


随着产业互联网发展,传统产业中业务爆发式增长与无限增长趋势愈加明显与普及。业务敏态发展对底层基础技术提出了具备敏态能力的要求。
TDSQL是腾讯云企业级分布式数据库,具有完全兼容 MySQL、分布式事务全局一致性、弹性扩缩容、智能调度管控、在线表结构变更等关键特性。金融级分布式数据库 TDSQL 新引擎TDStore针对产业技术趋势需求,聚焦适配金融级敏态业务,在频繁进行模式变更、数据流量陡增等敏态场景下,实现弹性伸缩变更、对业务透明无感知。
今天,腾讯云数据库高级工程师韩硕带领大家了解金融级分布式数据库TDSQL新引擎TDStore的特性与设计理念,揭秘金融级分布式数据库TDStore引擎弹性伸缩特性在存储层的实现原理。
背景
TDSQL诞生自腾讯内部百亿级账户规模的金融级场景,目前已在众多金融、政务、电商、社交等客户应用案例中奠定了金融级高可用、强一致、高性能的产品特性和口碑,国内前20的银行近半都在使用TDSQL,有力推动了国产数据库技术创新与发展。
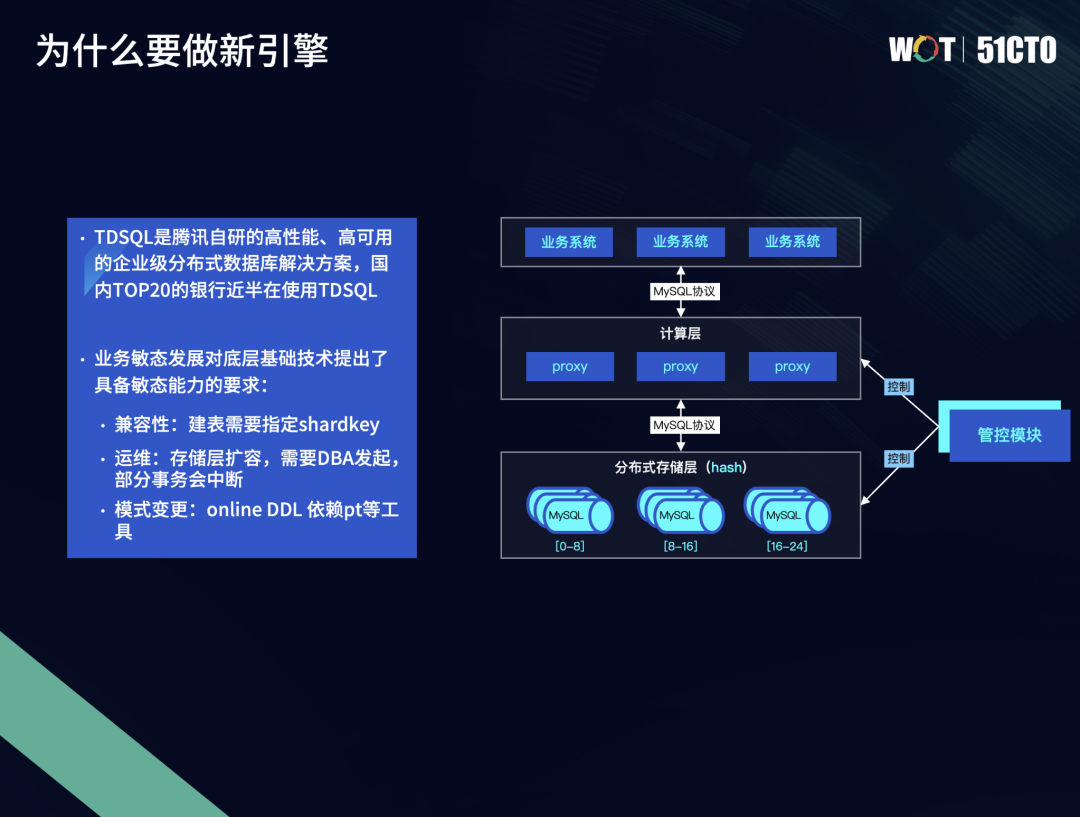
随着业务场景的不断增长和复杂化,业务形态、业务量的不可预知性增大,业务的敏态发展对数据库底层技术提出了具备敏态变更能力的要求。目前已投产的TDSQL在应对业务的敏态变更时,有三个痛点需要改善:
- 兼容性:在建表的过程中需要手工去执行Shard key。
- 运维:随着业务的不断增长,规模越来越大,面对扩容场景,目前还需要DBA来进行发起,导致部分输入会被阻断,使得升级过程不够平滑。
- 模式变更:目前在线表模式变更更多依赖于PT等外围工具。
因此,针对以上业务痛点,我们在2021年发布了TDSQL新引擎TDStore,并于2022年8月开始投入公有云商业化运营。TDStore引擎针对不断变化的敏态业务,实现PB级存储的Online DDL,可以大幅提升表结构变更过程中的数据库吞吐量,有效应对业务变化;其独有的数据形态自动感知特性,使数据能根据业务负载情况实现自动迁移,打散热点,降低分布式事务比例,获得极致的扩展性和性能。
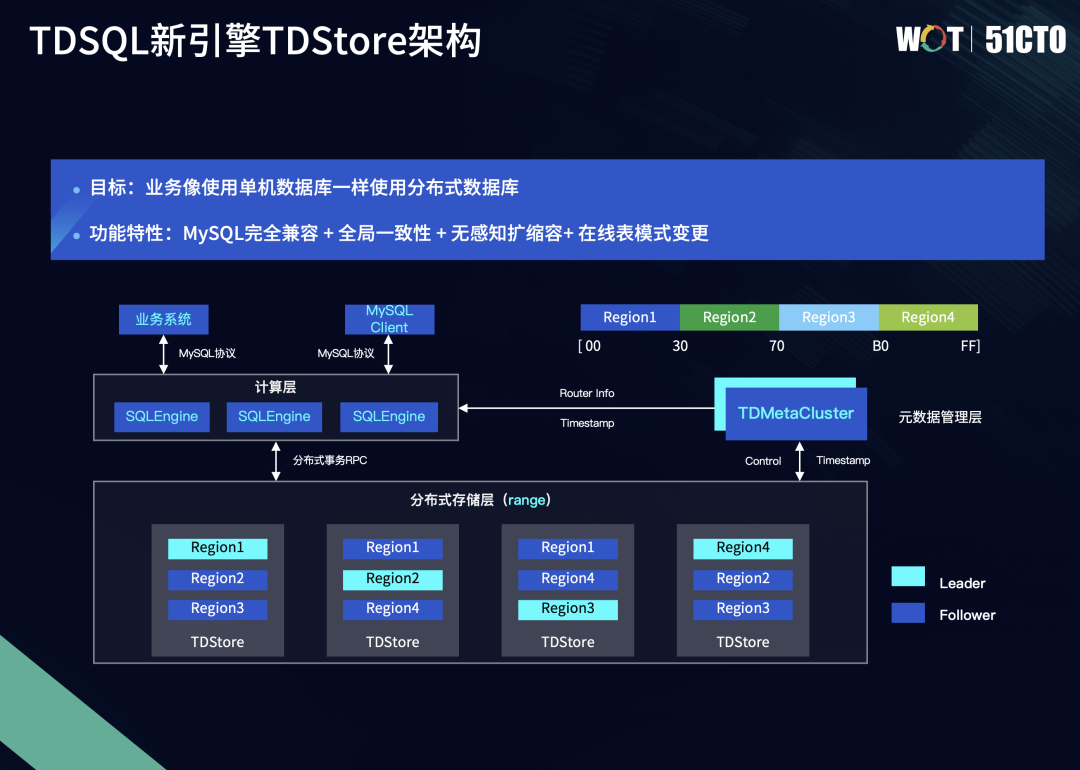
综上所述,TDSQL新引擎TDStore的愿景,是希望可以让业务能够像使用单机数据库一样去使用分布式数据库。
TDSQL新引擎TDStore
技术亮点
TDSQL新引擎TDStore具备以下功能特性:
一是MySQL兼容、分布式、低成本:
- 兼容原生MySQL语法,具有事务的全局一致性,无感知扩缩容。
- 纯分布式引擎,数据以KeyRange来做组织和路由,业务层不再需要做分库分表。
- 存储引擎模块采用LSM-tree结构,具备良好压缩比,适合大规模数据量的业务。
二是高可扩展、计算/存储资源弹性扩缩容:
