
X = np.random.randn(100, 100)
y = np.random.randint(0, 1, 100)
# setup train test split
它能够帮我们划分训练和测试数据集:
import numpy as np
from sklearn.ensemble import RandomForestClassifier
# create training data
X = np.random.randn(100, 100)
y = np.random.randint(0, 1, 100)
# setup train test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
这一节中我们走了一遍训练 GPT 的一个流程,这里和训练 ChatGPT 的第一步的差别在于:ChatGPT 第一步采用人工写答案的方式得到的语料对预训练好的 GPT 进行了精调,而本节只是对一个小语料进行了一波预训练。
这样做的目的也是易于理解的,毕竟直接拿网上的各种语料来做预训练,存在着很多脏数据。
如何训练一个奖励模型
接下来我们来看一下训练 ChatGPT 的第二步:
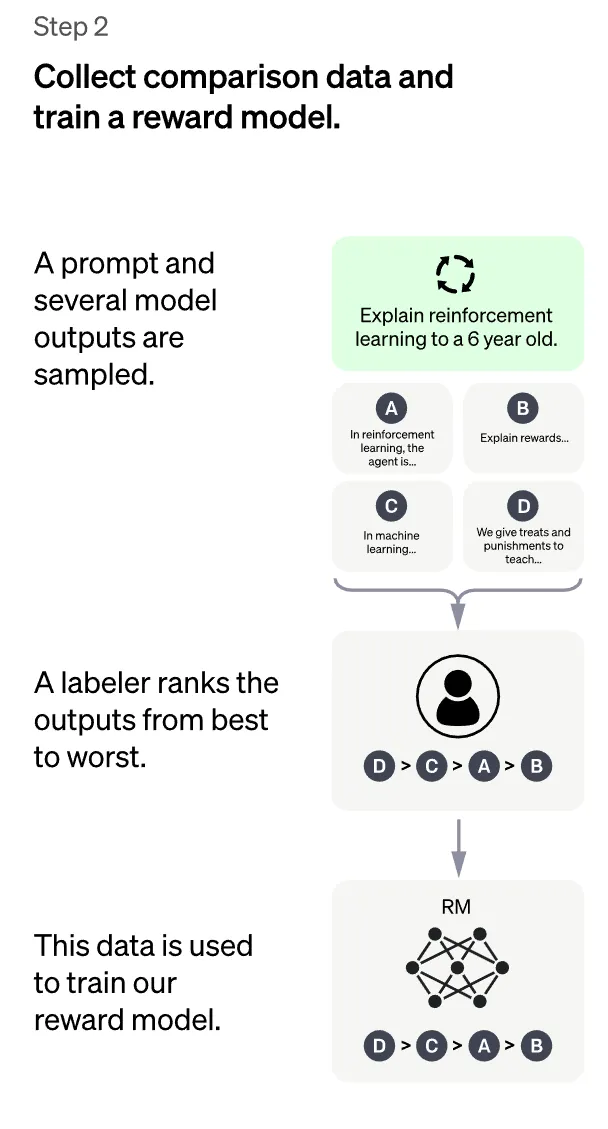
只能说“钞能力”真伟大,openai 直接请了一群人,给 GPT 生成的多个回答进行排序打分,然后再根据这个打分训练一个奖励模型(GPT 生成的结果越好,得分越高),有了这样一个模型后,就可以用来指导 GPT 生成尽可能高分的回答了。
没钱也没精力,但不妨碍我们学习如何训练一个奖励模型,奖励模型的学习本质就是一个句子分类或者回归的任务。
这里找一个数据集来展示一下整个流程,比如 IMDB 影评数据集,常用于情感分析,也就是给文本的情感打分,输入就是影评,输出就是得分(积极或消极对应 1 或 0),那就能训练一个奖励模型了(比如可以用来指导 GPT 生成得分越高,也就是更加积极的文本)。
首先导入一下数据集(下载链接:https://ai.stanford.edu/~amaas/data/sentiment/)
def read_imdb_split(split_dir):
split_dir = Path(split_dir)
texts = []
labels = []
for label_dir in ["pos", "neg"]:
for text_file in (split_dir/label_dir).iterdir():
texts.append(text_file.read_text(encoding='utf-8'))
labels.append(0 if label_dir is "neg" else 1)
return texts, labels
train_texts, train_labels = read_imdb_split("./DataSmall/aclImdb/train")
test_texts, test_labels = read_imdb_split("./DataSmall/aclImdb/test")
看一眼数据就是长这样,一段文本对应一个标签:

