



引言:Apache Flink 作为流计算引擎,需要持续从上游接收数据流,并向下游输出最新的计算结果。Connector 起到承上启下的作用:Source 负责与上游的 MQ、数据库等源表对接,Sink 则写入各类数据库、数仓、数据湖等目的表。因此,Connector 是 Flink 连接外部生态的桥梁,也是影响作业吞吐量的重要因素之一。
Flink CDC Connectors 作为 Flink 生态的当红明星,切切实实的抓住了实时数据同步(ETL)的痛点,因此广受欢迎。自从 2.0 新版发布以来,它通过并行化无锁算法、更多数据库支持、不阻塞快照等新特性,赢得了更多用户的青睐。
然而它相对来说还是比较新的项目,因此也有着各类大大小小的 Bug 和功能不全等问题。这里我们列举一些常见的问题和解决方案。
JobManager 分片策略优化
减少 70% 内存占用
问题背景
旧版 Flink 的 Source 数据读取是完全由各个 TaskManager 独立完成的,彼此之间没有任何协调和通知机制。这带来了一些问题:每一种 Source 都需要自行实现数据分片和读取逻辑,重复代码多,功能耦合在一起;在繁忙时,快照锁的获取也较为困难,甚至可能出现长期阻塞的情况;流模式、批模式的逻辑不同,需要分别实现等等。
Flink 1.11 及之后的版本,提供了 FLIP-27 提案里描述的新版 Source API,它力求解决上述的各项问题,详情可阅读我们的 这篇文章。
这种新的 API 把分区发现和数据分片的任务由 TaskManager 的职责改到了 JobManager,因此又带来了一些问题:之前 JobManager 只负责全局调度工作,内存开销非常小。现在需要保存各种 Source Connector 的分片信息,因此对于数据量很大的源表,CPU 和内存占用会飙升,甚至出现 OOM(堆内存溢出)问题。
例如我们需要同步几十亿级别的数据表,每个 MySQL 数据分片 8192 条数据,那么内存里需要保存约数十万个 chunk 信息,这可能需要 GB 级的内存来存储。有的读者可能会问:那如果我们把分片改大,例如每个分片 10 万条数据行不行呢?这种做法固然会减少分片数,让 JobManager 大幅减轻负担,但是代价是 TaskManager 处理每个分片的数据量剧增,导致更容易 OOM,同样影响作业的稳定性。
方案描述
我们通过导出 MySQL CDC Connectors 在 JobManager 进程的内存占用,发现 SnapshotSplitAssigner 占用了大量的内存,它保存的是全量快照阶段的分片信息,而具体划分逻辑由 MySqlChunkSplitter 负责执行。
通过细致分析,我们发现它里面存储了很多冗余的信息,例如不必要每个分片都保存各类元数据信息。同时我们还发现,分片的划分不一定非要一次性完成,我们完全可以运行时动态计算 Split 信息,免去大量的内存占用开销。
顺着这个思路,我们完成了 JobManager 分片划分策略的优化。经过对比,在上述几十亿数据同步的场景下,JobManager 堆内存占用减少了约 70%,为客户大幅降本,也赢得了美誉。
同 MySQL 实例多库表连接复用
大幅减少连接数
问题背景
开源版的 MySQL CDC Connector 在 SQL 模式下,每同步一张表,都需要建立一条完整的链路,这也代表着一个对上游数据库的 Binlog Reader,作业的运行图类似下图:

开源 Flink 未复用的运行图
虽然我们可以通过正则匹配的方式来一次同步多张 Schema 相同的表,但是实际场景下,往往每个 Table 的 Schema 都不同,而且可能分布在多个 Database 中,因此仍然需要很多连接。
如果我们有 10 个库,100 张不同 Schema 的表要同步,那么每个 Flink 作业都需要对上游数据库新建 1000 个 Binlog 连接,这会造成严重的性能问题,因此亟需优化。
方案描述
我们设计了一个通用的 Source 消费算子,它可以处理任意 Schema 的数据,而不仅限于单个表。当全量、增量阶段的 Debezium 数据流过时,会被它原样转发,同时加上所属的 database、schema、table 等元数据信息。然后在它的下游设计一个 Filter 算子,根据每个库、表的元数据做分发,最后通过一个 UDTF(Correlate)算子做解包,如下图:
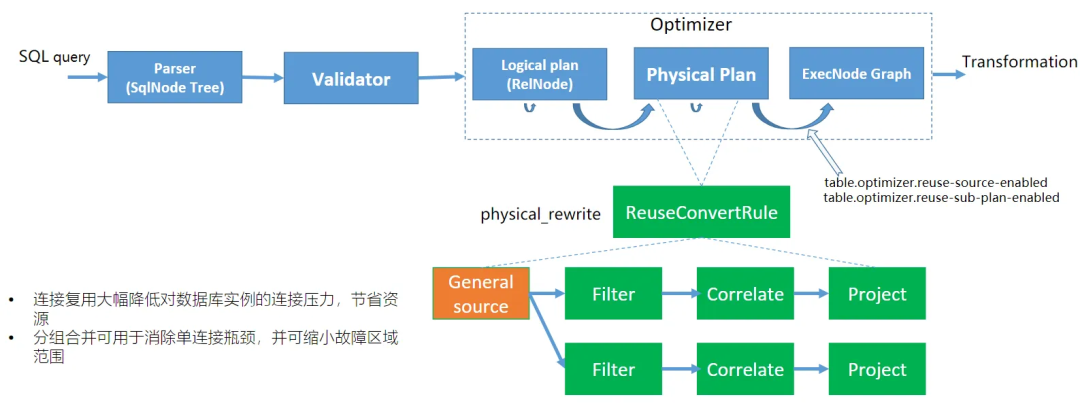
Oceanus 连接复用后的运行图
由于市场上其他厂商也提供了类似的能力,我们通过性能测试和对比,性能(CPU、内存、吞吐量)和友商持平甚至稍优。因此也得到了很多客户的认可和采纳,大幅降低了对上游数据库的压力。
全量转增量 Binlog 追赶速度优化
问题背景
在同步超大数据量的 MySQL 表(上万个分片)时,我们还遇到了全量阶段结束后,有 1 小时以上的空档期,随后才进入完整的增量阶段。从监控数据上来看,这段时间完全没有任何数据输出,但是 Flink 作业运行一切正常,让用户非常困惑。
经过细致分析,我们发现这段“空档期”实际上是也是在消费 Binlog,只是这部分 Binlog 已经出现在之前的全量部分,因此都被丢弃了。
方案描述
我们对这个特殊阶段的 CPU 时间片进行采样,发现时间片主要耗费对每条 Binlog 数据,遍历所有分片,检查这条记录是否位于全量阶段结束之后。
既然瓶颈在这里,我们也对其算法做了优化,通过利用局部有序性的原理,采用二分的方式查找边界,将时间复杂度从 O(N) 优化到 O(logN),后续观察到,该阶段耗时减少了 80%.
增量数据同步性能优化
问题背景
当 MySQL CDC Source 进入纯增量阶段后,仍然可能会遇到性能瓶颈:由于 Binlog 读取是单线程的,如果遇到大表消费慢的场景,并不能简单通过扩容并行度来解决。然而我们也在实际场景中,遇到过较为严重的数据积压现象,这就要求我们进一步优化 Binlog 增量消费阶段的吞吐量。
同样地,通过性能剖析,我们发现增量阶段的性能瓶颈,主要集中在对 Binlog 位点的比较上。在开源的 Flink 版本中,每条 Binlog 数据都需要比较,非常消耗 CPU 资源。
方案描述
我们观察到,每个表只会经历一次全量同步过程,那么完全可以在进入增量阶段后,在内存中保持一个标志。每次 Binlog 到来时,通过对比这个标志,来判断是否进行位点比较。这样就可以大幅提升性能。
通过实际测试,性能最高可以提升到原来的 4 倍。我们已经将这个特性回馈到开源社区,新版的 CDC Connector 自带该优化。
总结与预告
本文从运行图优化、JobManager 内存优化、TaskManager CPU 执行效率优化等几个维度,讲解了腾讯云 Oceanus 对 MySQL CDC Connector 做的一些核心优化点。
当然,我们所做的优化远远不止这几个点,还包括但不限于对 CI Collation 的 VARCHAR 主键的数据表分片倾斜问题修复、整库同步(CDAS)语法支持、TDSQL-C HA 模式适配等等。
此外,我们在 ClickHouse、Elasticsearch 等常用 Sink 上也做了很多优化工作,后面会有更多文章来介绍,敬请期待!
关注腾讯云大数据公众号
邀您探索数据的无限可能

点击“阅读原文”,了解相关产品最新动态
↓↓↓