- 计算层为多主模式,每个SQLEngine都是完全对等的节点,可读可写;无状态化设计,可根据业务流量灵活增加或减少计算层节点,从而适应业务的峰值或低谷。
- 存储层可根据存储量需求,做弹性、对业务无感知的扩缩容,通过数据的添加或者迁移自动打散数据分布热点,进一步降低分布式事务比例,实现线性扩展比。

三是全局读一致性:
- 通过管控模块TDMetaCluster给计算节点、存储节点分配全局统一的事务时间戳。
- 存储层基于MVCC和事务时间戳来做全局一致的可见性判定。
四是Online DDL:
- 支持在线表模式变更的常见操作。
- 支持在线加减索引。
- 支持大部分DDL操作以Online方式执行
TDSQL新引擎TDStore
架构设计
TDSQL新引擎TDStore架构分为三个核心模块,分别为计算模块SQLEngine、存储模块TDStore、管控模块TDMetaCluster。
3.1 计算模块SQLEngine
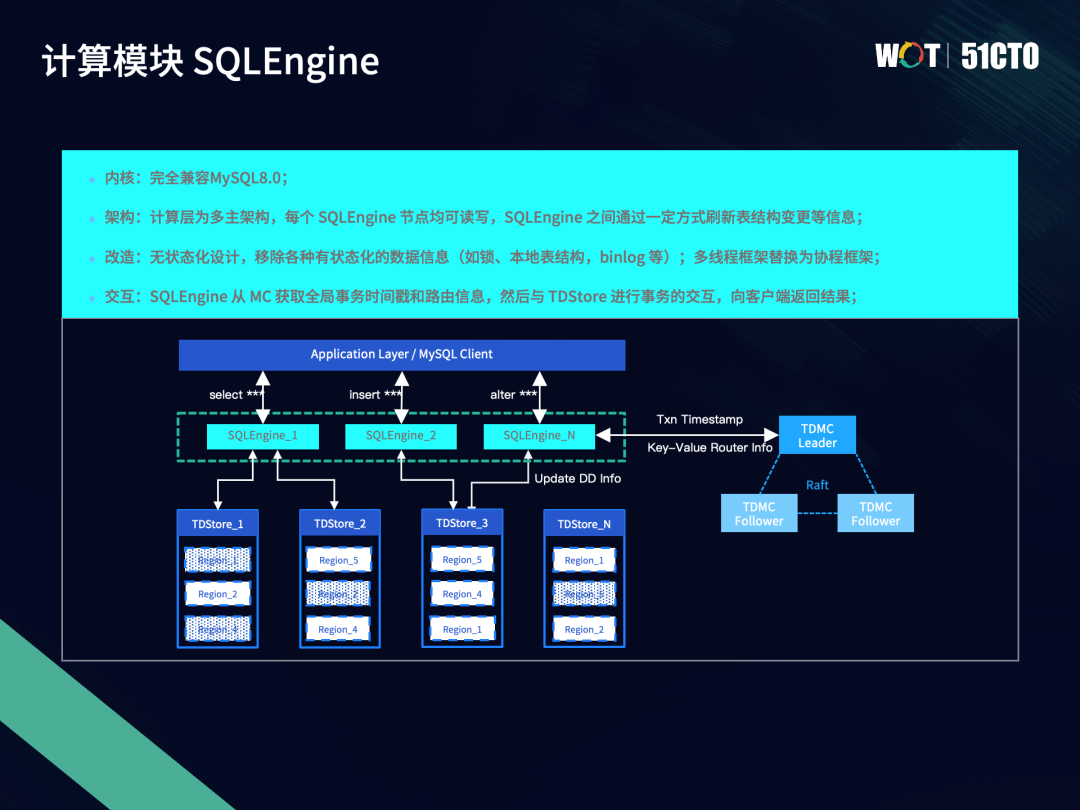
每个SQLEngine节点完全对等,都可读可写,且为无状态节点,SQLEngine之间会通过一定的方式来同步在线表模式变更的信息。TDSQL完全兼容MySQL8.0。我们通过移除各自有状态化的数据信息,从而实现无状态化设计,并将多线程框架替换为协程框架,实现更好的并发性能。
3.2 存储模块TDStore
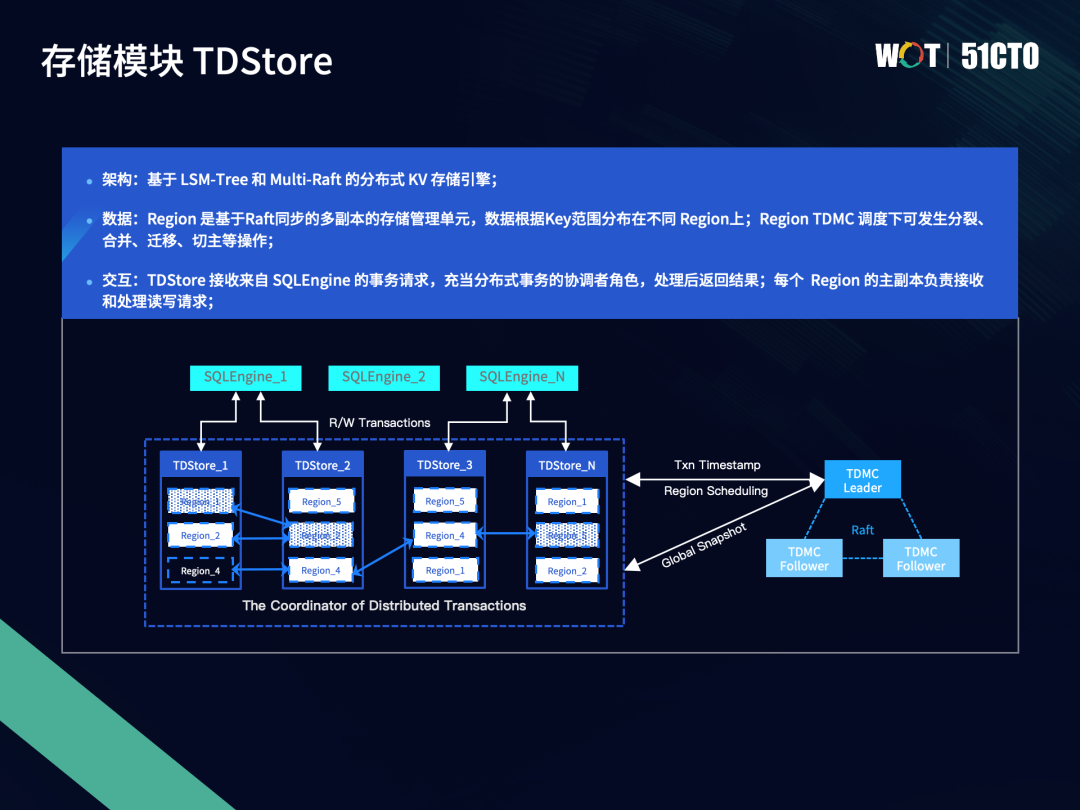
存储模块是share nothing架构,底层实现则是基于LSM-tree结构,这意味着每个数据分片的基本数据单元都有自己独一无二的owner。我们以Key Region作为划分标准,将数据划分成一个个分片——Region。同时为了满足灾备的需求,Region的多个副本通过分布式一致性协议Raft来提供一主多备方案。存储模块的每个节点都会分布多个Region,Region有多个副本,在不同的TDSQL节点之间会随着数据量的变化进行性能、数据量的自动均衡。在自动均衡的过程中,需要上层TDMetaCluster的管控模块来配合完成。TDMetaCluster模块通过下发基本的基于Region的任务,比如分列、合并、迁移、切主等,来实现弹性扩缩容。
3.3 管控模块TDMetaCluster
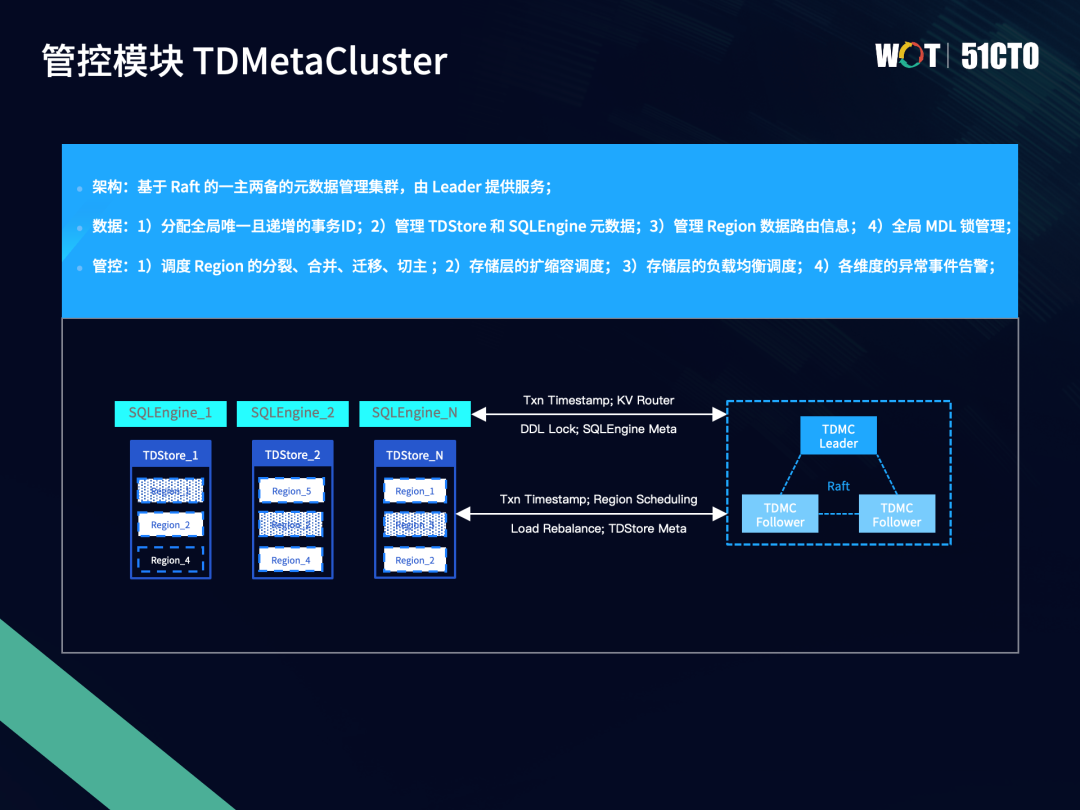
TDSQL新引擎TDStore的管控模块主要负责三方面工作:
- 高效地生成和下发全局唯一的事务时间戳;
- 管理各模块的元数据以及Region的路由信息;
- 以Region为基本单位进行负载均衡和存储均衡调度。
调度需要考虑Region的热点,尽量将热点Region打散在不同存储节点上,还需要兼顾对性能的影响,通过对Region的合理划分和调度,尽可能将跨Region的2PC事务转化为1PC,降低事务延迟。