同样的我们需要对其进行分词,转为一串 id,定义分词器,并构造数据集:
print("Tokenizing train, validate, test text ")
tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-uncased')
train_encodings = tokenizer(train_texts, truncation=True, padding=True)
test_encodings = tokenizer(test_texts, truncation=True, padding=True)
class IMDbDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
print("Loading tokenized text into Pytorch Datasets ")
train_dataset = IMDbDataset(train_encodings, train_labels)
test_dataset = IMDbDataset(test_encodings, test_labels)
train_loader = DataLoader(train_dataset, batch_size=10, shuffle=True)
接下来定义一个用于预测得分的模型,以及优化器:
print("Loading pre-trained DistilBERT model ")
model = DistilBertForSequenceClassification.from_pretrained('distilbert-base-uncased')
model.to(device)
model.train()
optim = AdamW(model.parameters(), lr=5e-5)
接下来就可以开始模型的训练了:
for epoch in range(3):
for (b_ix, batch) in enumerate(train_loader):
optim.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs[0]
loss.backward()
optim.step()
训练完模型后,我们就可以对任意文本来进行情感的打分了,比如:

显然这是一句很 positive 的话,模型的打分为:

本章的完整代码可以参考 James D. McCaffrey 的博客:
https://jamesmccaffrey.wordpress.com/author/jamesdmccaffrey/
PS:模型的选择问题,这里作为演示采样了一个 distilbert 作为奖励模型,但实际上 ChatGPT 用的奖励模型的规模应该是和生成模型差不多大小的模型。
到目前为止,我们已经能够训练一个能够生成文本的 GPT,一个能够对文本打分的奖励模型,接下来就需要考虑如果用奖励模型来教会 GPT 生成高分文本了。考虑到很多同学可能没有强化学习的基础,这里将插入一章强化学习的介绍。
(深度)强化学习简介
强化学习的内容其实很多,背后涉及的数学也挺多,身边很多人在入门过程就被劝退,为了让大家更易于接受,这里主要介绍一些必备的基础知识,以及从策略梯度方法到 PPO 算法的演进。
强化术语
在强化学习中,智能体和环境进行交互并基于一定的奖励机制来提高自身的水平;智能体的决策,一般称为策略(policy)决定了在当前环境状态下智能体应该去实施什么动作;实施完动作后,智能体会随着环境进入下一个状态,并获得相应的奖励或惩罚。这里附上两页 slides 帮助大家理解(图片来源为 wangshusen 老师的强化课程)。

强化学习的最终目的就是要学会一个使得智能体能够最大化期望回报的 policy,其中的回报就是对奖励进行衰减求和:
和期望回报紧密相关的还有两个概念,一个是动作状态价值函数(观测到状态 ,做完决策,选中动作 ):
另一个是状态价值函数(可以理解为比如下围棋时评价当前状态 的胜率):
了解了上面的定义后我们可以停下来思考一下,强化学习学什么?
主要想学的肯定就是策略 policy 函数,也就是从状态到动作的一个映射,如果直接学习它,那就能够拿来使用了,这类方法也叫做基于 policy 的方法;如果采用间接点的方式,也可以学习值函数,然后根据值的大小来选择动作,这类方法也叫做基于 value 的方法。当然,通常基于 policy 的方法也会涉及到值函数的近似。
从策略梯度到 PPO
我们要学一个策略函数,但是并不知道策略函数长什样,怎么去定义它才是合适的。好在有了深度学习这一工具,我们可以无脑用一个神经网络来近似策略函数,然后通过优化神经网络参数的方式来学习得到一个策略函数。