TDSQL新引擎TDStore
分布式事务
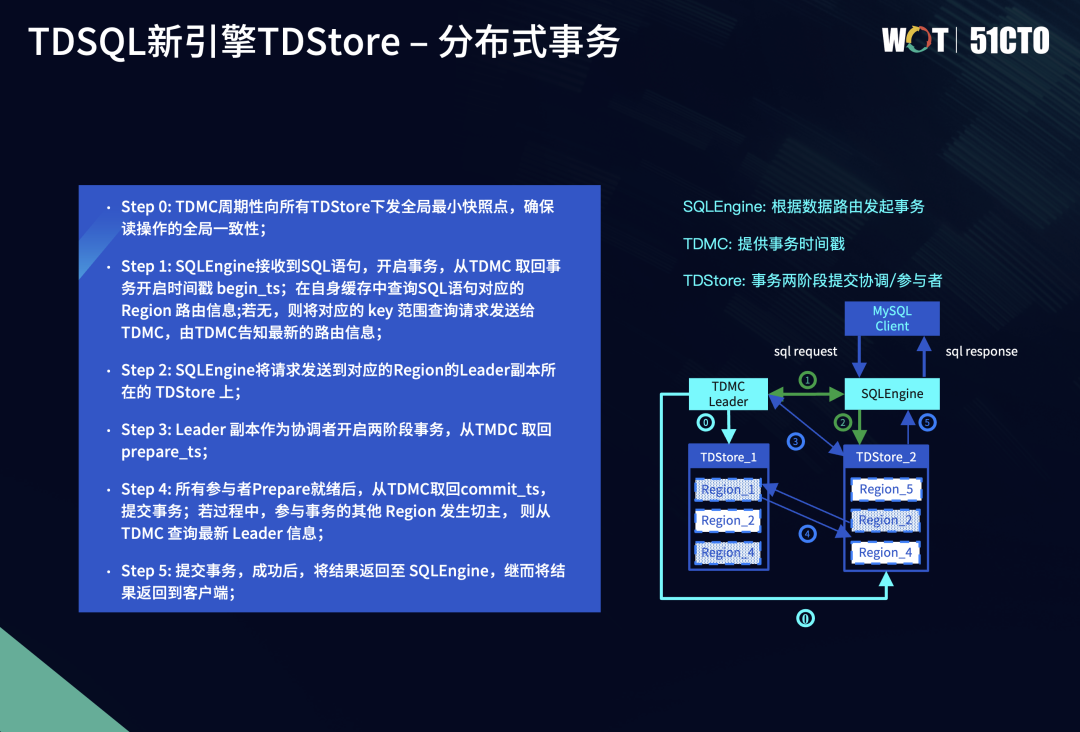
TDSQL新引擎TDStore的分布式事务模型,遵从了2PC(2阶段)提交协议,来保证分布式事务提交的原子性。对于涉及多个Region的分布式事务,所有参与者要么全部提交成功,要么全部回滚,不允许半提交的发生。
与经典的Percolator模型相比,我们的实现方案做了部分改动。Percolator模型的冲突检测、MVCC机制等都是在上层维护,由计算层作为两阶段提交的协调者。在TDSQL新引擎中,我们将协调者下沉到存储层,即在多个Region参与者中选取一个作为协调者,由TDStore保证事务提交的原子性,同时将未提交事务数据的缓存也下沉到存储层TDStore。
这样做的好处是降低了数据落盘的次数。在prepare阶段,Percolator方案需要将锁数据落盘,在commit阶段再把数据项落盘。但在我们的下沉方案中,数据项和锁缓存在TDStore中,只有在commit阶段将数据落盘一次,有效降低了IO开销。
在实现层面,我们对存储层TDStore的改动包括两方面:
- 添加了对数据项加memory lock的逻辑,实现prepare时lock、commit 时unlock的效果,相当于在存储节点上实现了2PC协议的协调者和参与者逻辑。
- 历史版本的清除需要计算全局最小活跃事务时间戳,不能只考虑单个TDStore,我们借助compaction机制进行自动的过期版本数据清除,不需要额外的gc模块。
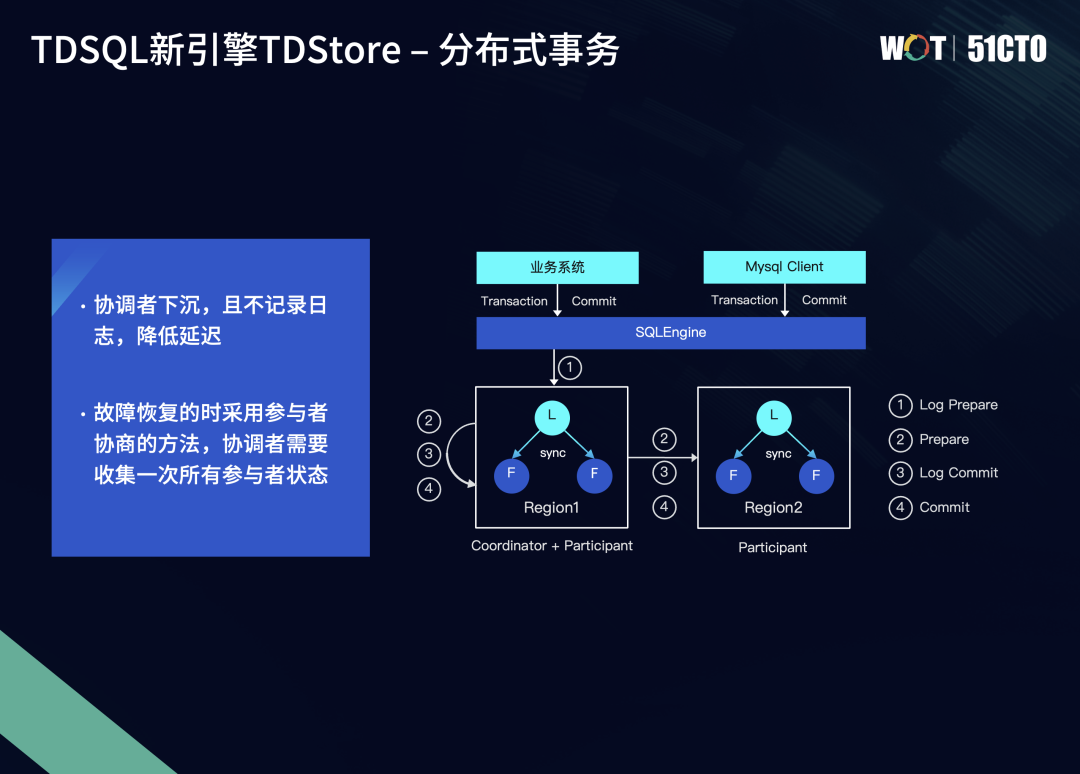
在分布式事务总体流程中,管控模块会周期性地去推动全局最小时间戳,即全局快照点,从而保证读的全局一致性以及过期数据的自动回收。在事务的开启阶段,首先SQLEngine会接收到来自Client端的SQL语句,开启一个事务。开启事务后,我们会从管控模块拿到事务的开启时间戳Start-ts,这时它会留意自身缓存中有没有SQL语句对应要查询数据范围Region的路由信息。如果没有,就会从MC重新拉入最新的路由。
SQLEngine会将事务的读写请求发送到Region的Leader所对应的TDStore上,再由TDStore的Leader节点作为两阶段事务的协调者来开启两阶段事务。进入到准备阶段后,我们会拿到一个prepare-ts,再基于prepare-ts做并发事务的冲突检测。当所有的参与者都prepare就绪后,会生成一个commit-ts作为事务提交的时间戳。如果事务提交过程中发生了切主、分裂等Region信息的变更,这时我们需要重新去更新一下最新的Leader消息以及Region参与者列表,从而保证事务提交过程中的完整性。当事务提交后,我们会把结果通过SQLEngine再返回到客户端。
TDSQL新引擎TDStore
无感知扩缩容
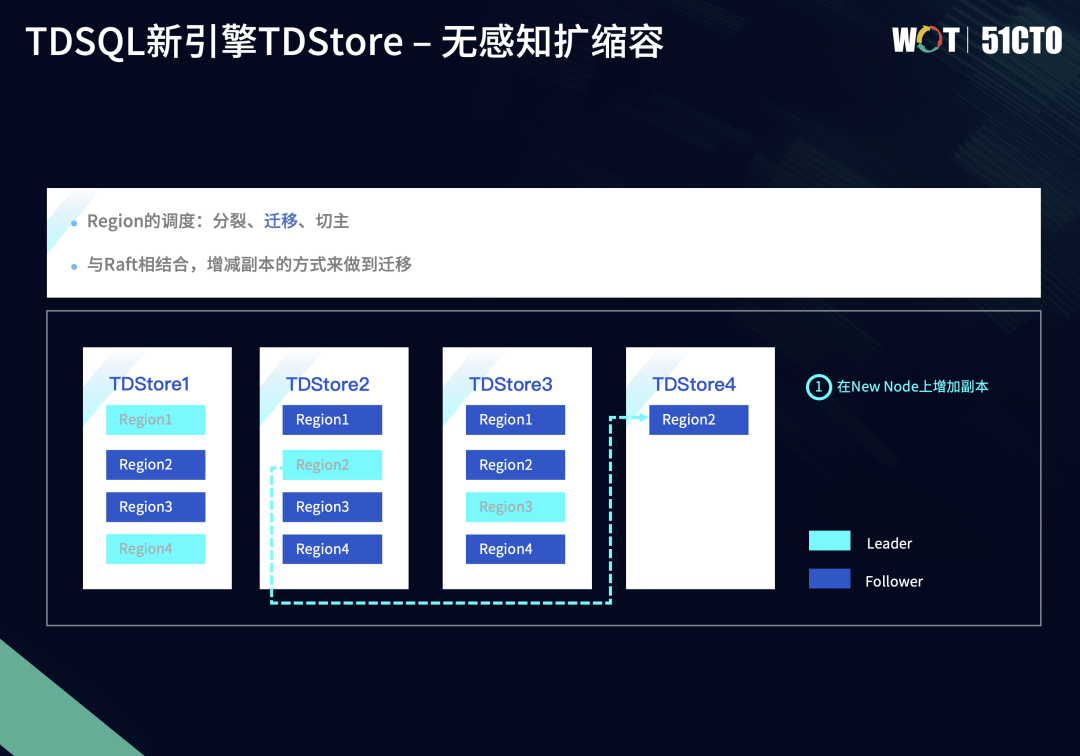
无感知扩缩容是TDSQL新引擎TDStore最重要的特性,其通过存储层TDStore和管控模块TDMetaCluster的配合来完成。TDMetaCluster会自动监测到每个TDSQL节点上数据分布的信息,包括查询热点的信息,这些都是通过TDStore上报给管控模块后再进行处理。以扩容为例,数据调度通过Region来进行,主要分为三个任务,即分裂、迁移和切主。
5.1 无感知扩缩容-分裂
下图中有三个TDStore节点,属于一主两备三副本的Region的数据分布。假设Region1的数据量达到一定阈值,这时MC监测到Region1的数据量超过阈值,就会判定Region1需要进行分裂,将Region1分裂成Region1和Region4。

MC会向TDStore1节点发送信息,让它在Region1节点下发一个分裂的任务请求。TDStore1会计算Region1的合适分裂点,但合适分裂点的选择需要考量很多因素,比如希望Region分裂后的数据尽可能均匀或希望分裂后的新Region和老Region之间的事务热点尽可能均匀,针对不同的场景,我们也会有不同的分裂策略。
整个分裂流程也遵循两阶段提交,MC作为协调者,Region的所有副本作为参与者,保证全员成功或者失败,避免部分副本分裂成功、部分副本分裂失败的半提交状态。

分裂过程中,TDStore Region Leader会计算出分裂点,将Region分裂地尽可能均匀。需要注意的是,分裂流程只是在元信息层面对Region一分为二,对于底层数据没有变动。我们以Split-key的节点,来重新计算老Region1的区间。
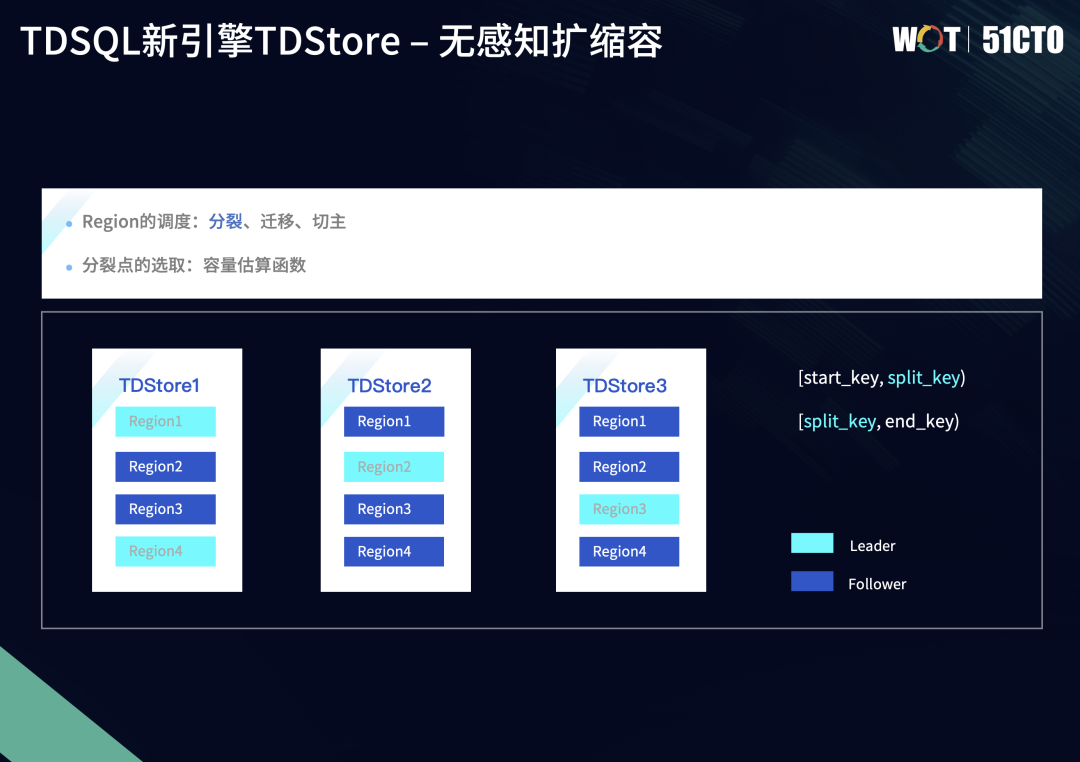
分裂结束后,数据在TDStore节点之间并无明显变化,只是多了一个Region。这时并没有实现存储数据的扩容。
5.2 无感知扩缩容-迁移
迁移是让数据扩展出去的最关键操作。如下图所示,我们把数据分成更多的Region后,会将部分Region迁移到新增的存储节点如TDStore4上。
该例子是把Region2进行迁移,迁移的整体流程使用Raft协议增减副本的方式,即先增加一个副本、再减少一个副本。比如Region2最开始是3副本,在TDStore2上的节点是Leader,另外两个节点是Follower。在迁移时,我们先在TDStore4上创建一个Region2的Follower新副本,创建的新副本里的数据是空的,这时会触发Raft协议中快照安装的流程,会将快照的数据信息从Leader节点上传到新创建的副本上。