优化神经网络的参数需要有个目标函数,如果一个策略很好,那么状态价值的均值应当很大,因此我们定义目标函数:
这个目标函数排除掉了状态 的因素,只依赖于策略网络 的参数 ;策略越好,则 越大。所以策略学习可以描述为这样一个优化问题:
我们希望通过对策略网络参数 的更新,使得目标函数 越来越大,也就意味着策略 网络越来越强。想要求解最大化问题,显然可以用梯度上升更新模型的参数。值得庆幸的是,策略函数的梯度还能被推导出来:
策略梯度定理的详细推导这里就不展开了,我们需要记住的是能计算出目标函数关于参数的梯度,那就能用来更新参数,也就能学习出策略函数了。
当然这里面还涉及动作价值函数 的估计,如果用实际观测的回报来近似,那就是 REINFORE 算法,如果再用一个神经网络来近似这个价值函数,那就是演员-评论家算法。PS:在实际使用中,策略梯度中的 Q 有多种不同的替代形式,常见效果比较好的形式是采用优势函数 (状态动作值函数 减去状态值函数 )来替代。
传统的策略梯度算法的局限性在于它是 sample-inefficient 的,也就是说每次获取的训练数据只被用来更新一次模型的参数后就丢掉了,因此 PPO 算法的主要改进在于构造了新的目标函数(避免较大的参数变化),使得每次获取的训练数据能够被用于多次的参数更新。

其中比值函数为当前策略和历史策略在状态 下实施动作 的概率的比值

通过这一比值也就能够评估新旧策略的差异性,从而能够保证策略函数在更新参数时不会跟旧策略的差异太大。有时间的同学也可以对比值在不同区间时目标函数的情况进行考虑,也就是如下表的情况(下面的 就是上面提到的比值函数 )。

此外,我们知道在强化学习中通常还需要去让智能体能够具有 exploratory 的表现,这样才能挖掘出更多具有高价值的行为,所以 PPO 算法在训练策略网络时还在目标函数中加上了和熵相关的一项奖励 :
这里以离散动作为例,可以看到如果实施动作的概率分散到不同的动作上将具有更大的熵。