在增加一个副本后,即由3副本变成了4副本,后续还要恢复成3副本,因此需要再删掉一个旧副本,即把TDStore1上的Region2 Follower节点删掉,这样就实现了Region副本的数据迁移,Region2副本的数据也迁移到新的TDStore4节点上。

在迁移过程中,Region分裂只是在元数据层面,最关键的是要把数据通过快照的方式传输且装载到新的节点上,这就是性能瓶颈。为了突破这个瓶颈,我们在迁移的过程中结合Raft协议以及LSM-tree结构,具体的实现步骤如下:
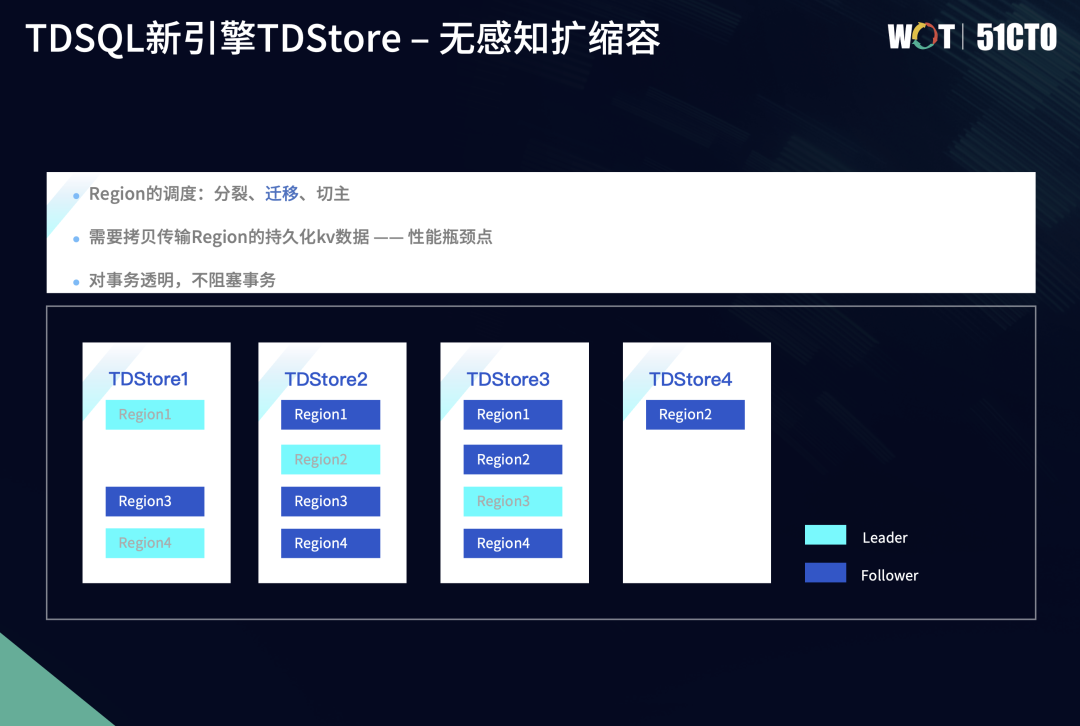
根据上文例子,我们需要把Region2迁移过去,MC会不断下发迁移任务,慢慢使三个节点之间的数据规模达到均衡,将其他的三个Region中的某个副本逐渐迁移过来。
迁移结束后,这4个Region在新增的TDStore4以及之前的三个TDStore之间,Region的数量都已经达到均衡。数据存储在不同的TDStore节点上达到均衡,并不意味着负载就真正均衡。因为TDStore是基于一主多备的形态,而Raft协议的原则是读写请求都会由Leader节点来承担,TDStore1上现有两个Leader,分别是Region1和Region4的Leader,但TDStore4没有Leader。假设4个Region上的读写请求的流量都一致,这时TDStore1上承载的读写请求会多于TDStore4,因为TDStore4是一个单纯的Follower节点,它只需要从各个Leader节点上同步最新的log以及事务数据信息。
值得一提的是,TDSQL新引擎TDStore在迁移过程中是天然地对事务透明,迁移只是Follower Region副本在不同TDStore节点上的变动,对事务完全不阻塞。
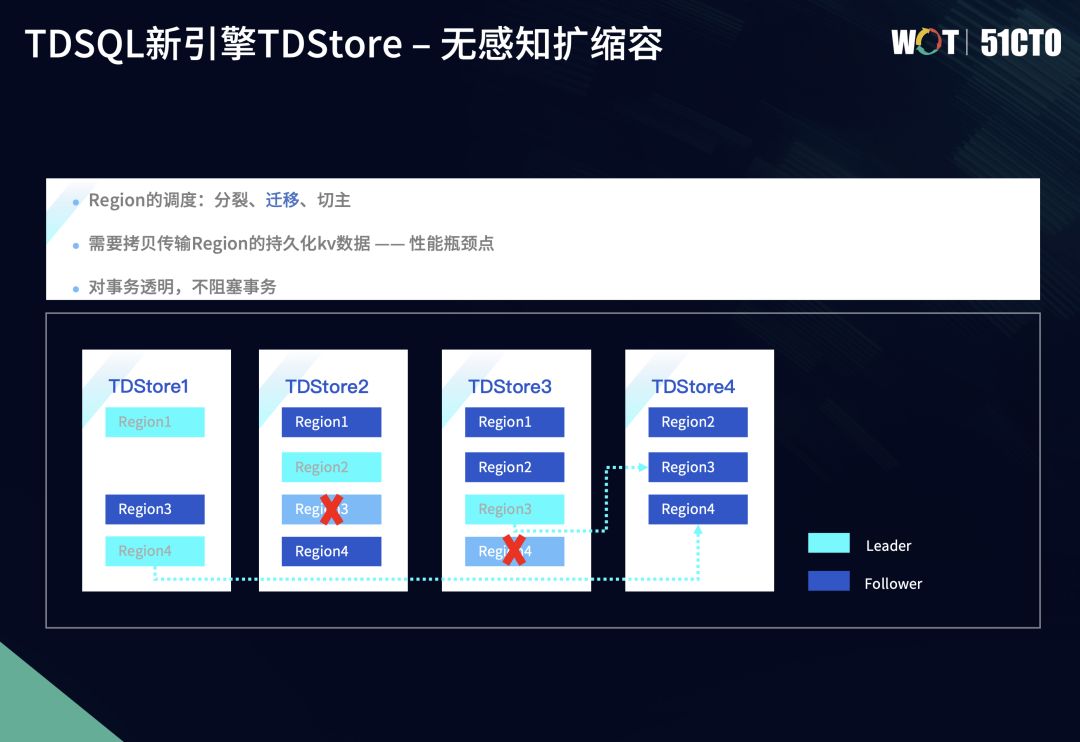
5.3 无感知扩缩容-切主
出现负载不均衡的原因是Region1上的Leader较多。如果要达到近似的负载均衡,就依赖于下一个任务——切主。切主的目的是均衡Region在不同TDStore存储节点的Leader分布,从而达到调整读写事务的热点,实现最终负载的均衡。

在切主过程中,部分事务还在活跃阶段,这时我们需要进行界定,因为事务的推进都是由Leader节点来进行,我们以2PC的准备阶段作为分界点。如果进入prepare阶段的事务,我们就会将事务的上下文信息在切主过程中同时传递到它的新Leader上,由新Leader推进事务后续提交的执行流程;如果还没有进入到prepare阶段的两阶段事务,我们就会把这个信息做拷贝,传递过来。

5.4 Region调度与事务并发
TDSQL新引擎TDStore最重要的设计目标,是让业务在敏态变化时无感知。因此在数据进行分裂迁移时,不影响业务事务的正常进行就显得尤为重要。但数据分裂迁移涉及到Region元数据的变化以及底层数据的变动,要在工程上进行实现是一个较大的挑战。
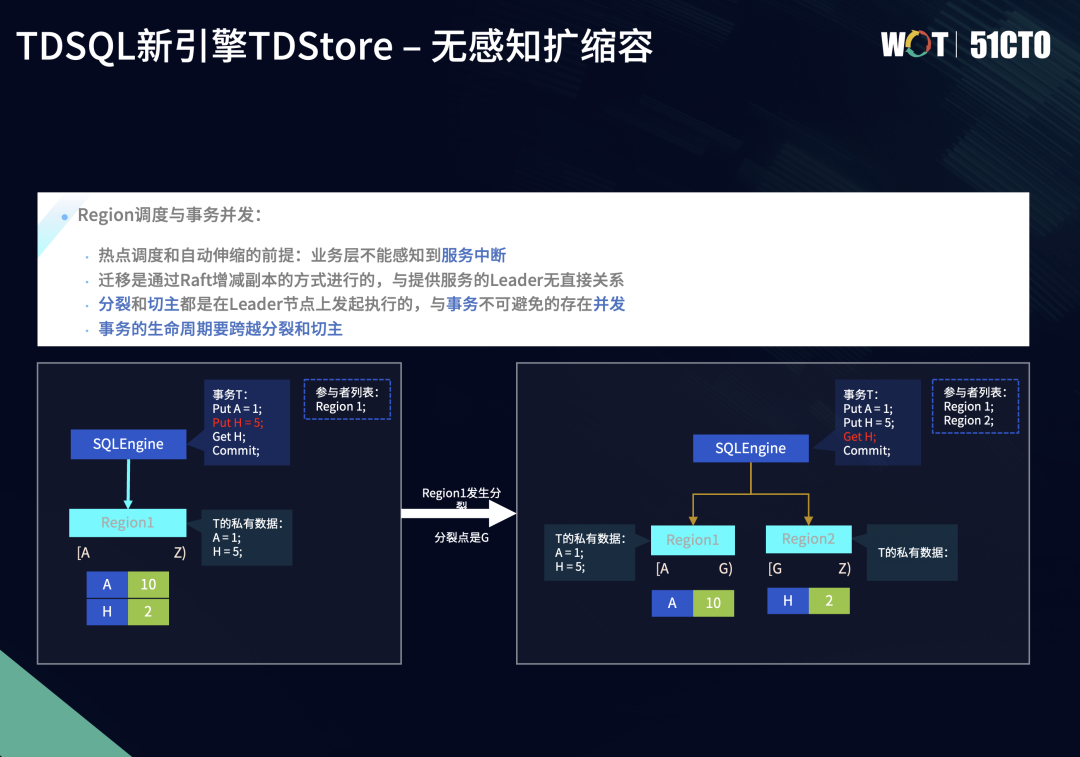
迁移场景对于事务执行透明,而分裂和切主任务都是在Leader上执行,因此存在事务的并发,对此我们需要保证事务的生命周期跨越分裂和切主流程。
以分裂为例,图中的Region1分裂前的数据范围是A到Z,这时它上面有活跃的事务T,之前写入两条数据,分别是put A=1、put H=5。分裂前事务T在事务缓存中保留A=1、H=5的数据。我们以G为分裂点进行分裂,把它分裂成Region1、Region2,其中Region1的范围变成了A到G,Region2的范围变成了G到Z。
我们发现H数据项在分裂后属于Region2。在分裂过程中,如果事务变成一个跨Region的事务,就会把它所属的Region上的数据项H=5分裂传输到新的Region节点上。即Region上活跃的私有事务,在分裂过程中要做事务上下文数据的迁移。
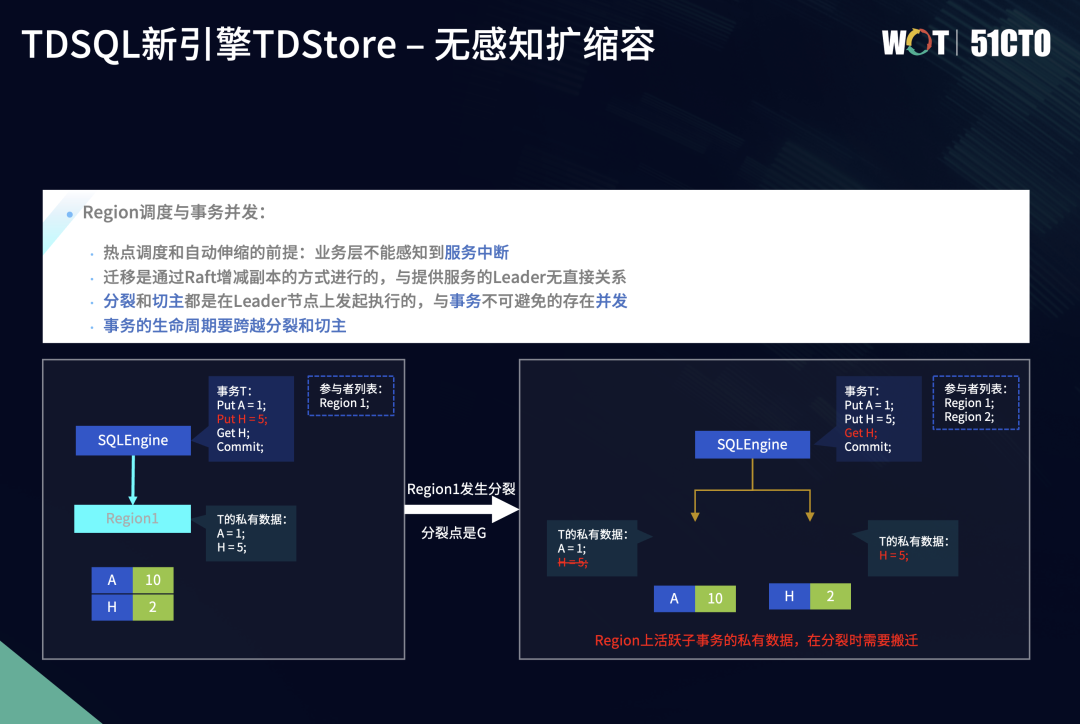
迁移后,除事务信息的分裂和传输,事务也从最开始只涉及到一个Region,优化到一个一阶段提交。分裂后,也由单一的一阶段事务变成两阶段提交的事务。因为在分裂过程中事务没有提交,因此在后续的提交过程中,就需要进行参与者列表的更新。这时在事务准备和提交阶段,我们会检查旧Region有没有分裂。如果Region发生分裂,我们还需要更新事务参与者列表,从而使得事务在最终提交时,能够让新增的参与者Region2也能一同提交,保证分布式事务的原子性。
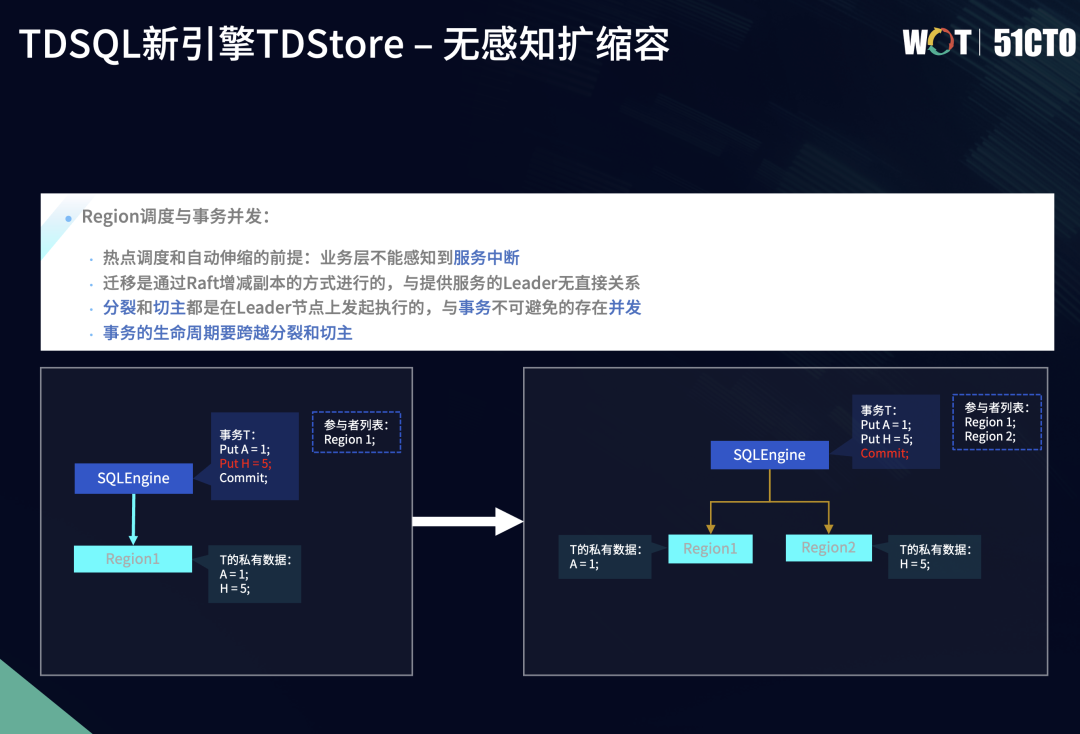
TDSQL新版本
数据存储与迁移
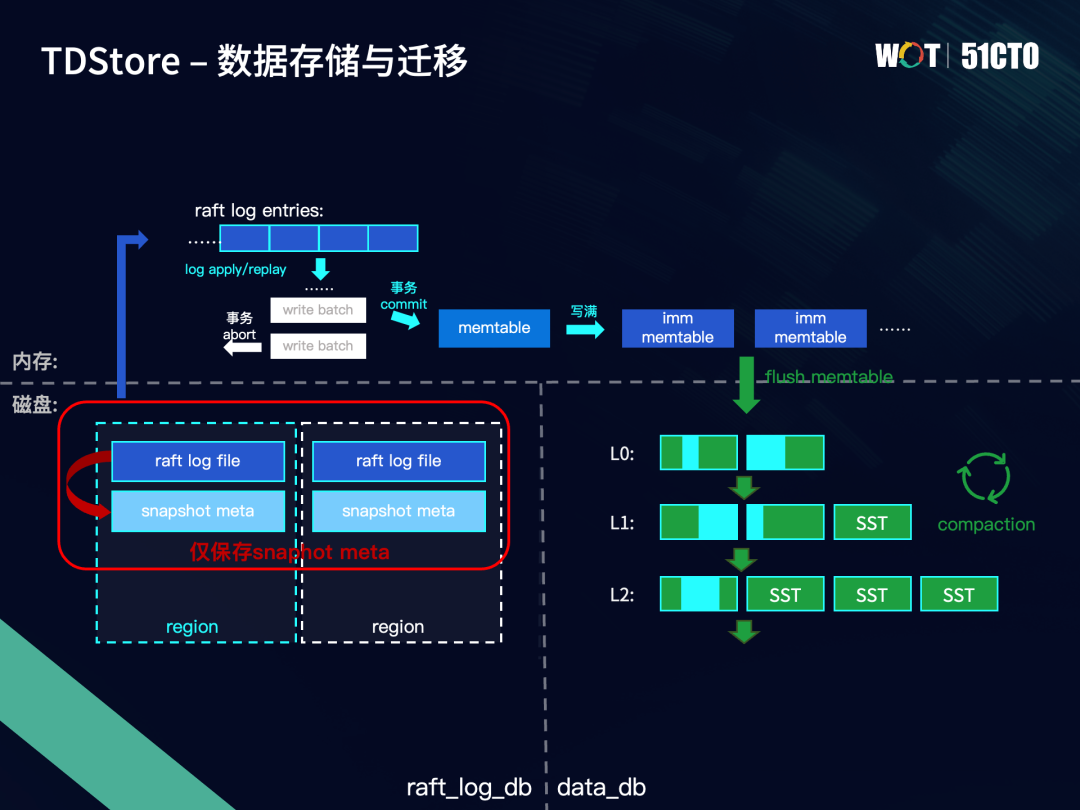
本部分主要介绍存储节点中数据库具体的存储步骤以及突破迁移的瓶颈实现方式。
下图展示了TDStore中数据的持久化流程。持久化数据可分为Raft log和kv数据,分别对应左侧的Raft log存储和右侧的kv数据存储。假设我们开启两个DB实例,事务写入的数据以Raft log的形式同步到Region的不同副本上,当一条log entry在多数副本上都落盘到Raft log file中,就认为这条log entry已提交,将它进行apply执行或者replay回放,其中的事务数据会暂存在write batch中。当事务提交时,write batch中的数据会写入到memtable中,如果事务失败abort,write batch中的数据就会直接丢弃。