前面介绍策略梯度时知道策略梯度中还涉及价值函数/优势函数的估计,在 PPO 算法中也是采用神经网络来估计状态价值函数,训练价值网络的目标函数通常仅需要最小化价值网络的预测和目标的平方误差就可以了
综上所述,PPO 算法完整的优化目标函数由三部分组成,为
PPO 算法代码解读
了解完原理后,我们来看一下强化的代码一般怎么写的。
训练智能体前一般需要定义一个环境
envs = xxxx
环境需要具有两个主要的功能函数,一个是 step,它的输入是动作,输出是下一步的观测、奖励、以及表示环境是否结束等额外信息
next_obs, reward, done, info = envs.step(action)
另一个是 reset,主要用来重置环境。
然后需要定义一个智能体,智能体包含策略网络和价值网络两部分(也就是演员和评论家),get_value 函数使用价值网络评估状态的价值,get_action_and_value 函数使用策略网络给出了某个状态下动作的概率分布(以及对数概率)、概率分布采样得到的动作,概率分布的熵、以及状态的价值。
class Agent(nn.Module):
def __init__(self, envs):
super().__init__()
self.critic = nn.Sequential(
layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 1), std=1.0),
)
self.actor = nn.Sequential(
layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, envs.single_action_space.n), std=0.01),
)
def get_value(self, x):
return self.critic(x)
def get_action_and_value(self, x, action=None):
logits = self.actor(x)
probs = Categorical(logits=logits)
if action is None:
action = probs.sample()
return action, probs.log_prob(action), probs.entropy(), self.critic(x)
接下来就只需要考虑如何收集数据和训练网络了:
- 收集数据阶段主要包括两个部分,一部分是用智能体去和环境做交互,并保存相应的状态、动作等信息,另一部分主要是根据每一步的奖励来计算每一步的回报,从而计算用于评估动作好坏的优势函数值。
for step in range(0, args.num_steps):
obs[step] = next_obs
dones[step] = next_done
with torch.no_grad():
action, logprob, _, value = agent.get_action_and_value(next_obs)
values[step] = value.flatten()
actions[step] = action
logprobs[step] = logprob
next_obs, reward, done, info = envs.step(action.cpu().numpy())
rewards[step] = torch.tensor(reward).to(device).view(-1)
with torch.no_grad():
next_value = agent.get_value(next_obs).reshape(1, -1)
returns = torch.zeros_like(rewards).to(device)
for t in reversed(range(args.num_steps)):
if t == args.num_steps - 1:
nextnonterminal = 1.0 - next_done
next_return = next_value
else:
nextnonterminal = 1.0 - dones[t + 1]
next_return = returns[t + 1]
returns[t] = rewards[t] + args.gamma * nextnonterminal * next_return
advantages = returns - values
- 训练网络部分主要就是根据之前提到的三部分目标函数,依次计算新旧策略的差异从而计算策略网络的损失、价值网络的损失 以及 关于动作多样性的熵奖励;累加后再进行反向传播就可以更新网络的参数了。
for epoch in range(args.update_epochs):
np.random.shuffle(b_inds)
for start in range(0, args.batch_size, args.minibatch_size):
end = start + args.minibatch_size
mb_inds = b_inds[start:end]
# 计算新旧策略的差异
_, newlogprob, entropy, newvalue = agent.get_action_and_value(b_obs[mb_inds], b_actions.long()[mb_inds])
logratio = newlogprob - b_logprobs[mb_inds]
ratio = logratio.exp()
mb_advantages = b_advantages[mb_inds]
# 策略网络损失
pg_loss1 = -mb_advantages * ratio
pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)
pg_loss = torch.max(pg_loss1, pg_loss2).mean()
# 价值网络损失
newvalue = newvalue.view(-1)
v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()
entropy_loss = entropy.mean()
loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
optimizer.step()
PPO 的完整代码可以参考https://github.com/huggingface/deep-rl-class/blob/main/unit8/unit8.ipynb
也建议大家有空可以阅读一下这篇文章,有助于加强对强化的理解:
https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf
利用奖励模型强化 GPT:迈向 ChatGPT
看到了这里,我们已经学会啦如何训练一个 GPT,训练一个奖励模型,以及强化学习算法 PPO 的训练过程,将它们组合起来,就能够做出一个 ChatGPT 了!
这里我们先定义两个 GPT 模型,一个用于强化,一个用于参考(因为我们通常也不希望强化的模型完全朝着更高的奖励去优化,所以可以约束一下强化的模型和原始模型仍然具有一定的“相似性”),参考模型不用于优化,所以设为 eval 模式即可。