当memtable达到阈值时,就会变为一个不可变的immutable memtable。当immutable memtable的数量满了以后,就会触发flush操作,将memtable中的数据落盘到LSM-tree的L0层,形成SST文件。随着L0层的SST文件数量增加,会触发后台compaction操作,来维持LSM-tree的形状。总体而言,越新的数据通常处于LSM-tree的上层,越老的数据,通过compaction不断往LSM-tree的下层沉积。
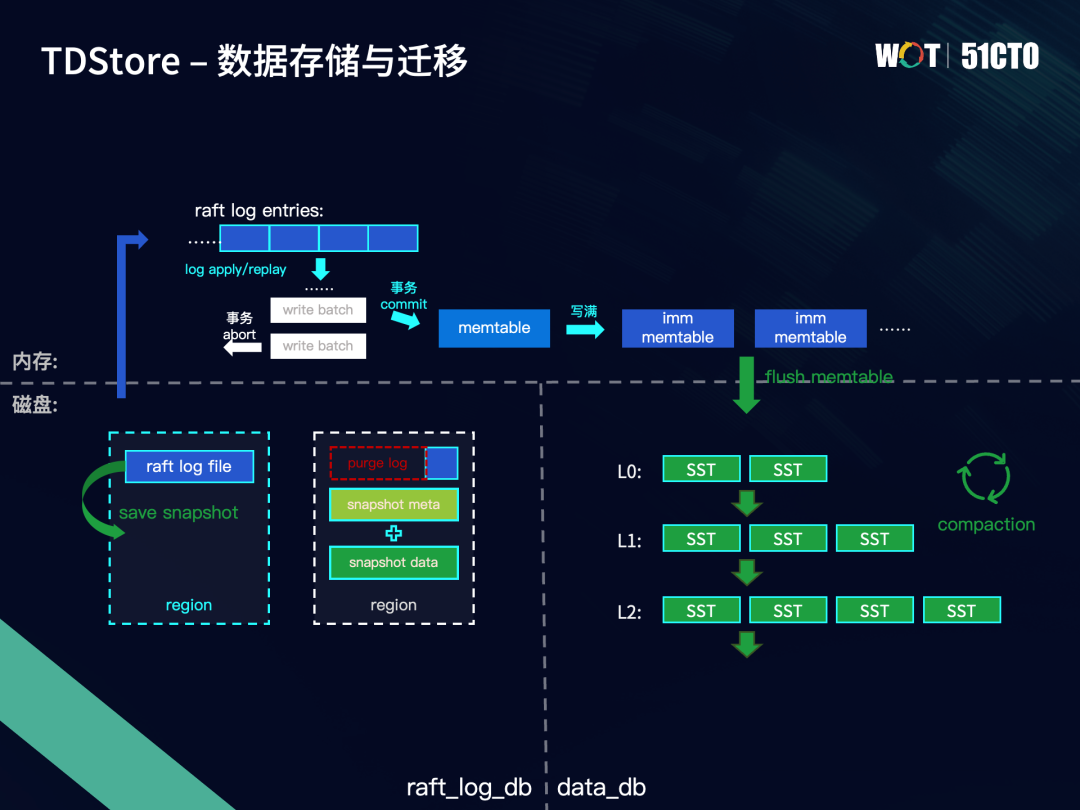
无论是Raft log file还是SST文件,都不应该允许数据的无限增长,需要对过期数据进行及时清理。对于Raft log file中持久化的log entry数据,通过save snapshot即生成快照的形式进行清理。
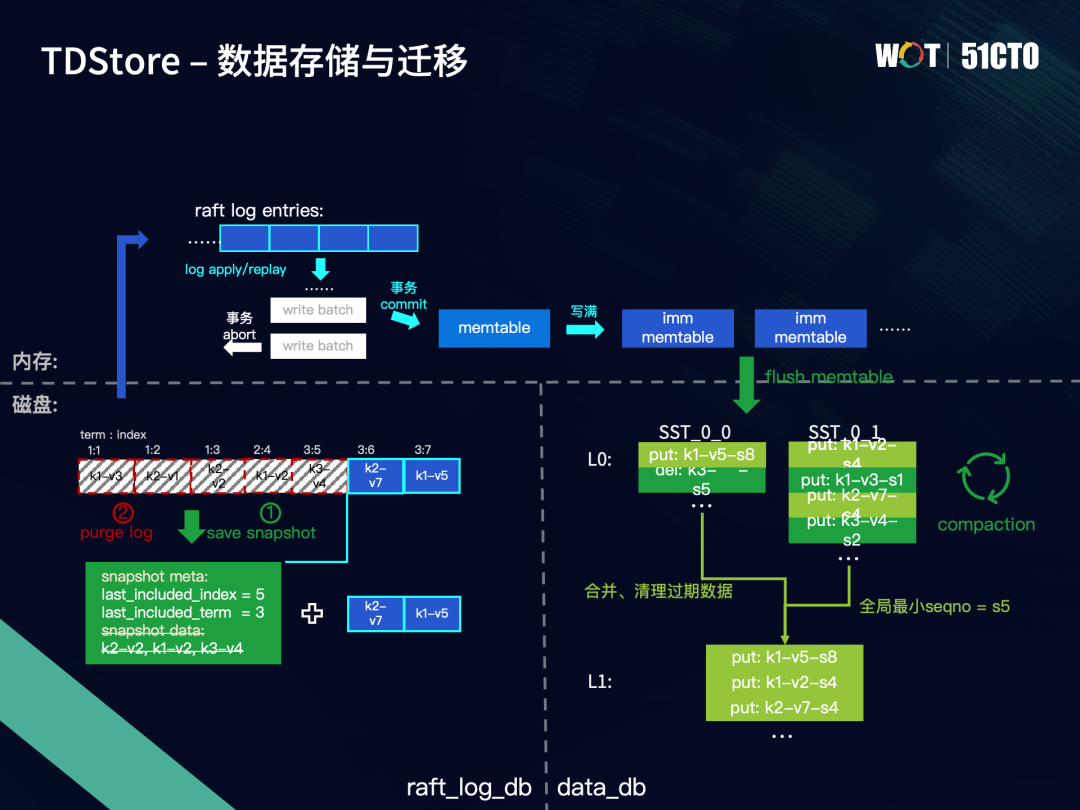
一个snapshot由原数据和状态机存储数据构成。当一个snapshot生成以后,它所覆盖到的Raft log entry都可以被安全地清理掉。当发生重启时,如果发现已存在snapshot,会先加载该snapshot,再去回放剩余的Raft log,避免每次都从头回放所有Raft log。
对于Rocksdb磁盘中的数据,会通过compaction操作来合并和清理过期版本数据。整个集群会维护一个全局最小seqno,在compaction过程中,对于早于全局最小seqno的数据,仅需要保留最新的一条。下图右边的例子中,L0的两个SST合并到L1,全局最小seqno=s5,因此SST_0_1中的put: k1-v2-s4和put: k1-v3-s1,只需要保留s4这条。
我们可以发现,一个Region中的持久化数据由三部分组成,分别位于Raft log db、snapshot data和data_db中的SST文件。其中Raft log和snapshot data两者是互补的关系,因为Raft log file中的部分log entry被存到snapshot data中,所以这部分log entry可以从Raft log db删除。SST中则保存了Region所有通过flush memtable落盘的数据,这意味着SST与snapshot data中的数据存在重复。
为此,我们想到了可以用flush memtable作为save snapshot的触发点。当memtable中所包含的Raft log中的数据落盘到SST时,进行一次save snapshot。这次save snapshot只写一个snapshot meta,即包含了snapshot位点元信息,但不再生成snapshot data,因为该snapshot data中的数据已经随着flush memtable存储在SST中。这样就可以节省掉生成snapshot data的开销,让save snapshot过程变得轻量。