model = GPT()
ref_model = GPT()
ref_model.eval()
需要注意的是为了适应强化这个框架,我们还需要对原来的 GPT 模型进行一定的封装,其实主要就是加一层 value head(线性层),让它预测每一个 token 的价值(理解为值函数,将 token 的隐藏状态转化为一个标量值)。
为了让大家更加清楚地了解训练的过程,我们以一条样本为例来展示说明数据的传递过程。
假设我们有一个 query(就是送入 gpt 的输入),前面说过模型的输入一般经过分词器转化为一串 id,比如:
送入 GPT 后,生成模型会接着输入进行“续写”,得到一条回答 response:
然后我们可以把这 query 和 response 拼接起来并解码为文本后送入奖励模型,得到一个 rewards(可以理解 chatgpt 的回答好,就意味这把提问和模型的回答拼在一起看是合理的),接下来就可以考虑使用 PPO 算法来对 GPT 进行强化了。
首先第一步我们就是把“提问”和“回答”拼接起来,送给奖励模型,让它给 GPT 的回答打个分:
texts = [q + r for q, r in zip(query, response)]
score = reward_model(texts)[1]["score"]
有了这个得分后,就可以让 GPT 模型朝着尽可能高分的方向去优化了。
把拼接后的文本送入模型,并取出对应 token 的(对数)概率,这里并不需要梯度的传播,主要是获得“旧”的动作(模型的回答),以及用于计算每一个 token 的奖励:
with torch.no_grad():
logits, _, v = self.model(**input_kwargs)
ref_logits, _, _ = self.ref_model(**input_kwargs)
old_logprobs = logprobs_from_logits(logits[:, :-1, :], input_ids[:, 1:])
ref_logprobs = logprobs_from_logits(ref_logits[:, :-1, :], input_ids[:, 1:])
计算奖励这里考虑两个部分,一部分是用于强化的 GPT 模型的回答和参考模型回答的 KL 散度(如前面所说,不能让模型一味朝着奖励高的方向优化),另一部分就是奖励模型给出的评分:
kl = old_logprobs - ref_logprob
reward = -kl
reward[-1] += score
接下来进行模型的前向传播(这里是需要梯度的),并索引出 response 部分的动作概率和值函数:
logits, _, vpred = self.model(**input_kwargs)
logprob = logprobs_from_logits(logits[:, :-1, :], model_input[:, 1:])
logprob, vpred = logprob[:, -gen_len:], vpred[:, -gen_len:]
计算 loss 之前我们需要估计一下优势函数和回报,优势函数用于更新策略网络,回报用于更新价值网络,这里采用经典的 GAE 方法(可以有效降低策略梯度的估计方差)来估计优势函数:
lastgaelam = 0
advantages_reversed = []
for t in reversed(range(gen_len)):
nextvalues = values[:, t + 1] if t < gen_len - 1 else 0.0
delta = rewards[:, t] + self.config.gamma * nextvalues - values[:, t]
lastgaelam = delta + self.config.gamma * self.config.lam * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1]).transpose(0, 1)
returns = advantages + values
计算策略网络的损失:
ratio = torch.exp(logprob - old_logprobs)
pg_losses = -advantages * torch.clamp(ratio, 1.0 - self.config.cliprange, 1.0 + self.config.cliprange)
pg_loss = torch.mean(pg_losses)
价值函数的损失:
vf_losses = (vpred - returns) ** 2
vf_loss = 0.5 * torch.mean(vf_losses)
整体误差反向传播:
loss = pg_loss + self.config.vf_coef * vf_loss
optimizer.zero_grad()
accelerator.backward(loss)
optimizer.step()
这样就完成了使用 PPO 来强化 GPT 的一个 step 了,也就是 ChatGPT 实现的核心思想。
可以看上面的通过强化 GPT 再用于生成的一个效果:

以及将结果再用奖励模型打分的前后对比:
mean:
rewards (before) 0.156629
rewards (after) 1.686487
median:
rewards (before) -0.547091
rewards (after) 2.479868
可以看到 GPT 生成结果的整体得分都有比较大的提升,这也说明了如果奖励模型训练得好,那用来做 ChatGPT 的效果自然也就能够大幅度提高。
本章的完整代码可以参考开源项目:
https://github.com/lvwerra/trl
写在最后,其实个人觉得 ChatGPT 能够这么火(或者说效果能够做得这么好)主要还是来自于大量高质量的人工标注数据(第一步的监督,第二步的奖励模型的训练),验证了一句话,人工智能就是需要“人工”才能走向“智能”哈哈。
Reference
- https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
- https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
- https://arxiv.org/pdf/2005.14165.pdf
- https://openai.com/blog/chatgpt/
- https://huggingface.co/docs/transformers/model_doc/gpt2
- https://huggingface.co/blog/rlhf
- https://huggingface.co/blog/deep-rl-ppo
- https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf
- https://github.com/lvwerra/trl
- https://github.com/wangshusen/DRL
红包封面福利

点击卡片进入公众号后台
回复:2023 即可参与封面抽奖