下面介绍数据是如何以Region为单位在不同的TDStore之间进行迁移。下图是一个基于快照传输和装载的Region数据迁移的流程。
第一步:Raft协议触发由Leader发向Follower的Install Snapshot RPC,告知Follower所需同步的下一条Raft log在Leader上已被清理,因此需要开启install snapshot流程。
第二步:Follower在接收到install snapshot RPC请求后,向Leader发送一条download snasphot data的RPC,用于向Leader请求Region的snapshot data。
第三步:Leader会在LSM-tree中找到该Region的范围对应的SST,每个涉及到的SST会生成一个SSTIterator。我们在上层实现一个MergeIterator,将这些来自不同SST但是属于同一个Region中的kv数据进行合并排序,顺序按照key从小到大的顺序,对于相同的user key,seqno更大的即版本更新的排在前面。再通过流式RPC将Region的这些kv数据按顺序发送到Follower上。Follower接收到数据后,按照顺序写入到external SST中,每写满一个就会开启一个新的SST。
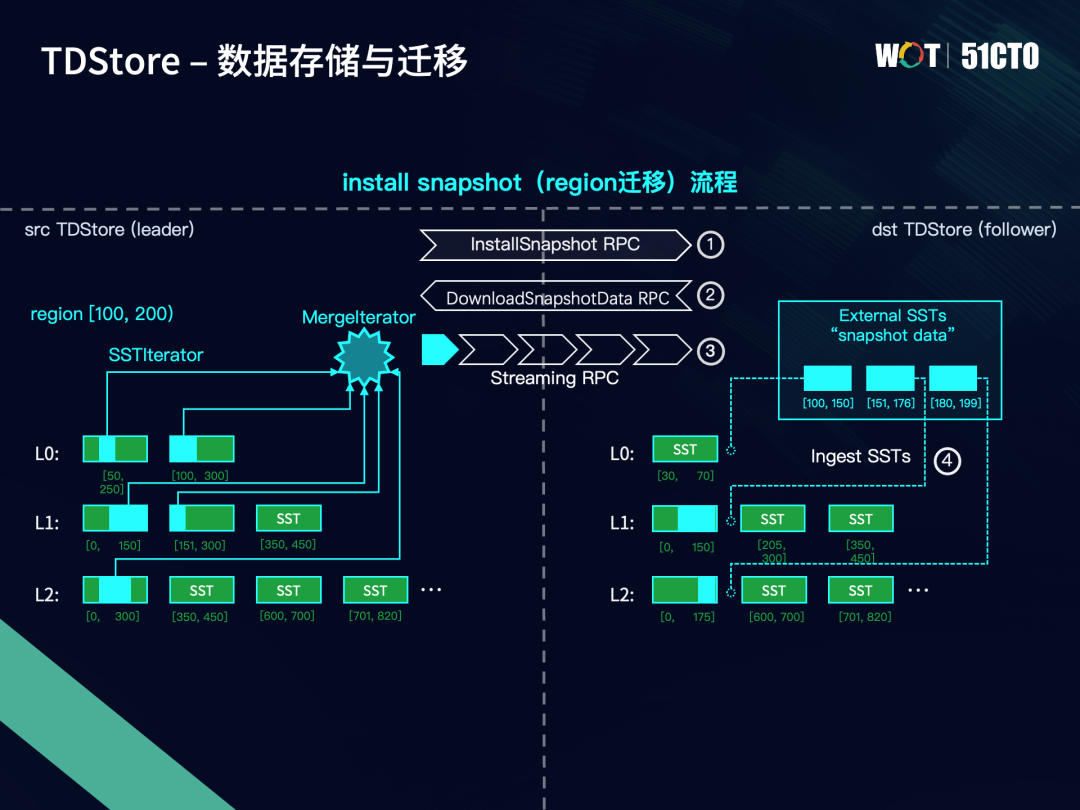
第四步:Follower将这些extrenal SST注入到LSM-tree中合适的位置。合适位置指的是在不与已有SST发生范围重叠的前提下,尽量往下面的层去放。例如图中的第二个external SST,它的范围是151到176,与L0层、L1层的SST都不重叠,但是与L2层的0到175这个SST发生重叠,我们就会把它放在L1层。原因是为了让isnstall snapshot迁移过来的kv数据可以覆盖掉其残存的数据,从而保证被访问到的数据版本是最新的。这就是数据层面迁移的全流程。
总结与未来规划
下一阶段,TDSQL新引擎TDStore将会实现以下三方面特性:
- 数据地理位置感知,进一步降低分布式事务比例,从而使性能进一步提升。
- 对等架构,将计算模块和存储模块做对等架构的设计和一定程度上的重构,主要是为了适用于公有云上的小规模集群,达到更高的资源利用率。
- 管控模块实现更加智能化的负载均衡调度策略。
作为领先的国产分布式数据库,TDSQL致力于将数据库打造成一种服务,用户随取随用,把简单留给用户,把复杂留给自己。未来,TDSQL将持续推动技术创新,释放领先技术红利,继续推动国产数据库的技术创新与发展,帮助更多行业客户实现数据库国产化替换。
﹀
﹀
﹀
-- 更多精彩 --


↓↓点击阅读原文,了解更多优惠





